

基于深度学习的人脸识别系统——实践篇
1. 人脸识别系统的模型训练
1.1 训练数据的准备和预处理
众所周知,深度学习在这几年里可以突然迅猛地发展起来,有很大一方面原因就是来源于信息时代数据的不断增加,因此,训练数据的好坏对于模型最后的效果起着至关重要的作用。训练数据的准备和预处理主要包括两个过程,第一是根据 YOLOv3 的标签(Label) 格式制作标签(Label),第二是对已经制作好标签(Label) 的图片进行多维度的数据增强处理。
1.1.1制作 YOLOv3 的标签
YOLOv3 的标签(Label) 格式:首先YOLOv3 的所有标签(Label) 文件均为与图片名相同的txt 文件,且与所有图片文件位于同一目录中,而 txt 文件中每一行则代表一个目标框 (Ground Truth) 的标签 (Label),如图1 - 1所示,其中每行的第一个数据代表的是类别(Class) 在Class.txt 的索引,第二个数据代表的则是目标框 (Ground Truth) 的中心坐标x,第三个数据则是目标框 (Ground Truth) 的中心坐标 y,第四个数据为目标框 (Ground Truth) 的宽度 (Width),第五个数据为目标框 (Ground Truth) 的高度 (Height),需要注意的是每个数据皆以空格进行分隔,且第二到第五个数据均为以图像真实尺寸进行归一化后的结果。

图 1 - 1 YOLOv3 标签(Label) 格式
以上格式在实际的制作过程中其实是可以不用了解的,实际的制作其实是借用了github 上有着 14.5k star 的开源项目——labelImg 来完成的。但是通过 labelImg 来制作YOLOv3 的标签 (Label) 在实际的操作过程中却有着一致命的问题:程序在退出之后再打开无法自动重新加载原来标签 (Label) 的类别 (Class) 信息,这使得标注的整个过程只能一次性完成,而如果分多次标注的话标签 (Label) 的类别 (Class) 索引就会不一致,进而无法使用。为了解决这个问题,在反复阅读源代码后发现其实只要加入这么一段代码便可将其解决。
1 if os.path.exists("classes.txt"): 2 with open("classes.txt", "r") as f: 3 data = f.read() 4 label_hist = data.split('\n') 5 label_hist.remove('')
1.1.2 数据增强
数据集的数量一般都是以“万”来作为单位的,但是大多的公开数据集其实是通过网友或一个机构的力量一起齐心协力来完成的,而如果仅是由一个人来完成的话工作量无疑是巨大的,也是不现实的。那么对于自己制作的数据集来说,有什么办法可以快速地增加数据集的数量呢,这就不得不提到数据增强了。数据增强其实指的就是通过计算机图像处理进行自动的尺寸变换,亮度调整,对比度调整等一系列操作,最终让模型可以更好地适应不同尺寸条件或亮度条件等各种复杂条件下的预测任务。
在不使用数据增强的情况下对模型进行训练后发现,模型对于特定距离下和特定亮度下的目标预测较为准确,但是在距离和亮度发生变化后,模型的预测能力显得有所不足,也就是说模型在这两方面的泛化能力还有待提高。因此,此次设计所进行的数据增强主要是放在了这两方面,而距离反映在图像上其实就是目标的大小,距离越近,目标自然也就越大;距离越远,目标自然也就越小,所以可以通过图像的缩放最终实现模拟不同距离下的目标预测。
