
新型冠状病毒数学模型的建立与分析
新型冠状病毒数学模型的建立与分析
本文利用经典的传染病SEIR模型,对最近的这次新冠肺炎进行分析,通过将感染率α近似为指数函数,将康复率γ近似为幂函数,再利用matlab中的fmincon函数求出使得拟合出来的曲线的残差平方和最小时的修正系数λ1和λ2,以及发病率β而完成模型的求解,进而完成对疫情走势的预测,以及完成对提前或延后隔离的模拟。
关键词:新冠肺炎,SEIR模型,fmincon,疫情走势预测,提前或延后隔离的模拟,经济影响
一、问题的重述
1. 引言
冠状病毒是一个大型病毒家族,已知可引起感冒以及中东呼吸综合征(MERS)和严重急性呼吸综合征(SARS)等较严重疾病。新型冠状病毒是以前从未在人体中发现的冠状病毒新毒株,自2019年底以来,世界范围内爆发新型冠状病毒,2020年1月12日将该冠状病毒命名为2019-nCoV。2019-nCoV的爆发和蔓延给全球经济发展和人民生活带来了很大影响。我们从中得到了许多重要的经验和教训,认识到定量地研究传染病的传播规律、为预测和控制传染病蔓延创造条件的重要性。
2. 问题的提出
(1)根据附件提供的数据,对2019-nCoV在中国的传播进行分析;
(2)建立数学模型,对湖北和湖南两地的疫情走势进行预测;特别要说明怎样才能建立一个真正能够预测以及能为预防和控制提供可靠、足够的信息的模型,这样做的困难在哪里?对于卫生疾控部门所采取的措施做出评论,如:提前或延后5天采取严格的隔离封城等措施,对疫情传播所造成的影响做出估计。
二、基本假设与符号说明
1. 基本假设
(1)COVID-19患者治愈恢复后不再被感染。
(2)各类人口的自然死亡可以忽略。
(3)忽略迁徙的影响。
(4)单位时间内感染的人数与现有的感染者成比例。
(5)单位时间内治愈的人数与现有的感染者成比例。
(6)这些比例函数可以是指数函数也可以是幂函数。
(7)由于此次新冠肺炎的死亡率只有4%,远少于另外96%的康复者,因此该模型假设此次疫情不存在死亡人数,死亡人数也被归到康复者中来。
2. 符号说明
|
符号 |
意义 |
|
N |
人口总数 |
|
S |
易感人群 |
|
E |
潜伏期人群 |
|
I |
发病人群 |
|
R |
康复人群 |
|
λ1 |
修正系数,与潜伏者每天平均接触人数成正比 |
|
λ2 |
修正系数,与发病者每天平均接触人数成正比 |
|
α |
传染易感者的系数(感染率) |
|
β |
潜伏者转化为发病者的概率(发病率) |
|
γ |
感染者康复的概率(康复率) |
三、模型的建立与求解
