云计算-hadoop的安装(前期环境配置+伪分布式搭建)
云计算的课程,主要还是要梳理逻辑(尽管我不是做这个方向的,但是课程还是要好好完成!)
前提:
安装好虚拟机VirtualBox,并且下载好Ubuntu的光盘映像文件。
文章思路:
1.配环境(SSH免密码登录,JAVA环境)
2.配Hadoop(下载包,配置相应的环境)
3.运行(感受一下实际例子)
1.配环境
1.1 前期用户等的配置
为了配置环境更加纯净,新建一个用户hadoop,并使用/bin/bash作为shell,密码输入之前设置的,我这里是123(Linux中密码不显示,命令行中只要不报错,就是没问题)
代码:
sudo useradd -m hadoop -s /bin/bash

再对这个用户设置密码,我这里输入的还是123~
代码:
sudu passwd hadoop

再对之前添加的hadoop添加管理员权限
代码:
sudo adduser hadoop sudo
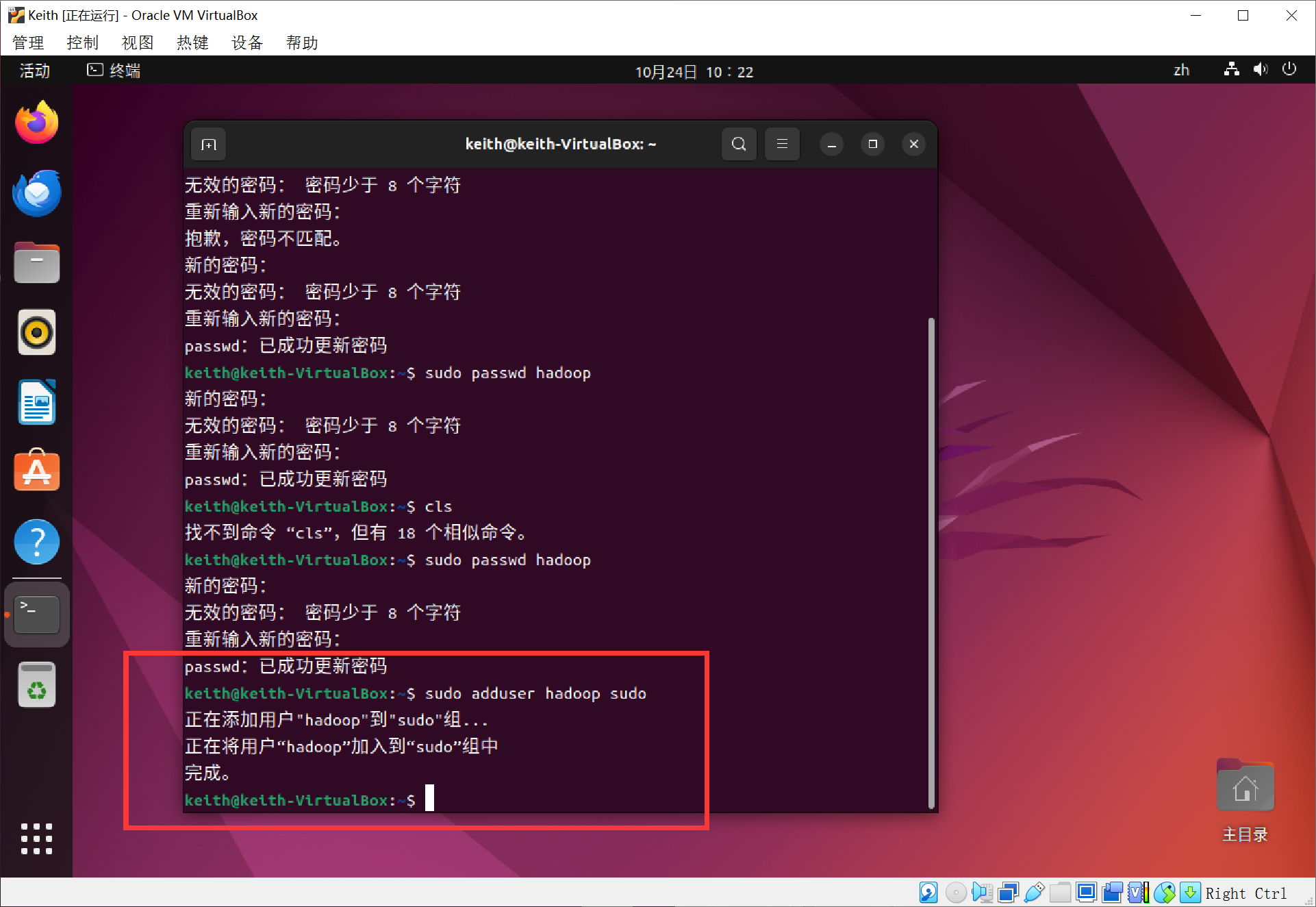
注销当前用户,选择hadoop启动

对电脑上的软件更新,防止后面莫名其妙的失败~
代码:
sudo apt-get update

1.2 SSH免密码登录
ssh的配置
Hadoop中的集群单点模式是需要用到SSH登录,Ubuntu默认参数了SSH client,此外我们还需要安装SSH Server~
代码:
sudo apt-get install openssh-server
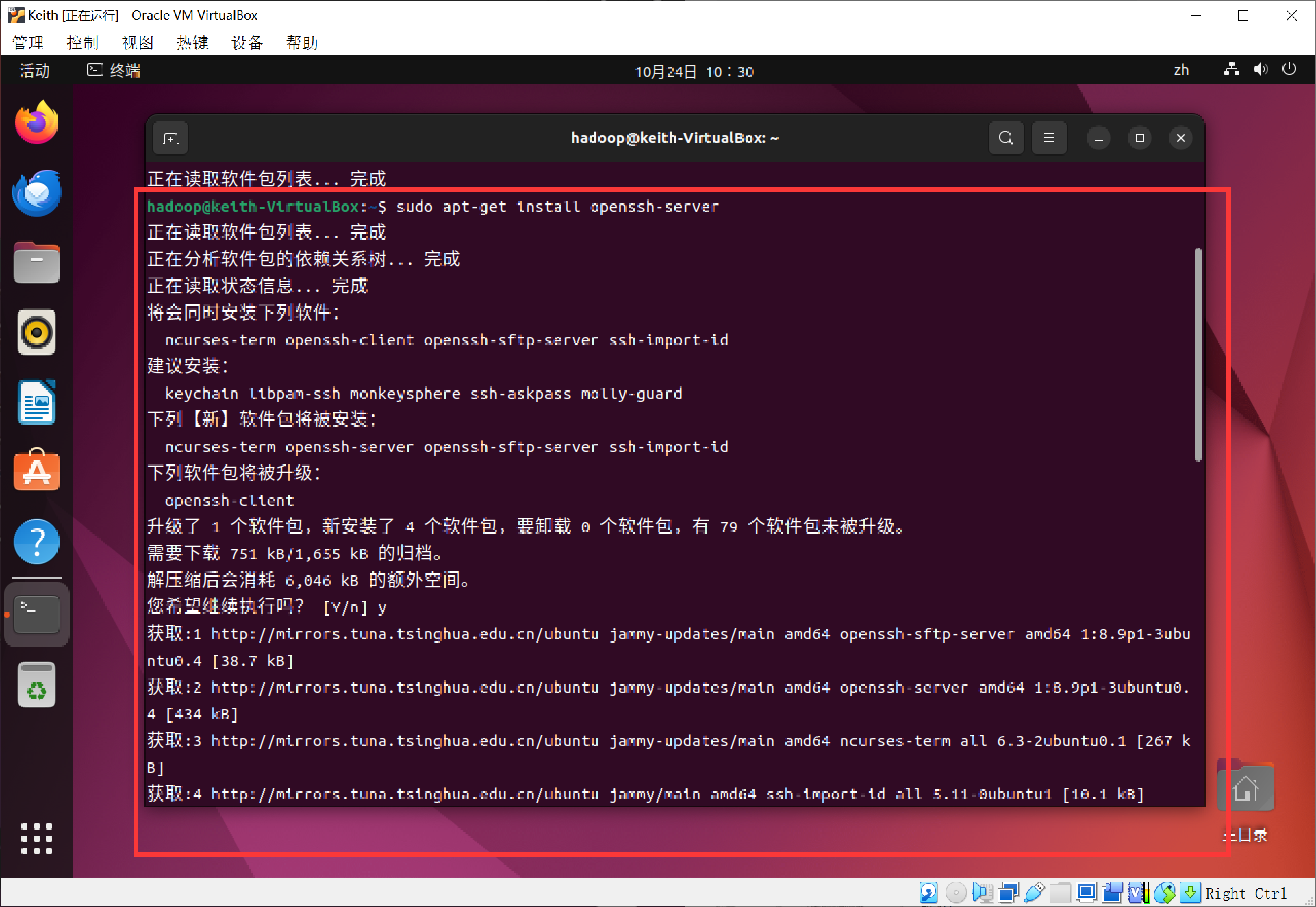
安装之后就可以使用SSH登录本机了,通常我们使用SSH登录远程服务器~
代码:
ssh localhost
第一次需要输入yes,并且输入密码(如图箭头),这样就登录到本机了

但是还是比较麻烦,每次的登录都需要输入密码,所以我们想的是配置成无密码登录,就非常方便。
首先退出刚才登录的ssh,回到了我们原先的终端窗口