此次设计所进行的数据增强的流程大致如下:首先,将图像缩放至原来的 0.68 倍, 但是为了保证不改变输入图像的大小,画布仍采用原来的画布,图像的其他区域用黑色(0, 0, 0) 来进行填充,如图1 - 2所示,然后再将该缩放后的图像平移至四个角落,每个角落各保存一张图片,标签 (Label) 文件也进行相同的操作,至此针对不同距离的数据增强就已经结束了,之后是针对不同光线的数据增强。针对不同光线的数据增强相比于针对不同距离的数据增强因为不需要对标签 (Label) 进行修改所以相对来说较为简单,只需要调用 Pillow 的 ImageEnhance 模块来完成即可,此次设计选择了对上一个阶段的所有图片都进行增强因子为 0.5 和 1.5 的亮度 (Brightness) 增强和对比度 (Contrast) 增强。所以最终当数据增强结束后,原本的一张图片则变为了新的 16 = 4 × 4 张图片,而原本准备的仅具有 500 张图片的数据集经过此番操作之后也顺利扩展到了一个具有 9000 张图片的较大数据集。

图 1 - 2 数据增强示例(已经过模糊处理)
1.2 基于 Darknet 框架的模型训练
使用 Darknet 的框架进行训练可大致分为如下几步:
- 首先要安装 Linux 系统,并在 github 上下载 Darknet 的源代码,使用 make 命令进行编译,编译成功后那么第一步算是完成了;
- 接下来要下载预训练模型 darknet53.conv.74;
- 之后需要复制原有的 yolov3.cfg 作为自己的 .cfg 网络描述文件, 并修改该文件中的批处理参数 (batch), 图像输入尺寸参数 (width & height), yolo 层的类别参数(classes), yolo 层前的卷积层的卷积核数量参数 (filters), 其中卷积核数量参数应为filters= (classes + 5) × 3;
- 接着再创建一个 .data 的数据文件,如图1 - 3所示,其中包括了类别数量,存储所有训练图片路径的文件,存储所有验证图片的路径,所有类别的名称以及模型最后要存储的位置;
- 最后在 Darknet 的主目录里执行以下这行命令即可:./darknet detector train data/- face.data cfg/yolov4-face.cfg darknet53.conv.74,其中train 之后的第一个参数为数据文件, 第二个参数为网络描述文件,第三个参数为预训练模型文件。如果成功运行的话会在屏幕上呈现如下界面,如图1 - 4所示,在该界面中我们可以很直观地观察到当前平均损失值 (avg loss) 的变化情况,一般来说当平均损失值 (avg loss) 小于 0.1 时那么训练应该也就可以终止了。

图 1 - 3 YOLOv3 的数据文件
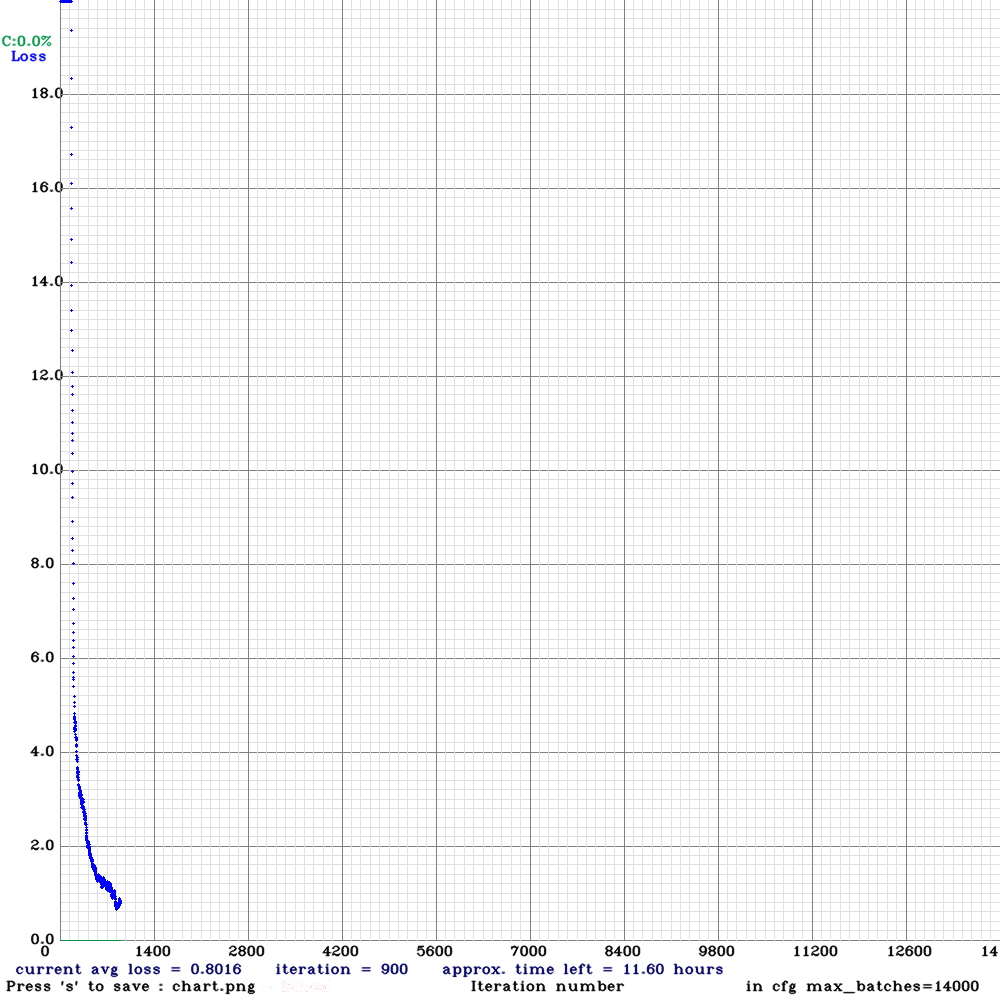
图 1 - 4 YOLOv3 的训练记录
2. 人脸识别系统的设计
本次设计的人脸识别系统主要分为两大部分,一个是负责采集数据并显示最终结果的上位机,另一个则是利用深度学习对数据进行实时处理的服务器主机。其中上位机程序只要是在 Windows 操作系统上即可运行,对硬件没有任何要求,而服务器主机程序则必须运行在一台搭载了英伟达显卡的 Linux 操作系统上运行,本次设计所采用的服务器主机搭载的是 GTX 1050Ti 的显卡,操作系统则采用 Ubuntu 18.04。
2.1 上位机与服务器主机间的通信
本次设计打算采用 TCP 协议通过网络的方法实现上位机与服务器主机的通信,因此需要自定义一个大家共同遵循的通信协议。同时由于 TCP 协议采用的是流数据的传输方式,因此还需要在原有的函数上进行一定的封装,以实现将接收回来的数据准确地解析出来,而不至于出现“粘包”的情况。