1.模型的建立

根据以上关系,可列出方程组:
$\begin{cases} \frac{dS}{dt}=-\left( \lambda _1\alpha _1E+\lambda _2\alpha _2I \right) \frac{S}{N}\\ \frac{dE}{dt}=\left( \lambda _1\alpha _1E+\lambda _2\alpha _2I \right) \frac{S}{N}-\beta E\\ \frac{dI}{dt}=\beta E-\gamma I\\ \frac{dR}{dt}=\gamma I\\\end{cases}$
2. 模型的求解
(1)首先用以下函数对α进行拟合,如图1。
$y=ae^{-bt}$
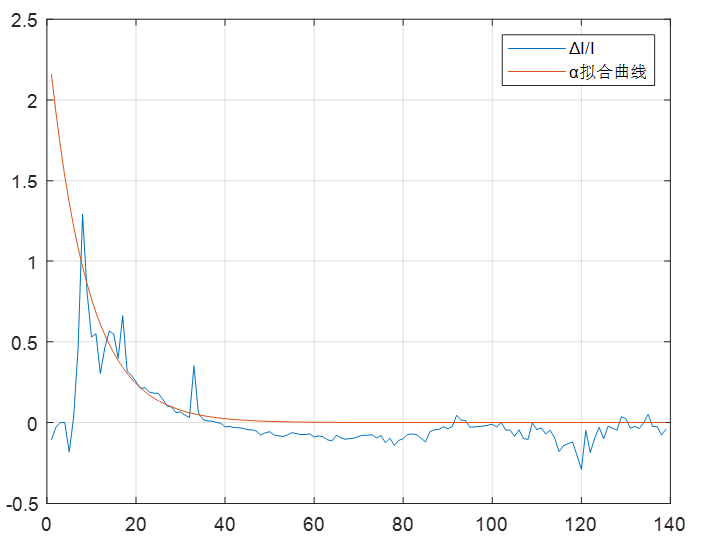
图1
(2)然后用以下函数对γ进行拟合,如图2。
$y=ax^{\frac{1}{b}}$
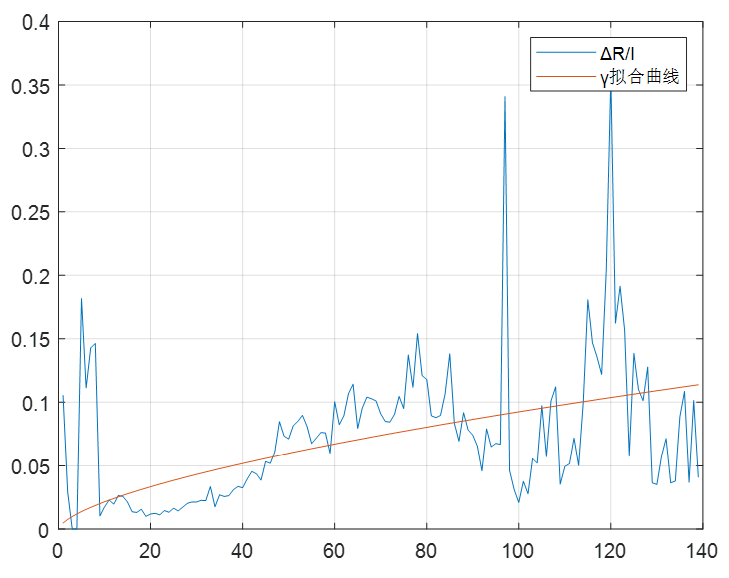
图2
(3)约束条件(限定范围)
查阅相关资料可知,此次新冠肺炎的潜伏期大概是2-14天,而大多确诊情况则是在7天之内发病,于是我们假定这个概率P的取值区间为[0.8,0.98],并认为在潜伏期时每天发病的概率均相同,即$\left( 1-\beta \right) ^7=1-P$,解得β的取值区间大概为[0.2,0.4]。
同时,经过相关的资料和报道可知,此次新冠肺炎之所以难以控制、传播迅速,最主要的原因是存在着大量的无症状感染者,也就是我们模型中的潜伏者E,同时他们的传染性在此次疫情中是与发病者相当的。而对于已经表现症状的发病人群I,由于我们国家已经吸收过了上次SARS的经验,所以这次在一两天的时间内基本上便可以将其大部分隔离开来。因此,基于以上认识,为了简化模型,我们假设潜伏者E对易感者S的感染率α1和发病者I对易感者S的感染率α2只与他们平均每天所接触过的人数相关,因而可以认为α1大概是α2的10倍左右。于是有
$\begin{cases} \alpha =1.1\alpha _1\\ \alpha =11\alpha _2\\\end{cases}\Rightarrow \begin{cases} \alpha _1=\frac{1}{1.1}\alpha _{}\\ \alpha _2=\frac{1}{11}\alpha\\\end{cases}$
因此可以判断修正常数λ1在1附近,修正常数λ2在0.1附近。
(4)用构造目标函数使残差的平方和最小的方法对数据进行拟合