代码:
exit
进入到ssh目录里,利用ssh-keygen生成密钥,会有提示,都按回车
代码:
cd ~/.ssh/
ssh-keygen -t rsa
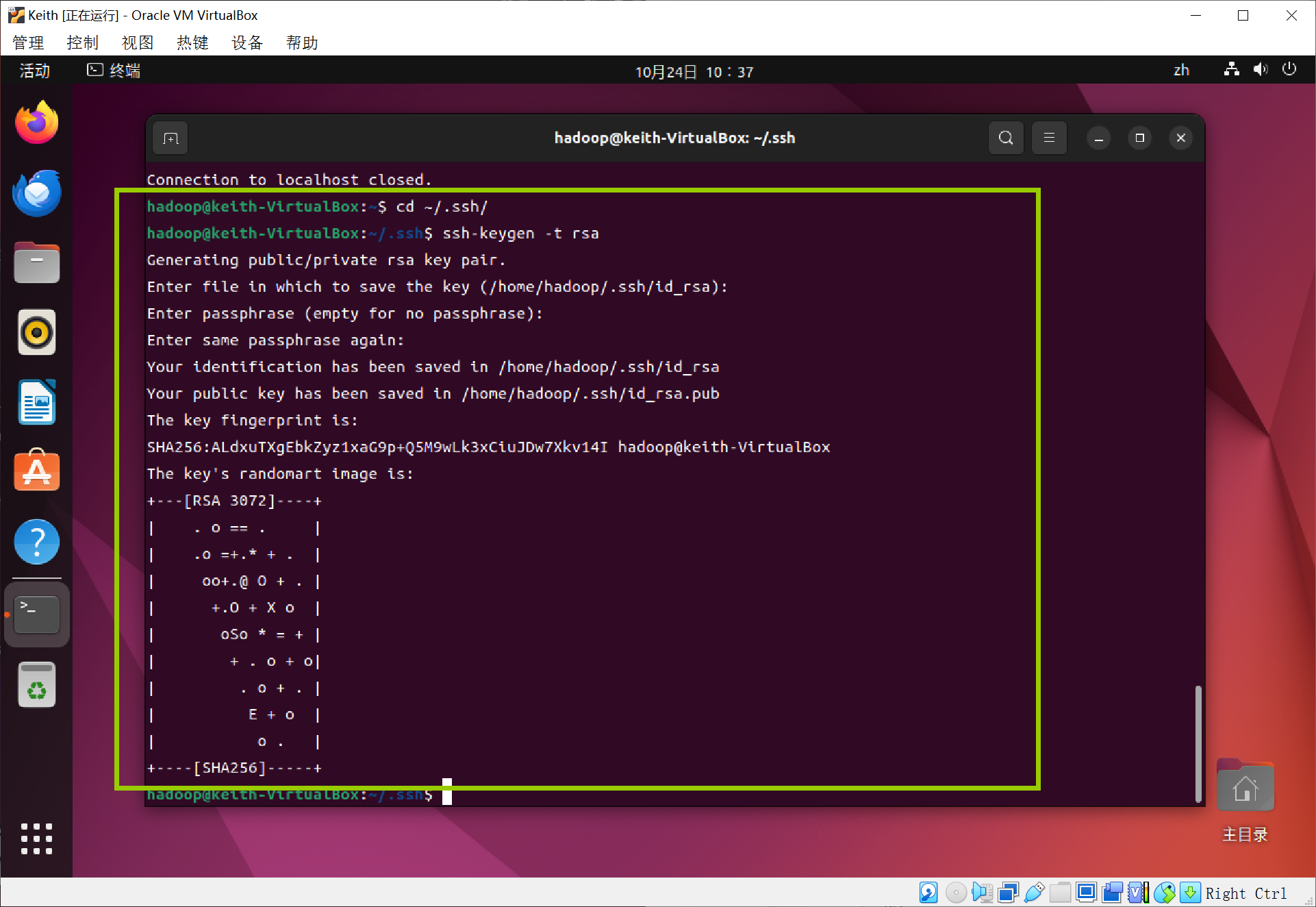
再将密钥加入到授权中,此时使用ssh localhost命令就无需密码登录了~
代码:
cat ./id_rsa.pub >> ./authorized_keys

1.3 JAVA环境配置
接下来安装JAVA环境
首先更新软件包列表~
代码:
sudo apt-get update
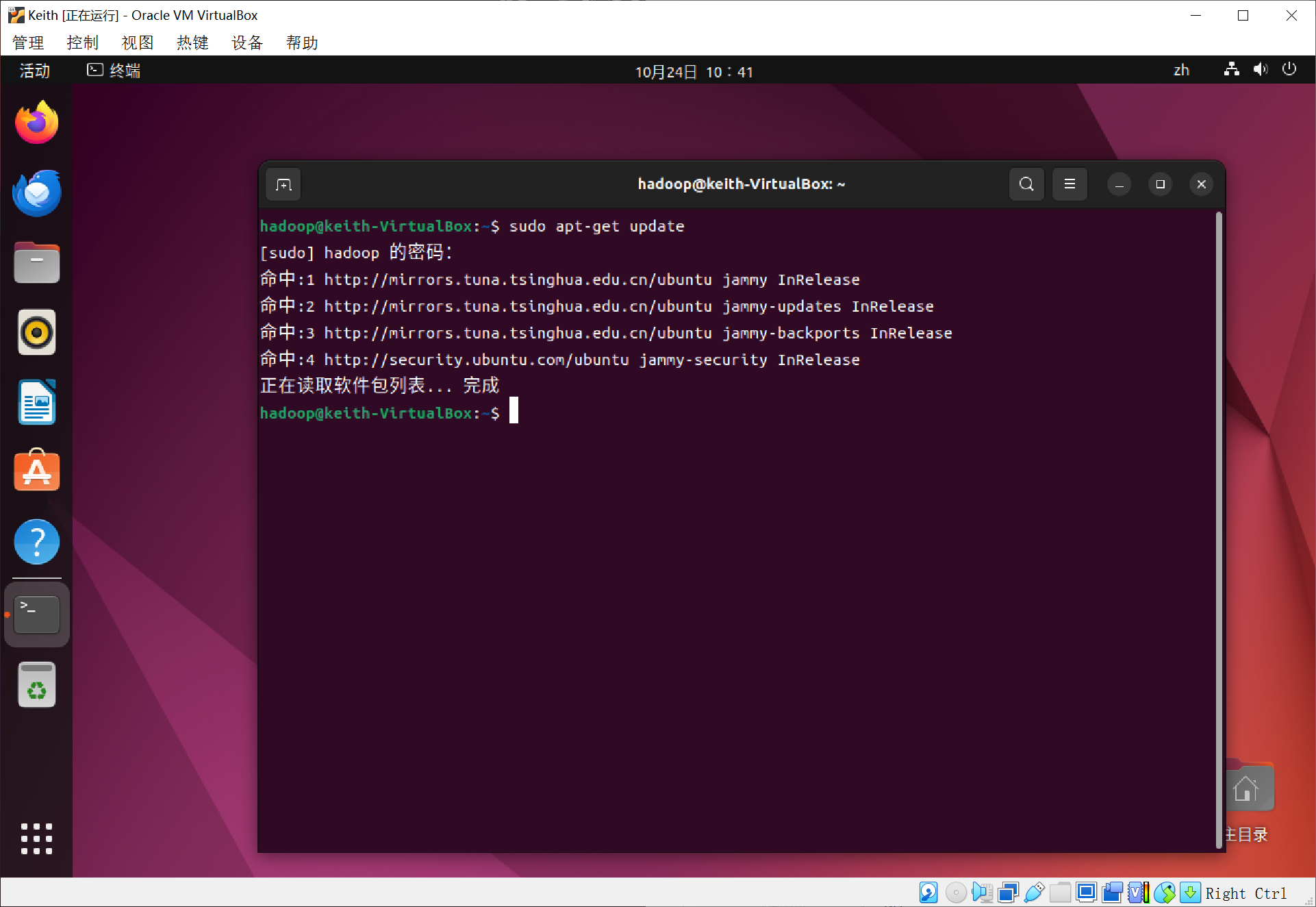
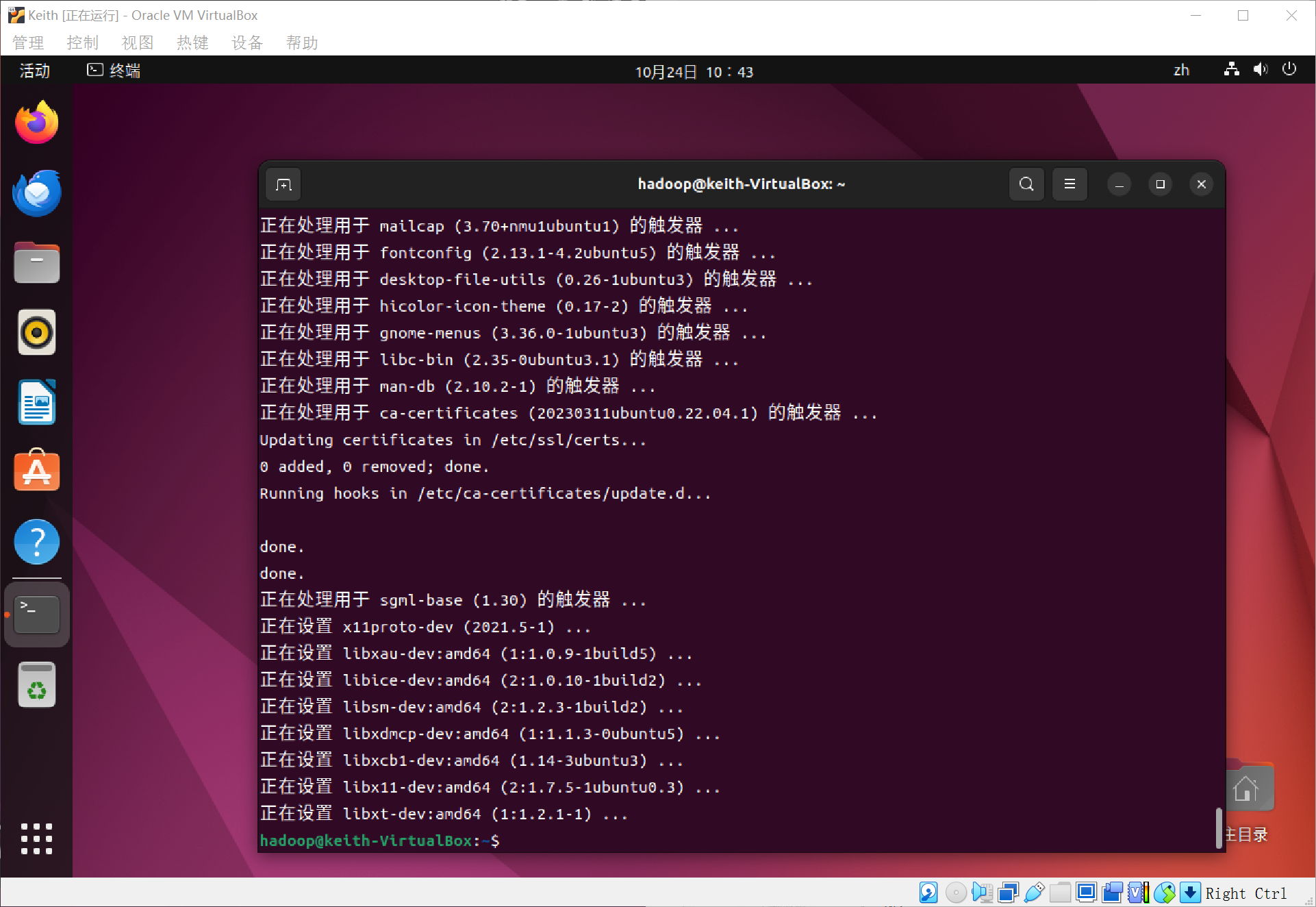
安装openjdk-8-jdk~(要下载很多)
代码:
sudo apt-get install openjdk-8-jdk
查看java版本,是否安装成功
代码:
java -version
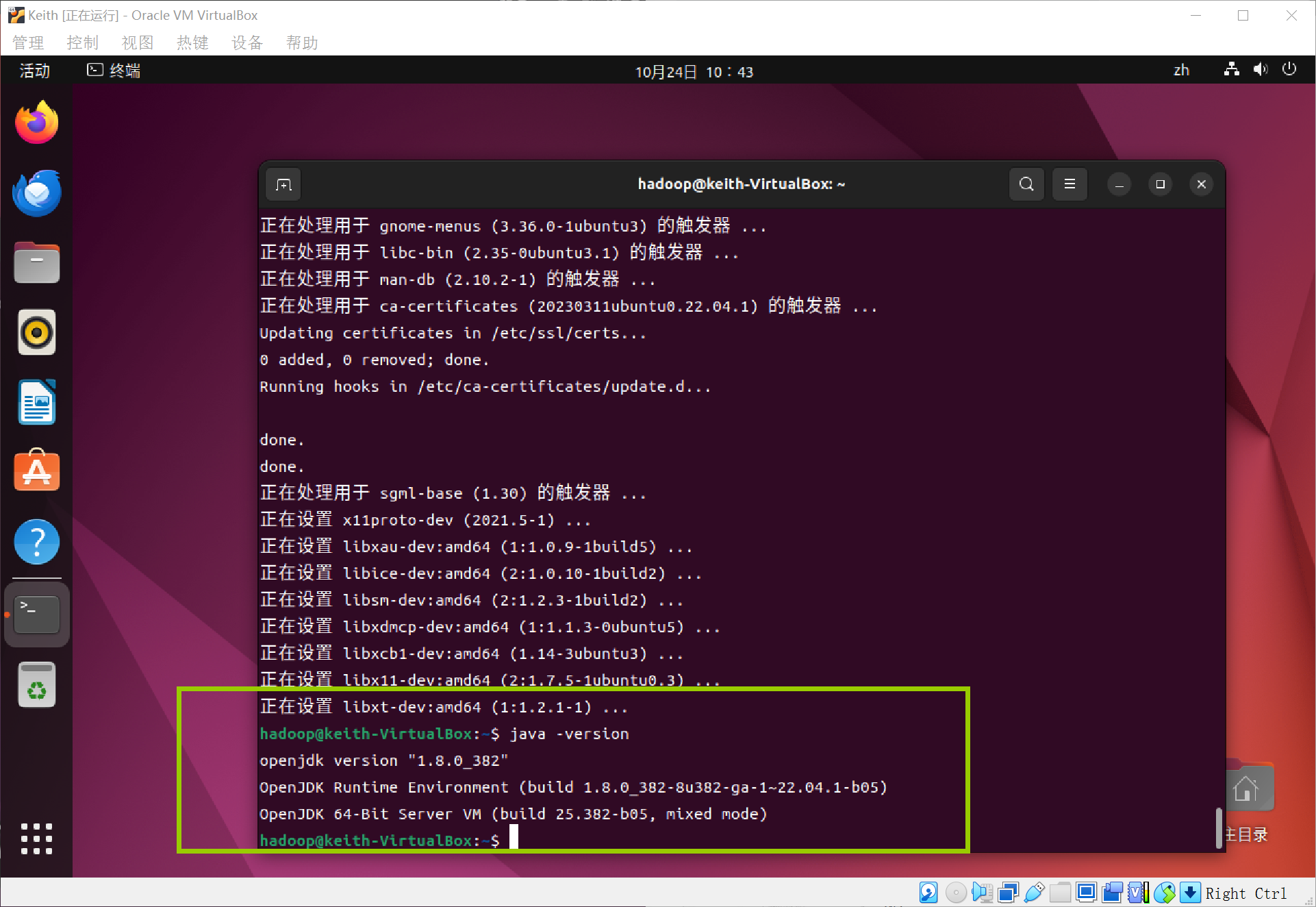
然后配置java环境~
安装gedit~
代码:
sudo apt install gedit

配置java环境
代码:
gedit ~/.bashrc
输入完会打开一个文本

在文件前面添加单独一行,并且保存
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
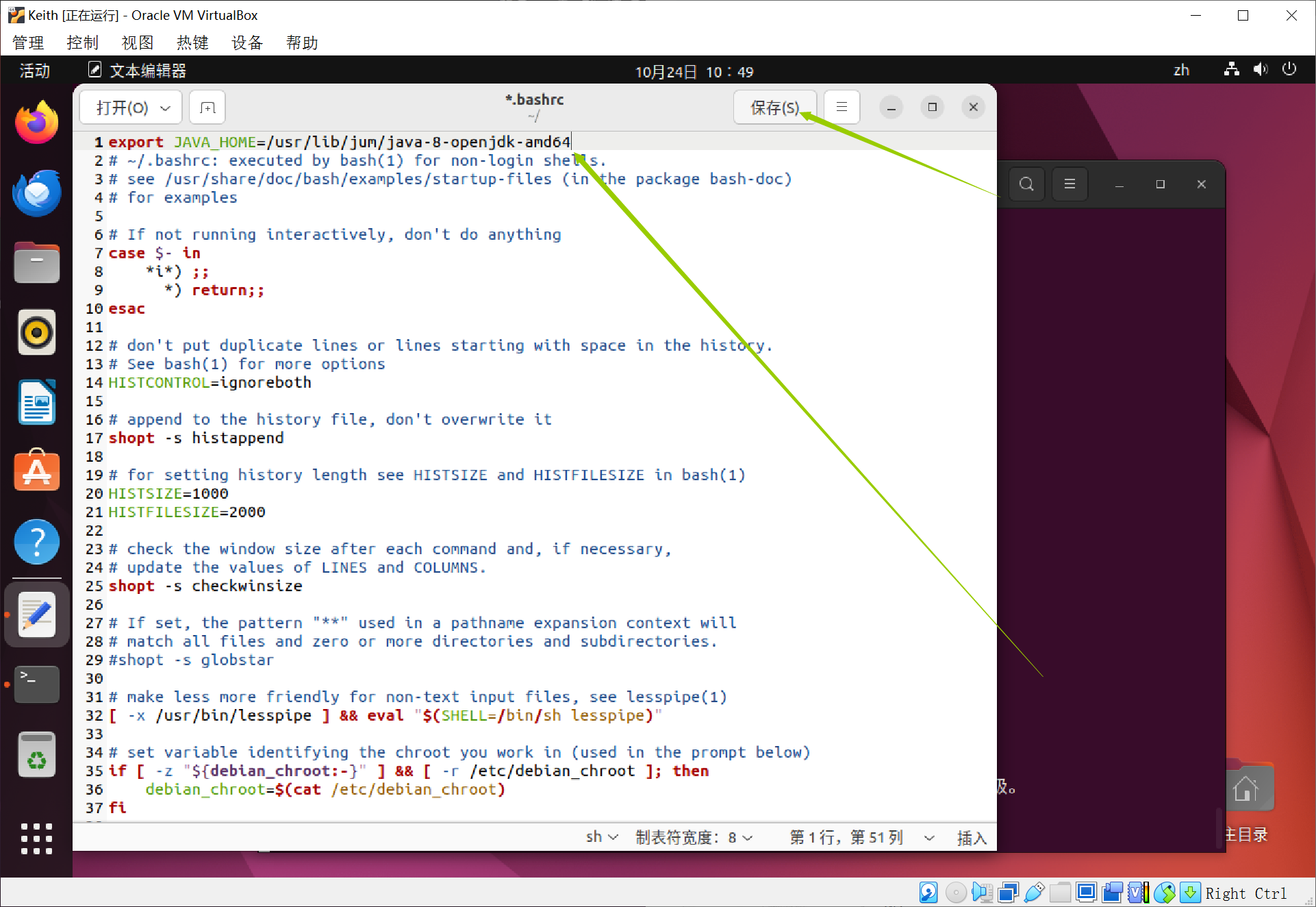
需要让这个环境变量生效,执行命令(第一行命令),并且查看我们设置的环境变量是否生效(第二行开始的命令)
代码:
source ~/.bashrc
echo $JAVA_HOME
java -version
whereis java
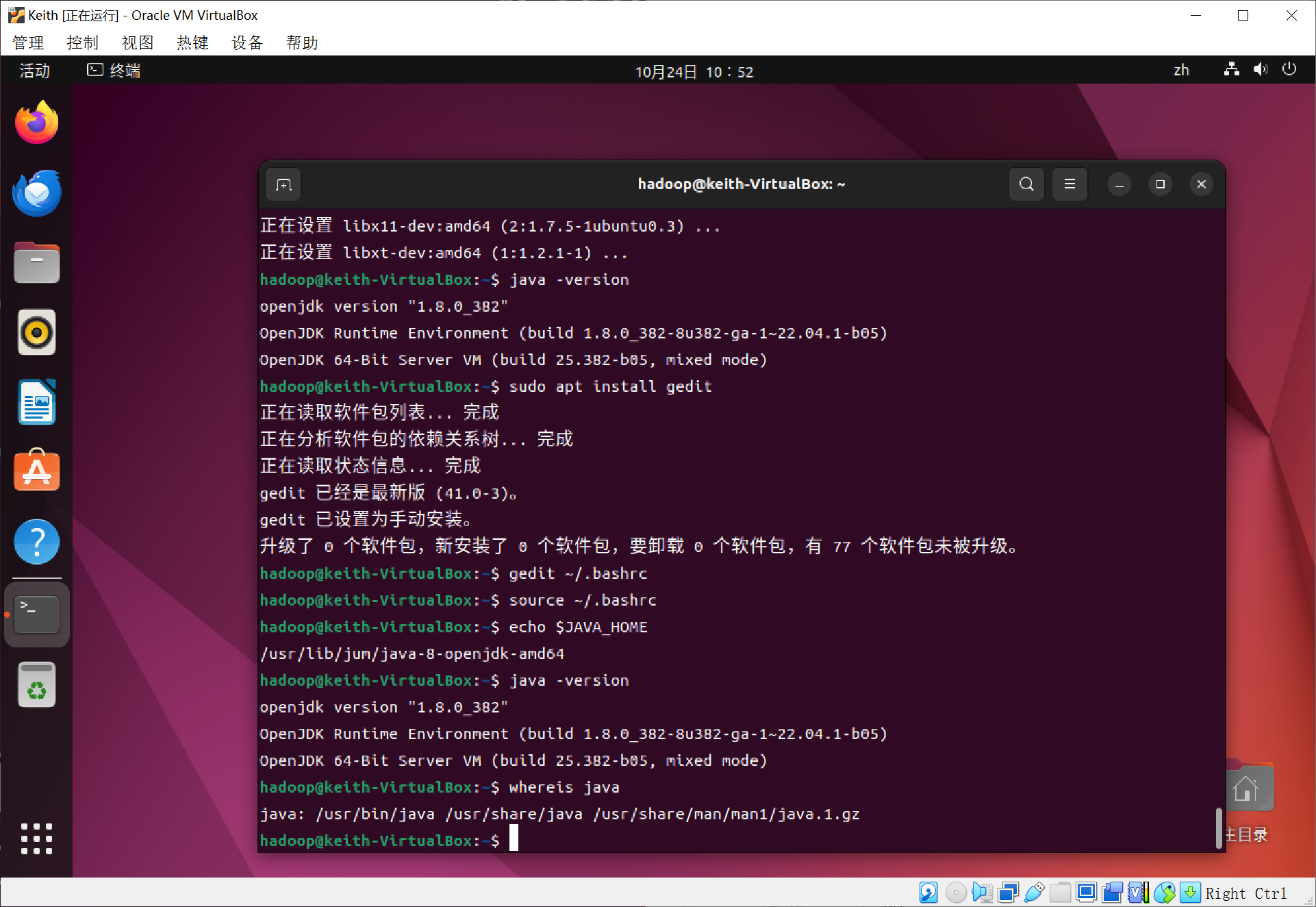
以上安装完成后,就可以安装hadoop了!