2.1.1 TCP 通信协议与数据解析
设置 TCP 通信协议主要是为了解决“接收结果的目标数量未知”和“发送图像的尺寸大小可变”这两大问题。因此,如图2 - 1所示,在正式发送图像的矩阵信息之前,应该要先发送一个“帧配置段”的信息用于告知服务器主机所需要接收的数据长度;而同样的,如图2 - 2所示,服务器主机在返回目标信息之前也需要先发送一个“帧配置段”的信息用于告知上位机所需要接收的数据长度。
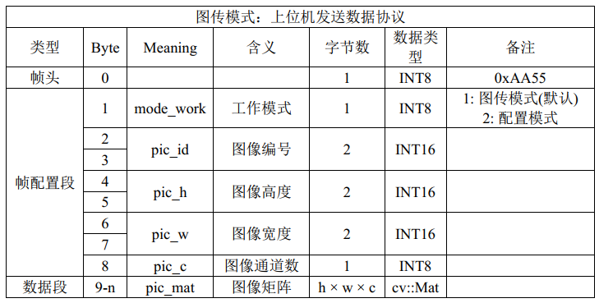
图 2 - 1 上位机发送协议
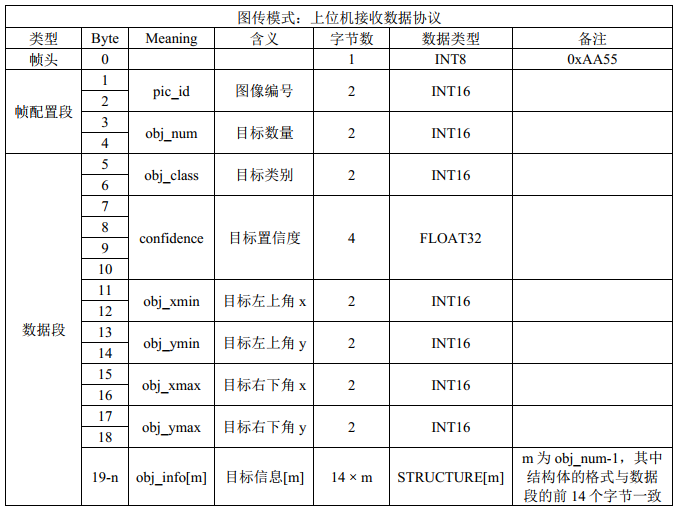
图 2 - 2 上位机接收协议
完成通信协议的定义之后,接下来便是要解决数据解析的问题。如下程序所示为上位机在接收服务器主机返回数据时所进行的数据解析工作,主要是分了两个部分,第一部分为接收“帧配置段”的信息以得到该帧信息所对应的总的数据长度;第二部分则是根据第一部分的信息完成剩余信息的接收并同时将所接受到的数据转换为相应的数据类型并保存至相应的变量中。

1 int recv_state; 2 //接收0:head 3 byte[] buff_head = new byte[4]; 4 recv_state = recv_size(TcpSocket, buff_head, 4); 5 if (recv_state == -1) break; //应关闭线程 6 //解析0:head 7 int pic_id = buff_head[0] + (buff_head[1] << 8); 8 int box_num = buff_head[2] + (buff_head[3] << 8); 9 //接收1:body 10 byte[] buff = new byte[10 * box_num]; 11 recv_state = recv_size(TcpSocket, buff, 10 * box_num); 12 if (recv_state == -1) break; //应关闭线程 13 //解析1:body 14 Box[] box = new Box[box_num]; 15 for (int i = 0; i < box_num; i++) 16 { 17 box[i].classes = buff[10 * i] + (buff[10 * i + 1] << 8); 18 box[i].rect = Rectangle.FromLTRB( 19 buff[10 * i + 2] + (buff[10 * i + 3] << 8), 20 buff[10 * i + 4] + (buff[10 * i + 5] << 8), 21 buff[10 * i + 6] + (buff[10 * i + 7] << 8), 22 buff[10 * i + 8] + (buff[10 * i + 9] << 8)); 23 }
2.1.2 内网穿透的原理与实现
除此之外,由于在非同一局域网下的 TCP 网络通信需要对方提供正确的公有 IP 地址才能顺利完成,但一般的计算机只有私有 IP 地址,并没有有效的公有 IP 地址,因此便需要通过内网穿透,也即是 NAT (Network Address Translation) 的方法最终实现将某个“公有 IP 地址中的端口”映射至“私有 IP 地址中的端口”上来,进而便能通过该公有 IP 地址间接访问到被映射的计算机。其中公有 IP 地址也叫全局地址,它是由互联网名称与数字地址分配机构 ICANN (The Internet Corporation for Assigned Names and Numbers) 进行分配的,是一个全世界范围内唯一的 32 位标识符;而私有IP 地址也叫内部地址,属于非注册地址,专门供组织机构内部使用,互联网数字分配机构 IANA (The Internet Assigned Numbers Authority) 在 RFC 1918 规范中专门定义了 3 块 IP 地址空间作为私有 IP 地址,分别是:
A 类地址:10.0.0.0 ——— 10.255.255.255
B 类地址:172.16.0.0 ——— 172.31.255.255
C 类地址:192.168.0.0 ——— 192.168.255.255
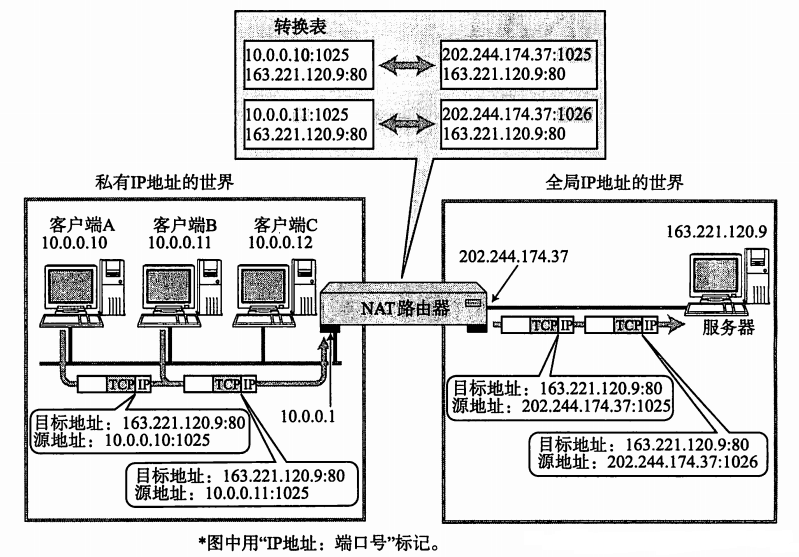
图 2 - 3 NAT路由器
而本次课程设计所使用的内网穿透工具是 NATAPP,NATAPP 是基于 Ngrok 的国内高速内网穿透专业服务商,并独家彻底解决了 Ngrok1.7 内存泄漏问题,所以具有很好的稳定性。首先登陆其官网购买一个 IP 隧道即可得到一个唯一的令牌 (Token),之后再下载其提供的 Linux 客户端,并执行以下命令:./natapp -authtoken=xxxxxxxxxx,其中“xxxxxxxxxx”即为刚才所拿到的令牌 (Token),成功映射后的界面如图2 - 4所示,之后便可以通过访问 server.natappfree.cc:35270 间接地访问到服务器主机的本地回环地址 127.0.0.1 的 6666 端口了。
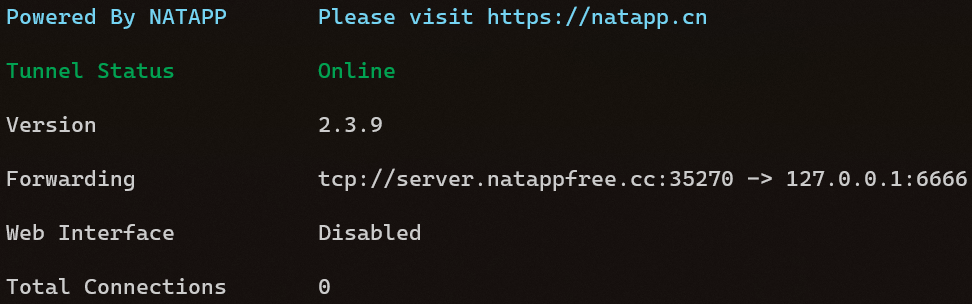
图 2 - 4 NATAPP 成功映射后界面
2.2 上位机的软件设计
上位机在该系统中主要承担了图像采集和显示结果的任务,因此其主要功能有调用计算机摄像头获取图像信息;通过TCP协议将图像信息下发至其他计算机进行相应的处理,并接收其返回的结果;也可以将图像信息直接在本地进行处理;最后将处理后的信息整合至原始图像中,并进行实时的显示。
另外在本次设计的上位机中所用到的主要技术有:
- XML 配置文件的保存。为了方便使用,该系统会相应地添加一些用户可自定义的设置,同时由于这些设置在程序关闭并再次打开后应能被自动加载,因此需要自定义一个配置文件并将其保存在磁盘上。在这里所设置的配置文件采用了XML的文件格式 进行保存,并且利用了 C# 里面提供的 LINQ 技术很方便地完成了这一功能。
- TCP 的异步实现。由于该系统需要涉及到与其他计算机进行相互通讯,因此在这里采用了 TCP 网络通讯的方法来解决,同时,虽然TCP的多线程同步方法也能实现异步的效果,但是TCP的异步调用与之相比起来要有更大的优势,具体会在下面进行详 细介绍。
- 多线程协同工作。由于该系统既要向远程计算机发图像信息,又要接收处理图像信息后的结果,同时还要将结果实时地通过图像的形式显示出来,所以该系统并不能通过简单的单线程来完成所有的工作,而多线程协同工作就能很好地处理这个问题。同时由于涉及到多线程的操作,因此无法避免地会使用到委托,回调函数,同步队列等相 应的跨线程访问机制,以保证数据访问的安全与可靠。
- 本地计算机人脸识别的实现。在远程计算机中,人脸识别主要是通过深度学习实现的, 而在本地计算机中, 人脸识别是通过加载 OpenCV 所提供的级联分类器(Cascade Classifier)以及 Haar 特征人脸检测的方法来实现的。
2.2.1 配置文件
1. 配置文件的修改与保存