最后解得的结果如下,图形如图3所示。
$\begin{cases} \lambda _1=1.062\\ \lambda _2=0.1\\ \beta =0.4\\\end{cases}$
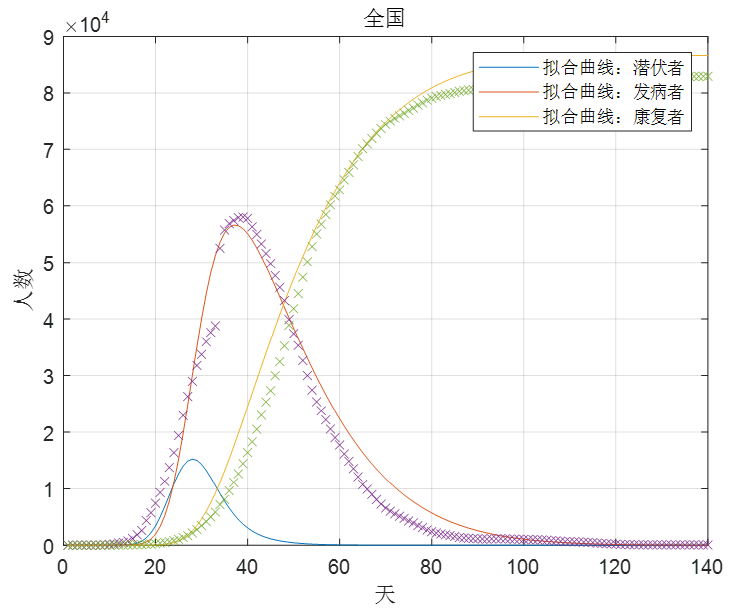
图3
3. 问题一:对2019-nCoV在中国的传播进行分析
结果基本与实际相符合,这就说明了我们此次所建立的模型以及所求得的参数是能说明问题的。而基于以上所求的参数,我们对中国从1月10日至5月30日以来的新冠肺炎疫情发展有以下结论:
- 疫情发展以来,总的感染率α是递减的,也就是说随着新冠肺炎的火速发展,人们的自我保护观念也有了很大的提高,不仅减少了每天与其他人接触的次数,同时出门带口罩也使得感染率α在疫情发展的中后期大幅度下降。
- 总的来说,被新冠病毒感染后的潜伏者发病的概率β也基本不变,由该模型可知,在感染新冠病毒之后大概有95%以上的患者会在7天之内发病,并被确诊出来。
- 而随着疫情的发展,我们可以看到康复率γ也在逐步的上升,并最终稳定于某个值,这可能是由于中医药在其中发挥着作用。
- 此外,在此次对该数据的拟合中我们还发现了,在2月11日之后确诊人数的增幅与以往大有不同,经过相关资料的查询我们了解到,这是由于在2月11日之后增加了临床诊断作为确诊依据的缘故,因此可以认为在2月11日前的数据其实确信度是不高的,其中仍然包含着大量发病者未能纳入到所统计的数据当中。
4. 问题二:预测湖北省与湖南省的疫情走势,并对不同的封城时间进行模拟
(1)预测疫情走势
下面是用2月11日前的数据(也就是跳变点之前的数据)对湖北省的疫情情况进行预测的结果,如图4,可以发现该预测与真实情况相距甚远,原因就在于上文说的"2月11日前的数据确信度不高的问题"。
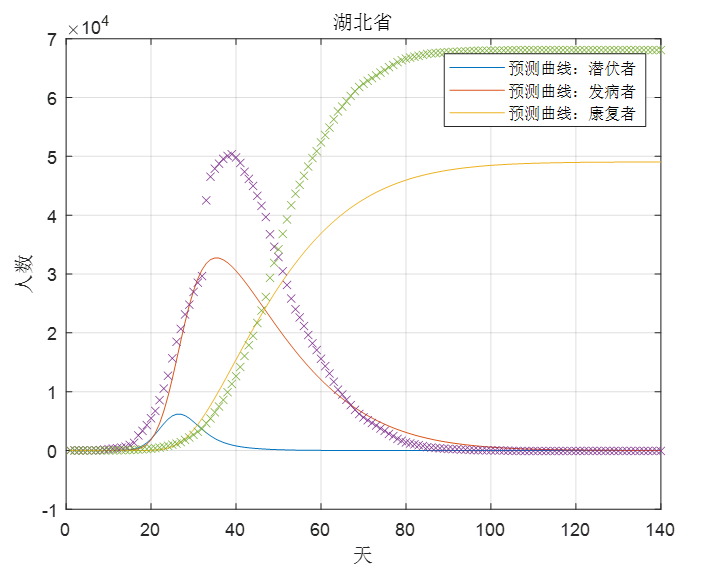
图4
后采用跳变点后与"和康复者曲线交点"前的数据进行预测,如图5,结果发现效果比之前要理想,但与实际情况同样有一定差距,经分析应该是在之后的过程中由于前面已经累积了一定的医学经验,所以在一定程度上显著提高了患者的康复率,使得发病者I在之后的过程中能更快地往下降。
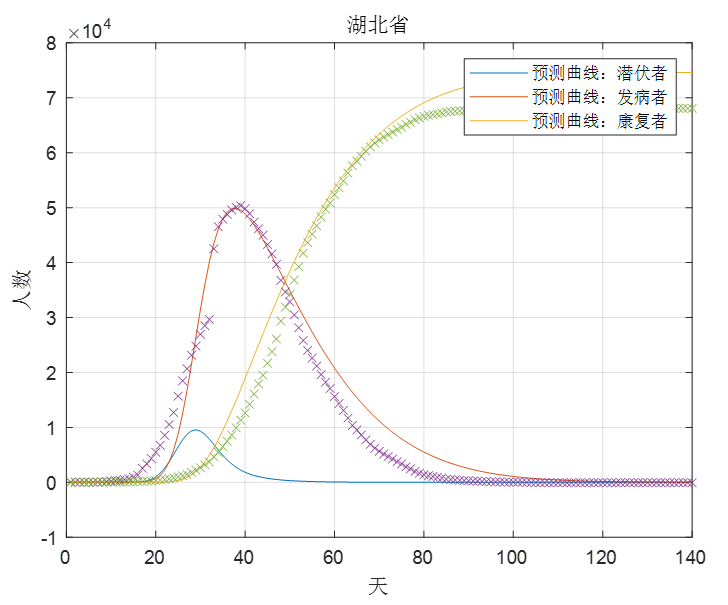
图5
下面用湖南省前25天的数据进行预测,如图6,结果与实际情况较为接近。
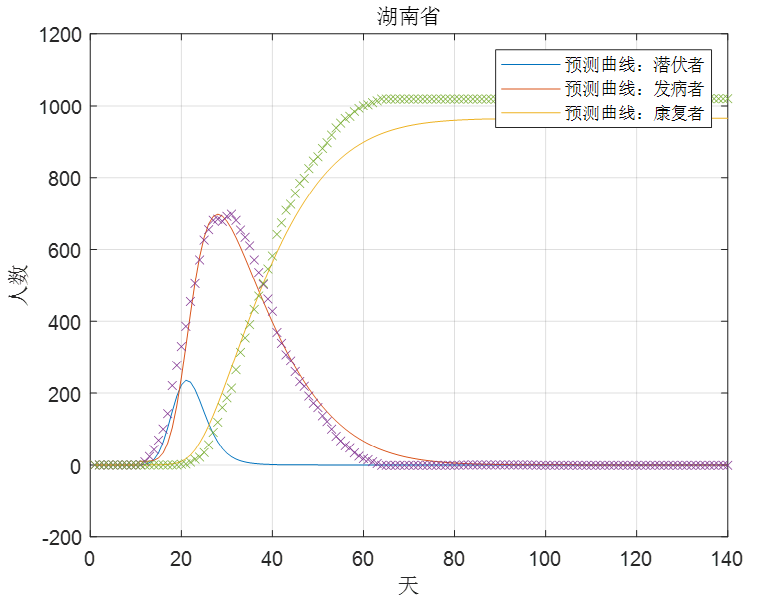
图6
因此基于以上实验,要建立一个真正能够预测以及能为预防和控制提供可靠、足够的信息的模型的难点在于:
- 对确诊病例的统计要精确且有较高确信度。
- 对一些未知的影响有时往往难以通过已知的模型来进行预测,如上文所说的医疗经验导致的康复率的提高,以及某些地区可能出现的超级传播者使感染率一下子大幅度增加等等的这些情况,都会为建立准确、可靠的模型而提供难度。
(2)提前或延后隔离模拟
下面对延后5天采取严格的隔离封城措施进行模拟,通过查阅新闻可知,武汉在1月23日下发封城通告,并于当天上午10时,全市公交、地铁、轮渡、长途客运暂停运营,于是我们就以1月23日为基准模拟往后推迟5天进行严格隔离封城的情况。首先我们假设平常情况下人们平均每天接触10个人,而如果在1月23日打后的5天内由于春节的缘故同时政府又没有进行严格的封城措施,人们平均每天多接触5个人,即
$\alpha _1=\frac{10+5}{10}\alpha _1$
经过5天之后,α1再恢复原来的水平,则以下是湖北和湖南的情况对比,如图7,图8。
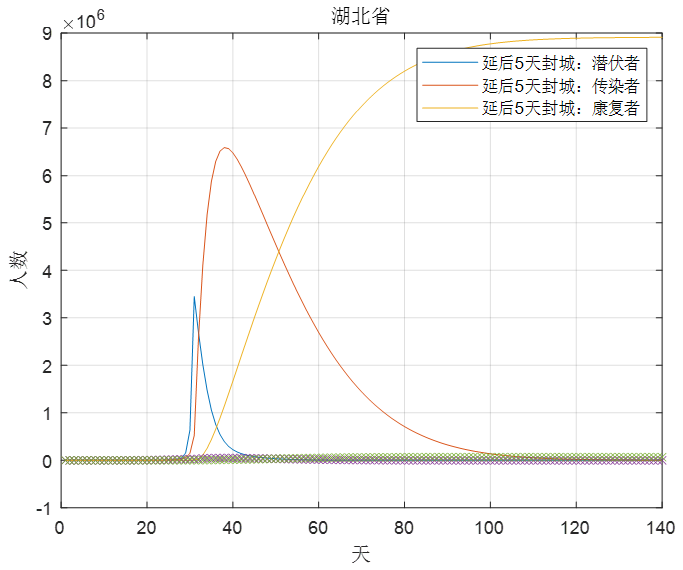
图7
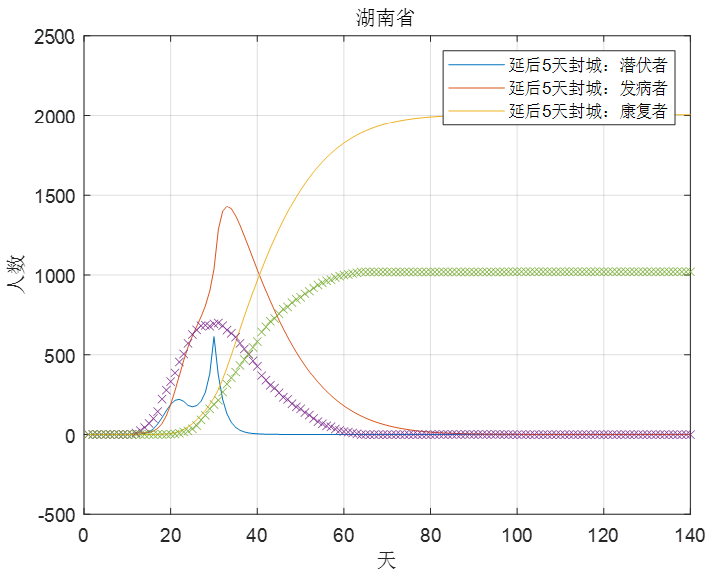
图8
可以看到的是如果延后5天封城,湖北最终的发病人数峰值会达到600万以上,是之前发病人数峰值5万的100倍以上,而湖南的情况则要相对好得多发病人数峰值仅是原来的2倍左右,但同时可以看到的是疫情的最终基本消退也要从原来的60天滞后到80天,虽然仅是延后5天封城,但疫情却会多持续20天左右。
下面对提前5天采取严格的隔离封城措施进行模拟,同理假设在1月23日封城前,平常情况下人们平均每天接触15个人,而如果在1月18日即进行严格的封城措施,则人们在1月17日到1月22日平均每天少接触5个人,即
$\alpha _1=\frac{15-5}{15}\alpha _1$
经过5天之后,α1再恢复原来的水平,则以下是湖北和湖南的情况对比,如图9,图10。
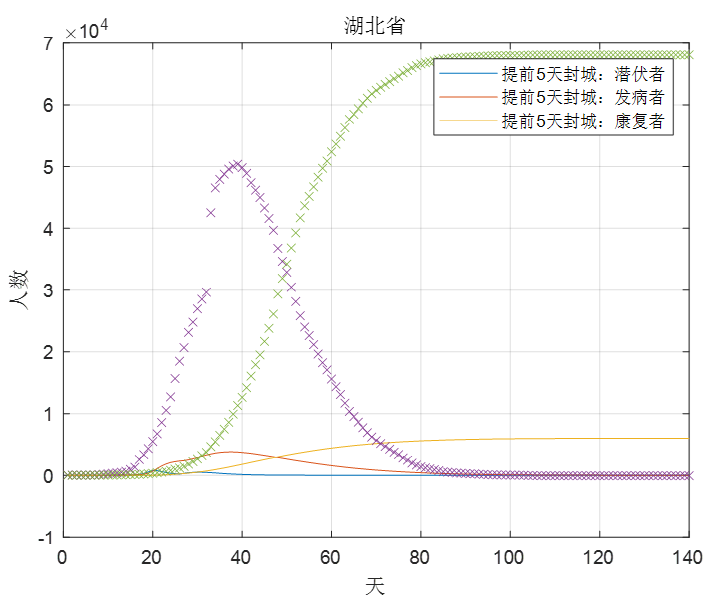
图9
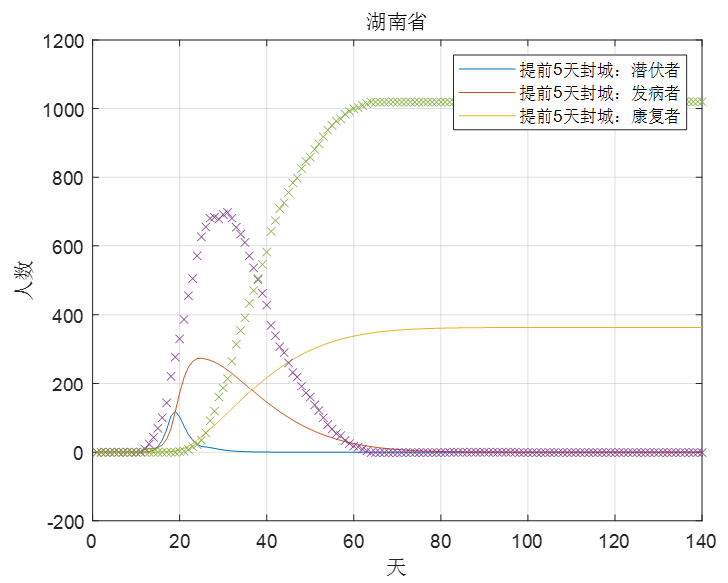
图10
可以看到的是如果提前5天封城,湖北最终的发病人数峰值只会达到4000人左右,发病人数峰值下降了90%以上,而湖南的发病人数峰值也下降了将近60%左右,所以总的来说提前5天封城对这次疫情的影响还是会产生相当大的积极作用。
因此,针对政府这次的及时封城,确实对抑制疫情的传播产生了巨大的积极作用,但同时根据建模分析,如果政府能更早地采取行动,那么这次疫情所带来的影响及损失就能更大程度地降低了。