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
2.Hadoop配置
2.1 Hadoop下载
我这里是用的外接u盘,然后传到虚拟机内,具体参考:(https://zhuanlan.zhihu.com/p/658173685)
(这里要详细说明一下,如果实在ubuntu里面打开网页,下载很墨迹,所以我建议从外边windows下载好,然后传进去,我用的是u盘,主要是共享文件夹不太会弄)
打开Hadoop官方网站,点击“Downloads”选项卡。 在“Stable Releases”部分,找到最新的可用版本,并点击下载链接。 选择合适的版本(根据操作系统和需求),下载压缩包。
下载好了以后,在想安装的路径下解压,这里选择将hadoop安装到/usr/local中~
进入这个文件夹,将文件夹名改为hadoop~
然后修改文件权限~
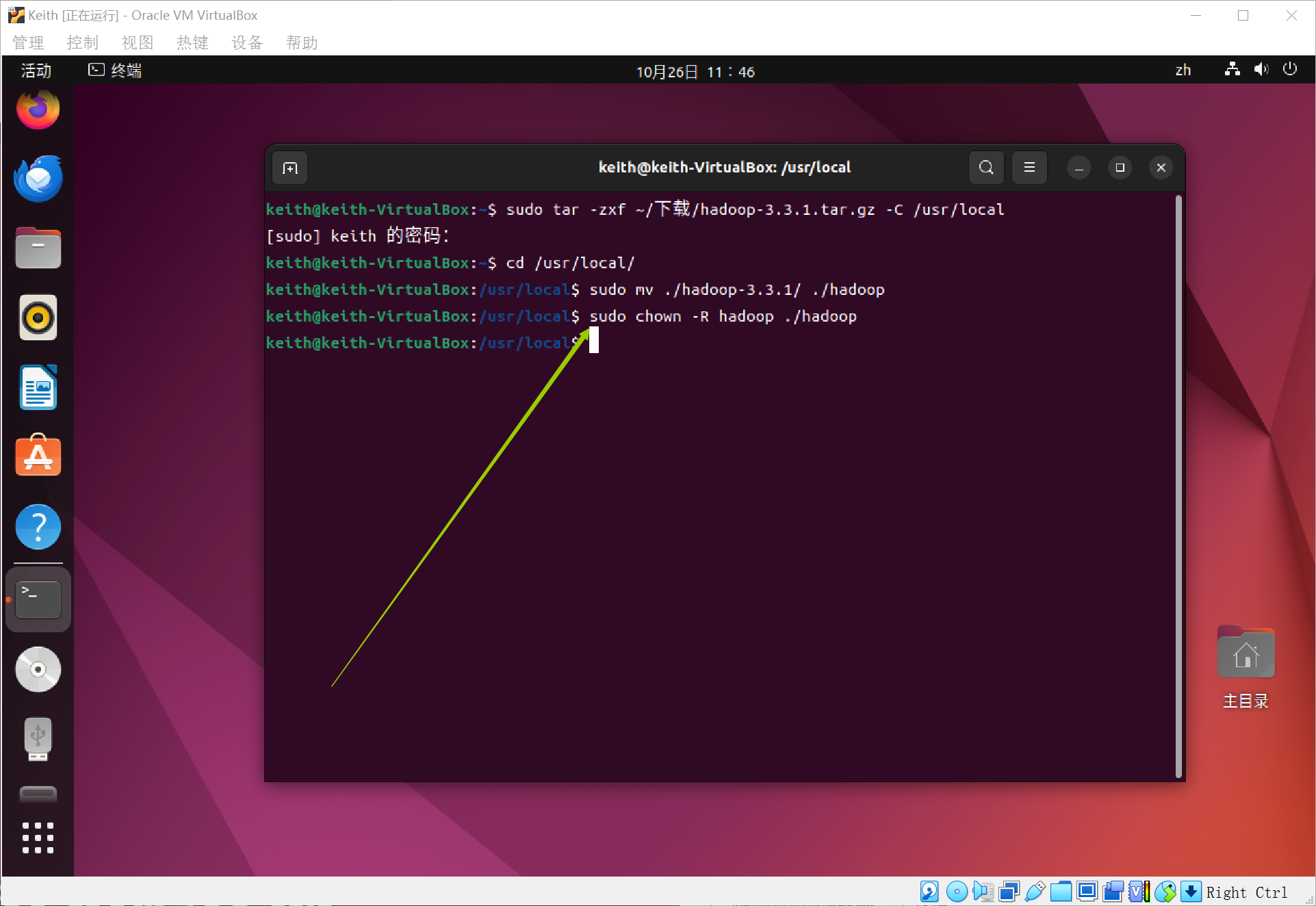
可以用如下的命令查看hadoop是否是可用的,如果出现了Hadoop 3.*.*等的版本,说明是可用的~
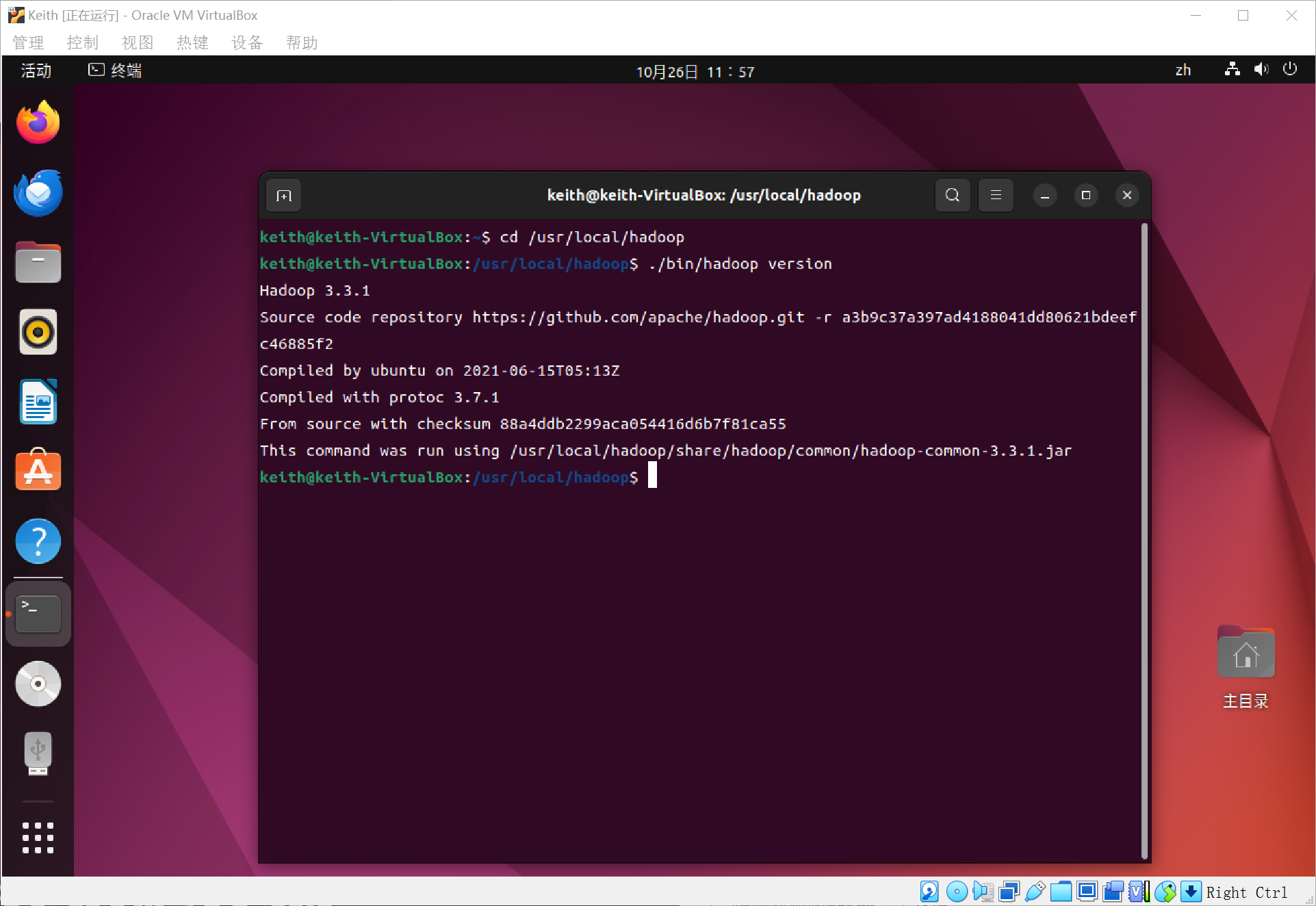
如上图所示,我们的hadoop已经安装好了!~
下面就可以使用hadoop做一些任务了!~