在XML中最基本的单元是元素,而在元素中既可以包含一定的属性,又可以包含其他元素(一般称其为子元素)。如下图所示,root 为根元素,ipuConfig 则为父元素, 其下包括了service ip address 等9个子元素,而被标签 <>与关闭标签 </>所括住的即为该元素的内容。在C# 所提供的LINQ 库中,可以很轻松地使用XElement(XName name, object content) 方法来创建一个新的元素,并在每次程序要关闭之前都将该程序中所有与配置相关的全局变量写到一个指定的 XML 文件当中,这样便可轻松实现配置文件的修改与保存。

图 2 - 5 XML 配置文件
2. 配置文件的读取
有了配置文件,接下来便可以在每次初始化界面前进行配置文件的读取操作。同样,在 LINQ 库中通过 Element(XName name).Value 的返回值便能很轻松地获取某个元素中所对应的内容,虽然所得到的返回值都是字符串类型的,但是由于 C# 本身就自带了大量的数据类型间的转换方法,因此很方便地就能将配置文件中的内容进行一一转 换并赋值给程序当中的各个全局变量。
2.2.2 异步网络传输
首先异步处理是相对于同步处理而言的,同步一般来说是要得到返回结果才会往后继续执行的这么一种处理方法;而异步则是发起调用后即可往后继续执行,当任务完成时,再来通知调用者的这么一种处理方法。异步处理一般在 I/O 操作中会经常用到, 与多线程的同步处理方法不同,异步处理并没有专门用于运行某一任务的线程,虽然操作系统还是需要与设备驱动程序进行数据的传输并响应中断,但异步的处理方法让系统无需等待某些 I/O 的调用结束,在同一时段则可以处理更多的工作。
本文在编写 TCP 程序时总共尝试过如下的三种方法:
(1)阻塞性的同步方法:当信号未到来之前会一直呈现成假死的状态。
(2)非阻塞性的同步方法:当信号来了,还要自己去完成随后的相应处理。
(3)异步方法:当信号来了并且随后的相应处理也结束了,才会去通知调用者。
其中的第一种方法是不可取的,因为在实践中发现,第一种方法在需要关闭TCP时根本无法将Socket套接字给释放掉, 而通过对比第二种和第三种方法, 我认为异步TCP的意义大致可以总结为以下三点:
(1)异步操作可以减轻调用者所在线程的运算负担。
(2)对于在信号到来后需要立刻做处理的情况,如果是同步操作,那么只能是新开一个线程来对信号的到来进行反复的轮询,而对于异步操作来说则可以采用硬件中断的方法来避免新开一个线程的资源。
(3)对于同步方法而言,线程间的切换会对系统产生额外的负担,过多的共享变量可能会导致死锁的出现。
2.2.3 多线程任务协同工作
该系统主要涉及到三个线程:1. UI 主线程;2. 捕捉图像并存储于队列中,同时将图像传输到远程计算机上;3. 接收结果并从队列中调取原有图像,整合后实时地显示出来。而最后这两个线程由于均同时操作了同一个图像队列,因此会产生“生产者与消费者问题”,而这个问题则需要用到“同步队列”(互斥锁机制)的方法来加以解决。互斥锁机制是指每个线程在对资源操作前都尝试先加锁,成功加锁才能操作,操作结束后解锁,如果线程在未解锁的情况下,也就是有线程对其进行操作的情况下,其他线程是无法对其进行加锁的。这也就意味着当操作该“同步队列”的线程没有结束操作时,另一方便只能处于等待的状态,而当对方结束操作后,等待方才能进行接下来的操作,这样就能很好地保证该队列数据的可靠与安全了。
除了涉及到“同步队列”的问题外,由于其他两个线程皆需与 UI 主线程有一定的交互,因此还需要用到 C# 所提供的委托与回调函数的机制。在Framework2.0 及以后的版本中,由于微软官方认为多个并发线程对 UI 进行修改时,容易因为线程争用资源而产生死锁,所以 CLR 默认不允许非 UI 的线程修改控件的属性,因此便提供了 Invoke 的方法使所有控件的修改都“委托”给 UI 线程完成,如下是一个最简单的委托与回调的演示:
1 delegate void SetTextCallBack(string text); //定义委托类型 2 SetTextCallBack setCallBack = textBox.AppendText; //声明引用并将其实例化 3 textBox.Invoke(setCallBack, "hello"); //通过回调函数的方法,实现跨线程操作
2.2.4 Haar 特征人脸检测
生成 Haar 特征人脸检测器一般分为如下 4 个步骤:
(1)提取人脸的 haar-like 特征;
(2)每个 haar-like 特征使用类似 cart 的二分类决策树判别区域是否为人脸,每个 haar-like 特征经过判别训练得到判别阈值构成多个最优弱分类器(且挑选了最优的haar-like 特征);
(3)多个弱分类器级联构成强分类器,此步实际是在进行多个弱分类投票进行二
分类的过程;
(4)级联多个强分类器进行人脸检测与分类。
将生成好的检测器进行人脸检测的步骤如下:选取当前滑动窗口对应的图像区域进行检测,把对应的区域放入第一个强分类器,只要强分类器的任意弱分类器判别此区域不含人脸,就结束检测,并滑动窗口至下一区域。若第一个强分类器判别出该部分含有人脸,就会送入下一强分类器进行再检测和分类,如果最后一个强分类器也判别为有人脸,则以窗口作为其中的人脸检测框。
2.3 服务器主机的软件设计
本次设计的服务器主机程序主要是在 YOLO 作者所开发的Darknet 程序上改编而来的,主要是为该程序添加了 TCP 网络传输的功能,使模型网络的输入从 TCP Socket 中获得,并将最终所处理的结果通过 TCP Socket 发送出去。
2.3.1 基于 Darknet 框架的程序改写
运行./darknet detector demo data/face.data cfg/yolov3-face.cfg backup/yolov3-face last.weights -dont show 命令后程序首先会进入到 darknet.c 中的 main 函数,之后在该函数中会匹配所传入的第一个参数 detector,之后程序会调用 detector.c 中的 run detector 函数,在该函数中程序会继续匹配所传入的第二个参数 demo,进而继续调用 demo.c 中的 demo 函数,也即是本次软件设计中最需要关心的函数。
在该函数中首先要进行一些必要的初始化工作,其中包括了读取权重文件,创建一个 TCP Socket 并开启监听模式直至返回一个文件描述符,也即是与某个 Client 客户端成功握手通讯,创建一个接收数据的线程,创建一个处理数据的线程,最后再进入一个死循环当中,该死循环的主要任务是将“处理数据线程”所返回的结果通过TCP Socket 发送至上位机,同时不断地计算当前每秒所处理的帧数 (FPS) 并作为标准输出打印至终端上。
在接收数据的线程中,主要就是利用 TCP Socket 接收从上位机发送而来的 Mat 图像矩阵,但是 Linux 中所自带的 recv 函数在使用过程中是存在问题的,其所接收的字节长度并不一定是传入参数中所设置的长度,因此还需要对该函数进行一定的封装才可继续使用,所封装的函数如下所示,通过 sum recv 对所接收的字节长度进行计数直至其刚好等于我们所需要接收的长度length 才退出循环,返回sum recv。而处理数据的线程则是将接收回来的数据送入 YOLO 网络中进行预测并得到相应的预测结果。