四、模型优缺点分析与改进方向
本模型优点在于相对简单,参数也较少,求解的时候相对容易。但缺点在于并没有考虑到各个省、区之间人口流动的情况,因此难以考虑由于城市间人口流动而对疫情防控产生的影响。如果需要改进,可考虑以下模型,如图11,IN和Out分别是进入和离开这个城市的人。

图11
附录
主程序
%% 初始化
clear;clc;
%% 原始数据
% data=xlsread('新冠肺炎全国数据','全国数据','B8:K157');
load data150.mat;
global day exposed infectious recovered
day=1:140;
exposed=data(1:140,1);
infectious=data(1:140,2);
recovered=data(1:140,10);
figure('Name','原始数据','NumberTitle','off');
plot(day,exposed,day,infectious,day,recovered);
grid on;
legend('疑似病例','确诊病例','死亡及治愈总和');
%% 确定参数
global alpha gamma y z
alpha=zeros(1,139);
gamma=zeros(1,139);
for n=1:139
alpha(n)=(infectious(n+1)-infectious(n))/infectious(n);
end
for n=1:139
gamma(n)=(recovered(n+1)-recovered(n))/infectious(n);
end
x = fminsearch(@alpha_Objfun,[0 0]);
a_1=x(1);
b_1=x(2);
t=1:139;
y=a_1*exp(-b_1*t);
x = fminsearch(@gamma_Objfun,[0 1]);
a_2=x(1);
b_2=x(2);
t=1:139;
z=a_2*t.^(1/b_2);
figure('Name','确定参数alpha','NumberTitle','off');
plot(1:139,alpha,1:139,y)
grid on;
legend('ΔI/I','α拟合曲线');
figure('Name','确定参数gamma','NumberTitle','off');
plot(1:139,gamma,1:139,z)
grid on;
legend('ΔR/I','γ拟合曲线');