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
3.Hadoop伪分布式
Hadoop模式默认为非分布式模式,无需进行其他配置即可运行,非分布式即单JAVA进程,方便进行调试。(不演示了)
下面演示的是Hadoop伪分布式配置:~
Hadoop可以在单节点上以伪分布式的方式运行,Hadoop进程以分离的Java进程来运行,节点既作为NameNode也作为DataNode,同时读取的是HDFS中的文件。
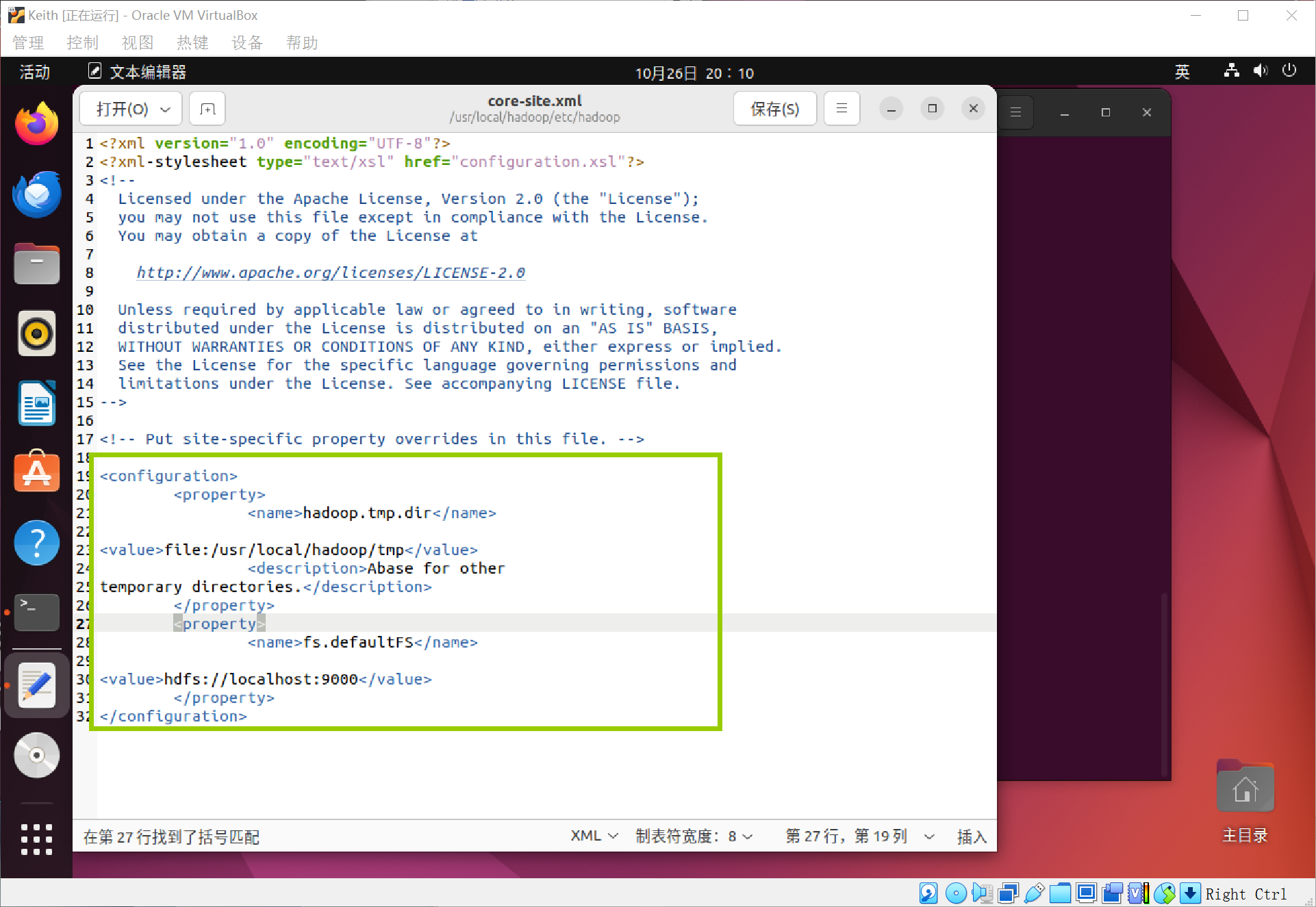
伪分布式需要修改两个配置文件,Hadoop的配置文件是xml格式,每个配置以声明property的name和value的方式来实现,通过gedit编辑会比较方便,将当中的configuration改成如下:
同样的,修改配置文件hdfs-site.xml
分别对应这两条代码:
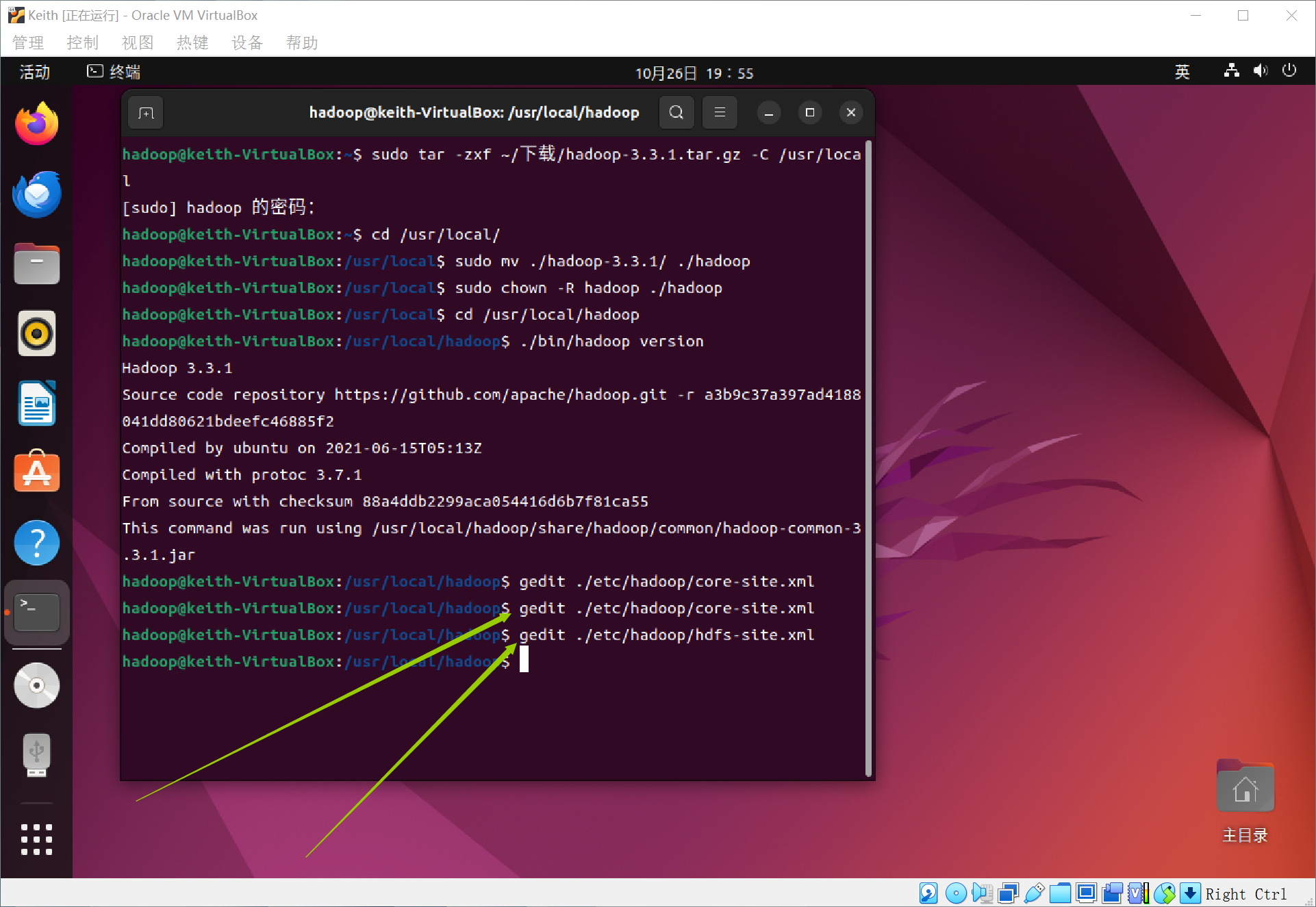
注意,是configuration部分!
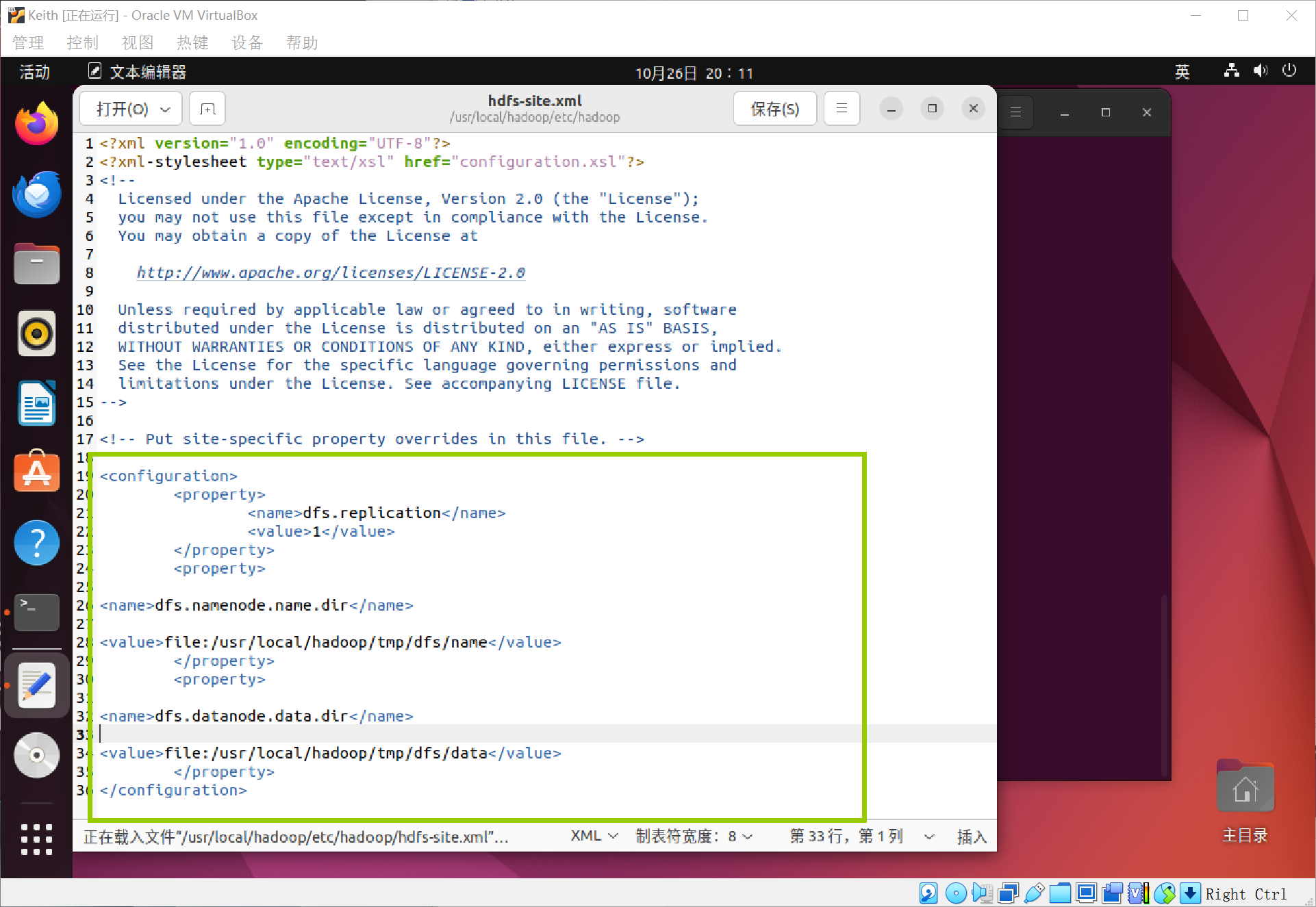
配置完成后,执行NameNode的格式化
当出现提示,需要输入Y/N时,一定要输入大写的Y!