1 int rcvd_from_tcp(int sockfd, unsigned char *data, int length) 2 { 3 if (data == NULL) 4 return 0; 5 int one_recv, sum_recv = 0; 6 while (sum_recv < length) { 7 one_recv = recv(sockfd, data + sum_recv, length - sum_recv, 0); 8 if (one_recv == 0) 9 return 0; 10 sum_recv += one_recv; 11 } 12 return sum_recv; 13 }
3. 人脸识别系统的功能测试与性能分析
这一章是系统设计与实现的最后一步,主要分为功能测试和性能分析两个部分。在这一章里所使用的上位机为 Windows 操作系统,使用的网络为校园网,最高网速可达 2 MB/s;服务器主机则使用 Ubuntu 18.04 操作系统,且搭配着英伟达公司的 GTX 1050Ti 显卡,使用的网络同样为校园网,最高网速可达 2 MB/s。
3.1 功能测试
首先如图3 - 1所示,通过SSH 远程登录到服务器主机并运行程序,程序会自动加载人脸识别的模型并等待上位机进行连接。
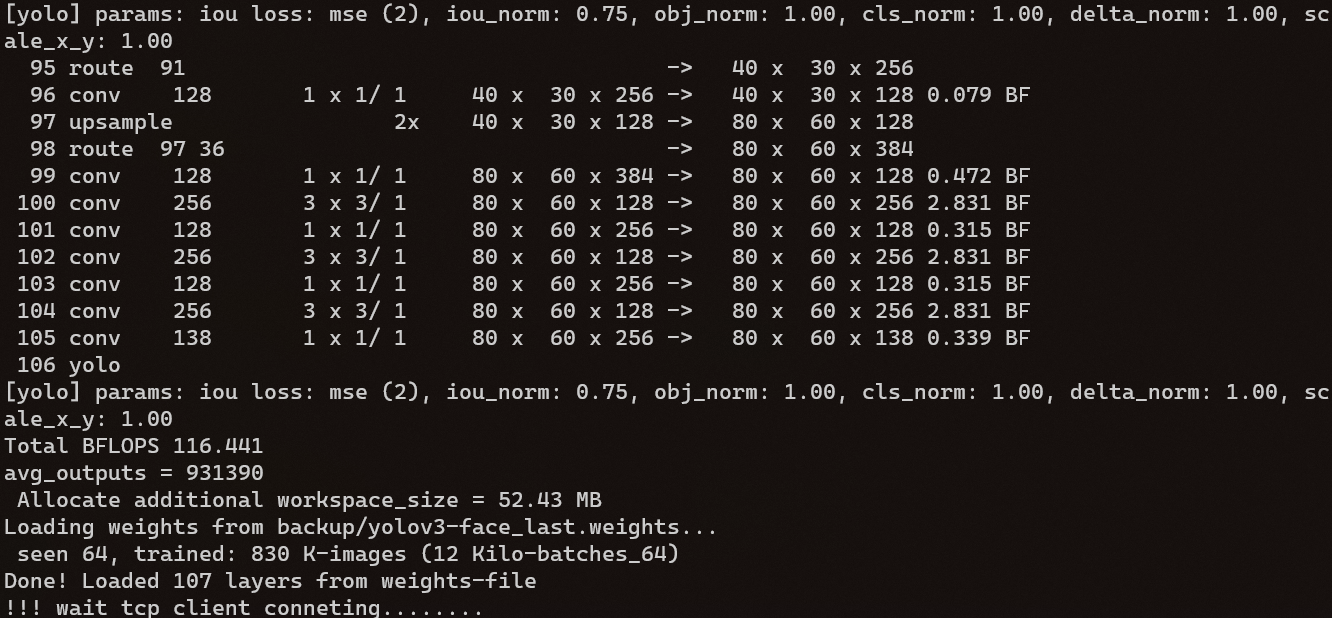
图 3 - 1 服务器主机运行程序
然后如图3 - 2所示,打开上位机并进入到设置界面当中,即可指定服务器的 IP 地址和端口号。
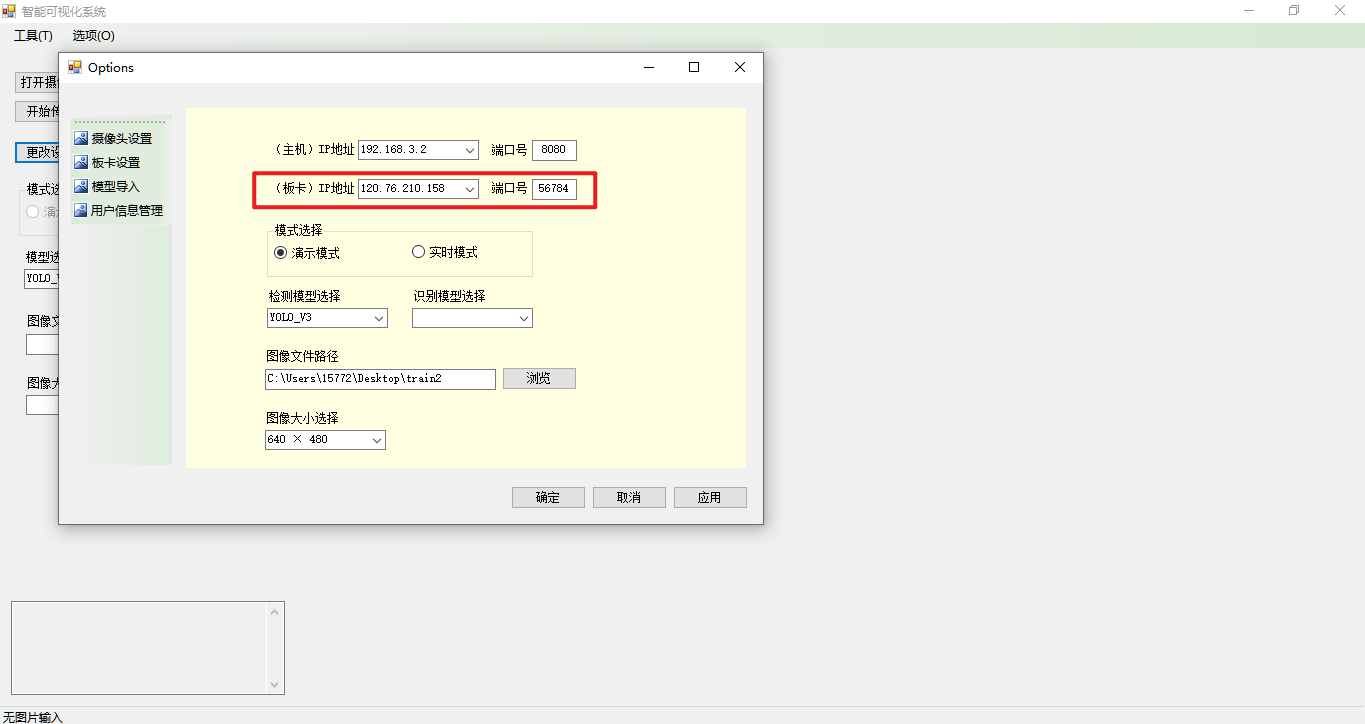
图 3 - 2 上位机设置服务器IP 地址
最后如图3 - 3所示,返回至上位机的主界面并依次点击“打开摄像头”,“连接板卡”,“开始传输”便可以看到最终的演示效果了,而服务器主机的显示结果则如图3 - 4所示,在该远程终端里我们可以看到每一帧图片的预测结果,每个结果所对应的置信度,接收的数据长度,发送的数据长度以及处理的帧率等一系列信息。

图 3 - 3 上位机显示结果(已经过模糊处理)
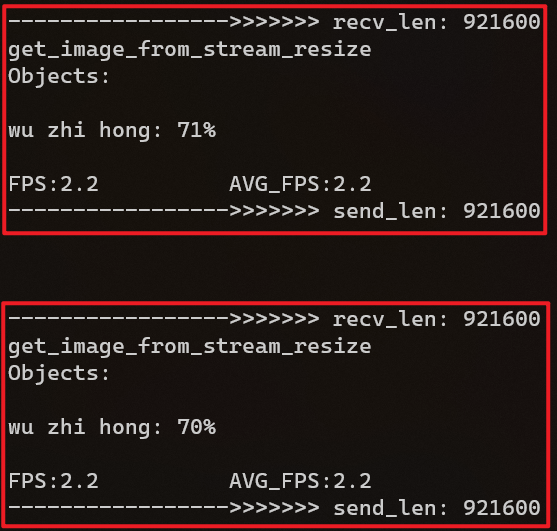
图 3 - 4 服务器主机显示结果
同时如图3 - 3所示,在处理的过程中,可以通过点击“图像捕捉”按钮将所传输回来的结果以图片的形式存储在磁盘中,如图3 - 5即为通过该功能所存储下来的图像。
图 3 - 5 图像捕捉功能(已经过模糊处理)
除此之外,在不打开远程处理的情况下,也就是在不点击“开始传输”按钮的情况下,点击“工具”中的“Start Processing”可进行数据的本地处理,处理的结果如图3 - 6所示,可以看到该结果相比较于服务器主机的处理结果而言并没有那么的精确,但是也是可以满足需求的。

图 3 - 6 上位机本地处理结果(已经过模糊处理)
通过该测试结果可知,该系统已经实现了通过上位机进行图像采集并使用 TCP 协议将采集回来的信息发送到服务器主机当中,服务器主机再通过深度学习完成处理并使用网络将处理结果传输回来,最后在上位机中实时地显示人脸识别的结果这一基本功能。此外该系统还具备了可指定用于远程处理数据的服务器主机的 IP 地址及端口号,可指定用于采集图像信息的摄像头,可指定所传输图像的尺寸,可保存处理完成后的图像结果,同时可直接进行本地图像处理(不依赖于服务器主机进行处理)等多项功能。
3.2 性能分析
在功能测试均没问题的情况下,接下来可以进行性能分析。对于人脸识别这一课题来说,一般需要考虑两方面的性能问题,一是精度,二是速度。
3.2.1 精度性能分析