average=sum(gamma)/139;
%% 建立SEIR模型
%--------------------------------------------------------------------------
% 参数设置
%--------------------------------------------------------------------------
day=1:140;
N = 14*10^8;%人口总数
E = 0;%潜伏者
I = 38;%传染者
R = 0;%康复者
S = N - E - I - R;%易感者(健康者)
r1 = 1.5;%S/N=1时,潜伏者接触易感者的人数(接触率1)
a1 = y;%潜伏者传染易感者的概率(感染率1)
b = 0.1;%潜伏者转化为感染者的概率(发病率)
r2 = 0.001;%S/N=1时,感染者接触易感者的人数(接触率2)
a2 = y;%感染者传染易感者的概率(感染率2)
y2 = z;%感染者康复的概率(康复率2)
S(length(day))=0;%预分配内存
E(length(day))=0;%预分配内存
I(length(day))=0;%预分配内存
R(length(day))=0;%预分配内存
%--------------------------------------------------------------------------
% 用递推方法得到模型
%--------------------------------------------------------------------------
for idx = 1:length(day)-1
S(idx+1) = S(idx)-(r1*a1(idx)*E(idx)+r2*a2(idx)*I(idx))*S(idx)/N;
E(idx+1) = E(idx)+(r1*a1(idx)*E(idx)+r2*a2(idx)*I(idx))*S(idx)/N-b*E(idx);
I(idx+1) = I(idx) + b*E(idx) - y2(idx)*I(idx);
R(idx+1) = R(idx) + y2(idx)*I(idx);
end
figure('Name','SEIR模型','NumberTitle','off');
plot(day,E,day,I,day,R);
grid on;
xlabel('天');ylabel('人数');
legend('潜伏者','传染者','康复者');
%% 优化问题