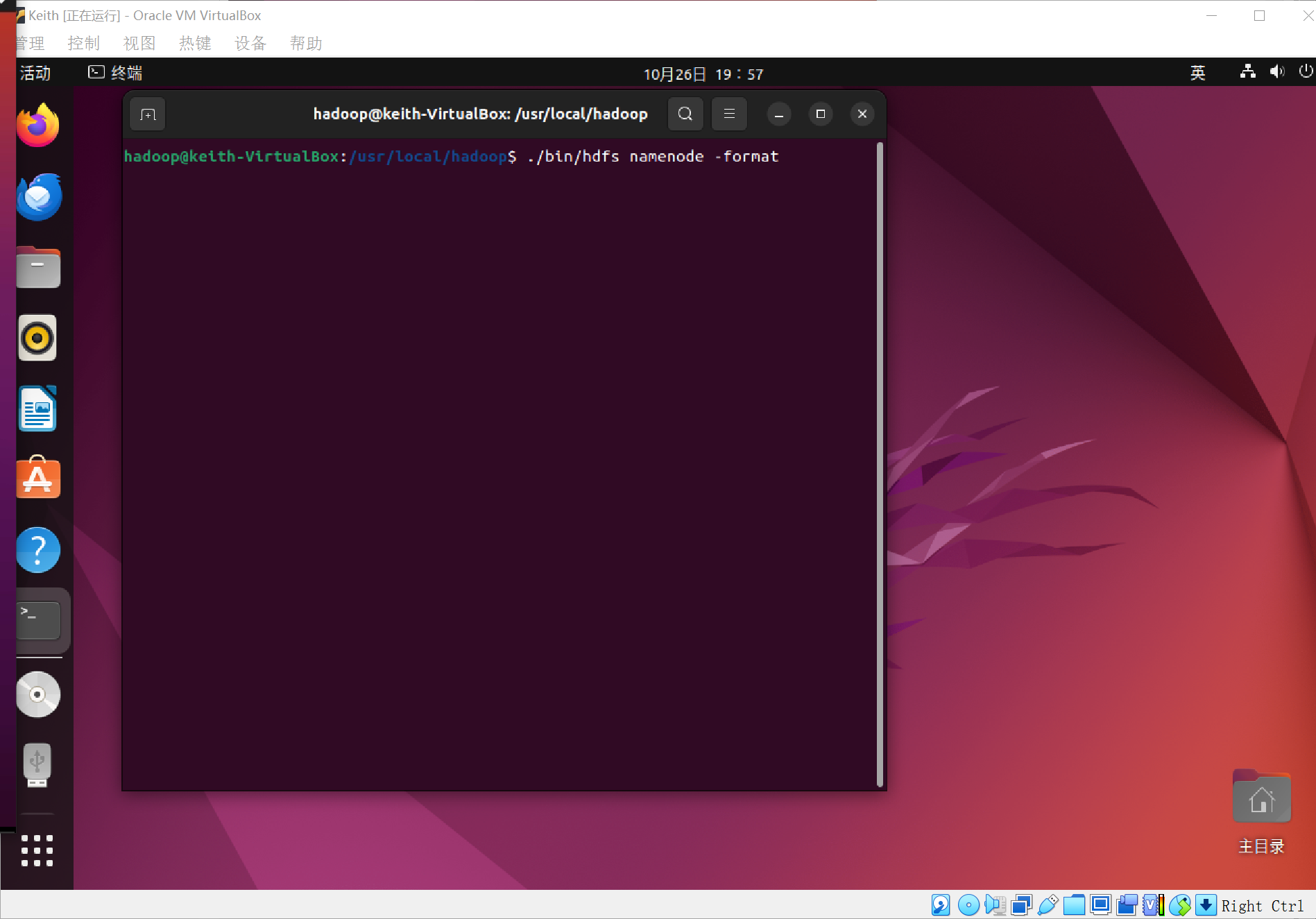
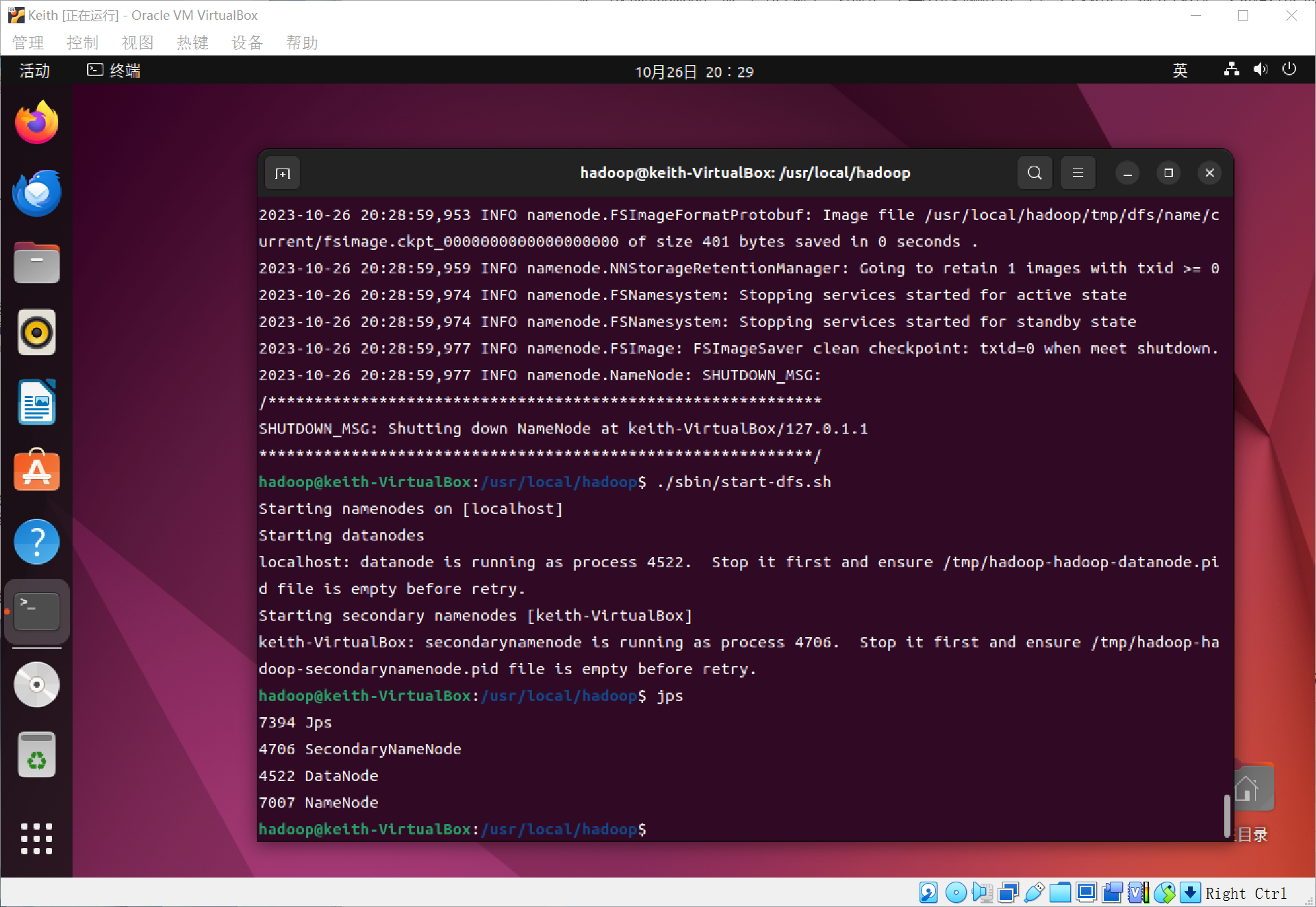
接着开启NameNode和DataNode守护进程~
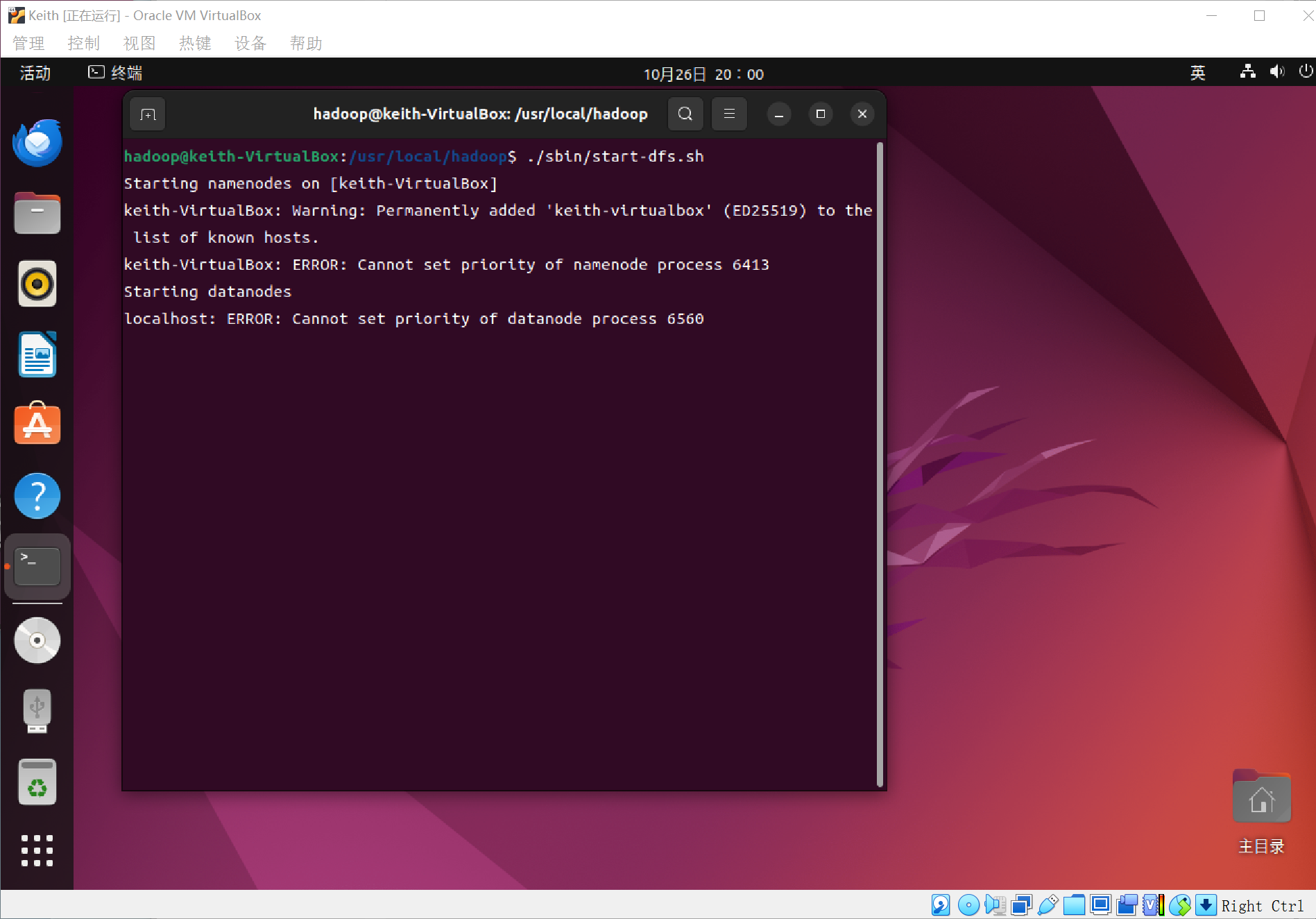
可以通过命令jps来判断是否成功启动,如果没有NameNode或者DataNode就是配置不成功(如下图,就是不成功,仔细检查之前的步骤,或者通过查看启动日志来排查原因)