人脸识别作为目标检测的一个子课题,同样是采用 mAP 的指标来对其精度进行衡量。如图3 - 7所示,这是没有做数据增强前的 mAP 指标,可以看到 mAP 仅为 0.37,而在阈值设置为 0.25 的情况下,查准率 (Precision) 仅为 0.39,召回率 (Recall) 仅为 0.24。后来经过原因分析,认为应该是该模型对于不同距离及不同光线条件下的图片适应能力较差,因此通过对这两项进行着重的数据增强(具体方法在第三章已进行详细说明) 后,再进行性能测试,结果如图3 - 8所示,可以看到 mAP 为 0.43,较之前的 0.37 有了大幅度的提升,同时在阈值设置为 0.25 的情况下,单个类别的查准率 (Precision) 高达 0.97,而召回率 (Recall) 更是可以达到 1 的效果。因此可以确定数据增强对于模型训练起着至关重要的作用,而通过数据增强后训练出来的模型也基本满足了在精度性能上的要求。

图 3 - 7 数据增强前的数据指标
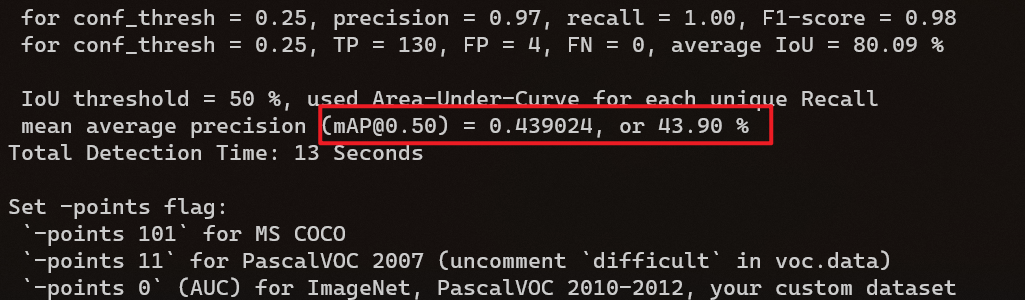
图 3 - 8 数据增强后的数据指标
3.2.2 速度性能分析
对于速度来说,考虑的一个重要指标是帧率 (FPS),即从采集图像到显示图像这整个过程中所耗费时间的倒数,对于视频来讲,为了保证流畅度,使用的帧率通常为 24Hz,也就是说每秒钟要能处理 24 张图片以上才算是一个比较合格的性能。而该系统在使用网络传输的情况下,帧率(FPS) 如图3 - 9所示,仅为 2.2,如果是进行本地处理的话如图3 - 10所示,帧率 (FPS) 则有 12.8。因此网络处理的帧率可以说就是受限于网络传输的速率,而经过计算,如式(1)所示,如果最高网速为 2 MB/s,传输的图片尺寸为640 × 480 × 3,则每秒确实只能传输大概 2.27 张图片,这与实际的情况可以说是高度相符的,因此如果想要提高系统识别的帧率 (FPS),那么就一定要提高所使用网络的网速。
图 3 - 9 网络处理帧率
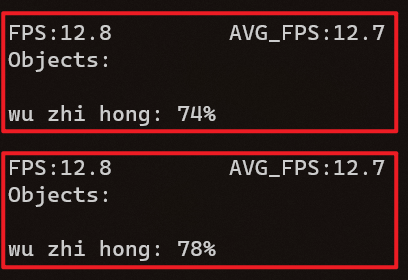
图 3 - 10 本地处理帧率
4. 总结
原理篇首先从深度学习的基本原理出发,并进一步介绍了从 YOLOv1 到 YOLOv3 发展的全过程,全面讲解了 YOLO 模型的核心思想以及目标检测的整个流程,实践篇继而自行创建人脸识别的训练集,并通过Darknet 框架成功完成了对YOLOv3 模型的重训练,至此人脸识别的功能便已经初步实现了。随后,在此基础上又继续开发了一个上位机程序并改写了Darknet 框架的源代码,使之具备了TCP 网络通讯的功能,最终将整个人脸识别系统的功能实现迁移至任何一台计算机上来,也就是说只要计算机可以上网,人脸识别的功能就可以实现,而原本的数据处理工作则交给了服务器主机来完成,这在一定程度上来说提高了整个系统易用性和便捷性。而在这整个过程中本人主要完成了以下工作:
- 修复并解决了标注工具——labelImg 对于 YOLO 格式的标签 (Label) 只能一次性标注的问题。
- 自行编写了可以对图像进行缩放,平移,亮度及对比度变换的数据增强程序。
- 利用 C# 语言自行编写了一套具有读取和保存配置文件功能、可多线程任务协同工作的上位机程序,同时该上位机程序既可选择与服务器主机进行 TCP 通讯,实现基于深度学习的人脸识别功能,又可直接调用本地 OpenCV 所提供的 API 接口实现基于haar-like 特征的人脸识别功能。
- 自行编写了基于 Linux 的 TCP 网络通讯程序,并使用内网穿透的方法使上位机随时随地都能与服务器主机进行通讯,最终再将其移植于原本的 Darknet 源程序中,成功实现了服务器主机远程处理数据并回传结果的功能。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)