lb = [1.062 0.1 0.2];
ub =[2.000 1.0 0.4];
x0 = lb;
[xfit, fval] = fmincon(@fit_Objfun,x0,[],[],[],[],lb,ub);
r1 = xfit(1);%S/N=1时,潜伏者接触易感者的人数(接触率1)
r2 = xfit(2);%S/N=1时,感染者接触易感者的人数(接触率2)
b = xfit(3);%潜伏者转化为感染者的概率(发病率)
%--------------------------------------------------------------------------
% 用递推方法得到模型
%--------------------------------------------------------------------------
for idx = 1:length(day)-1
S(idx+1) = S(idx)-(r1*a1(idx)*E(idx)+r2*a2(idx)*I(idx))*S(idx)/N;
E(idx+1) = E(idx)+(r1*a1(idx)*E(idx)+r2*a2(idx)*I(idx))*S(idx)/N-b*E(idx);
I(idx+1) = I(idx) + b*E(idx) - y2(idx)*I(idx);
R(idx+1) = R(idx) + y2(idx)*I(idx);
end
figure('Name','拟合后SEIR模型','NumberTitle','off');
plot(day,E,day,I,day,R,day,infectious,'x',day,recovered,'x');
grid on;
xlabel('天');ylabel('人数');
title('全国');
legend('拟合曲线:潜伏者','拟合曲线:发病者','拟合曲线:康复者');
alpha_Objfun.m
function f = alpha_Objfun(x)
global alpha
a=x(1);
b=x(2);
t=1:139;
y=a*exp(-b*t);
f=sum((y(8:end)-alpha(8:end)).^2);
end
gamma_Objfun.m
function f = gamma_Objfun(x)
global gamma
a=x(1);
b=x(2);
t=1:139;
y=a*t.^(1/b);
f=sum((y(9:end)-gamma(9:end)).^2);
end
function f = fit_Objfun(x)
%--------------------------------------------------------------------------
% 参数设置
%--------------------------------------------------------------------------
global y z infectious recovered
day=1:140;
N = 14*10^8;%人口总数
E = 0;%潜伏者
I = 38;%传染者
R = 0;%康复者
S = N - E - I - R;%易感者(健康者)
r1 = x(1);%S/N=1时,潜伏者接触易感者的人数(接触率1)
a1 = y;%潜伏者传染易感者的概率(感染率1)
b = x(3);%潜伏者转化为感染者的概率(发病率)
r2 = x(2);%S/N=1时,感染者接触易感者的人数(接触率2)
a2 = y;%感染者传染易感者的概率(感染率2)
y2 = z;%感染者康复的概率(康复率2)
S(length(day))=0;%预分配内存
E(length(day))=0;%预分配内存
I(length(day))=0;%预分配内存
R(length(day))=0;%预分配内存
%--------------------------------------------------------------------------
% 用递推方法得到模型
%--------------------------------------------------------------------------
for idx = 1:length(day)-1
S(idx+1) = S(idx)-(r1*a1(idx)*E(idx)+r2*a2(idx)*I(idx))*S(idx)/N;
E(idx+1) = E(idx)+(r1*a1(idx)*E(idx)+r2*a2(idx)*I(idx))*S(idx)/N-b*E(idx);
I(idx+1) = I(idx) + b*E(idx) - y2(idx)*I(idx);
R(idx+1) = R(idx) + y2(idx)*I(idx);
end
f = sum((I(1:end)-infectious(1:end)').^2)+sum((R-recovered').^2);
end

 浙公网安备 33010602011771号
浙公网安备 33010602011771号