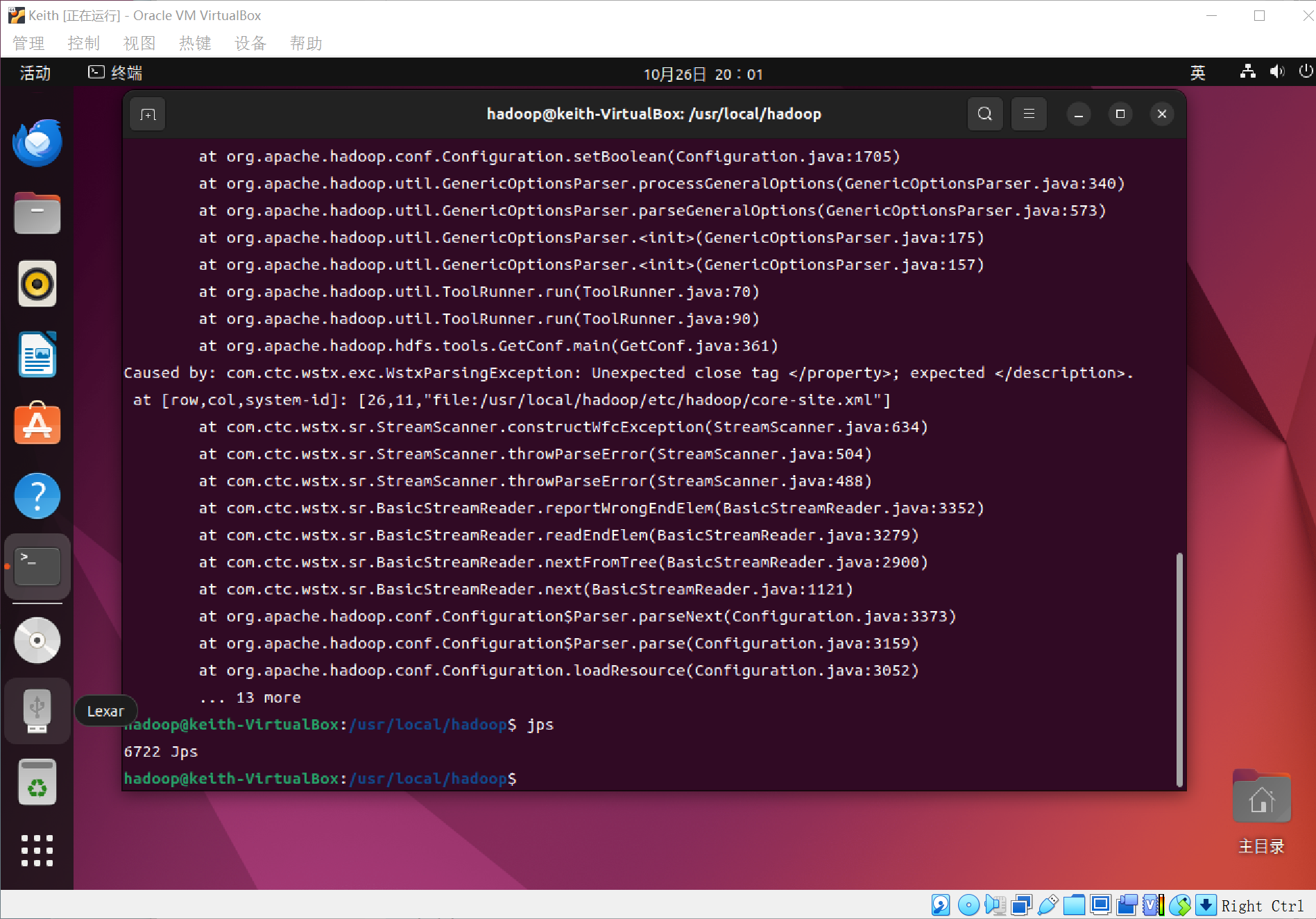
我仔细检查了之前的两个gedit编辑的文档,发现其中有一处编写出错,导致不成功,然后重新修改后,启动,如图,成功!~
不,没有NameNode,还是启动失败了,发现又是另一个文档编辑出错了!(上图中已经做出了修改,大家跟着我敲可以成功的,一定要认真细心,如果不对了,找一下,肯定是哪里出问题了!)
我又犯了一个错误,还找了半天,如果大家上面错了,然后修改过后,一定要执行格式化的那个指令!
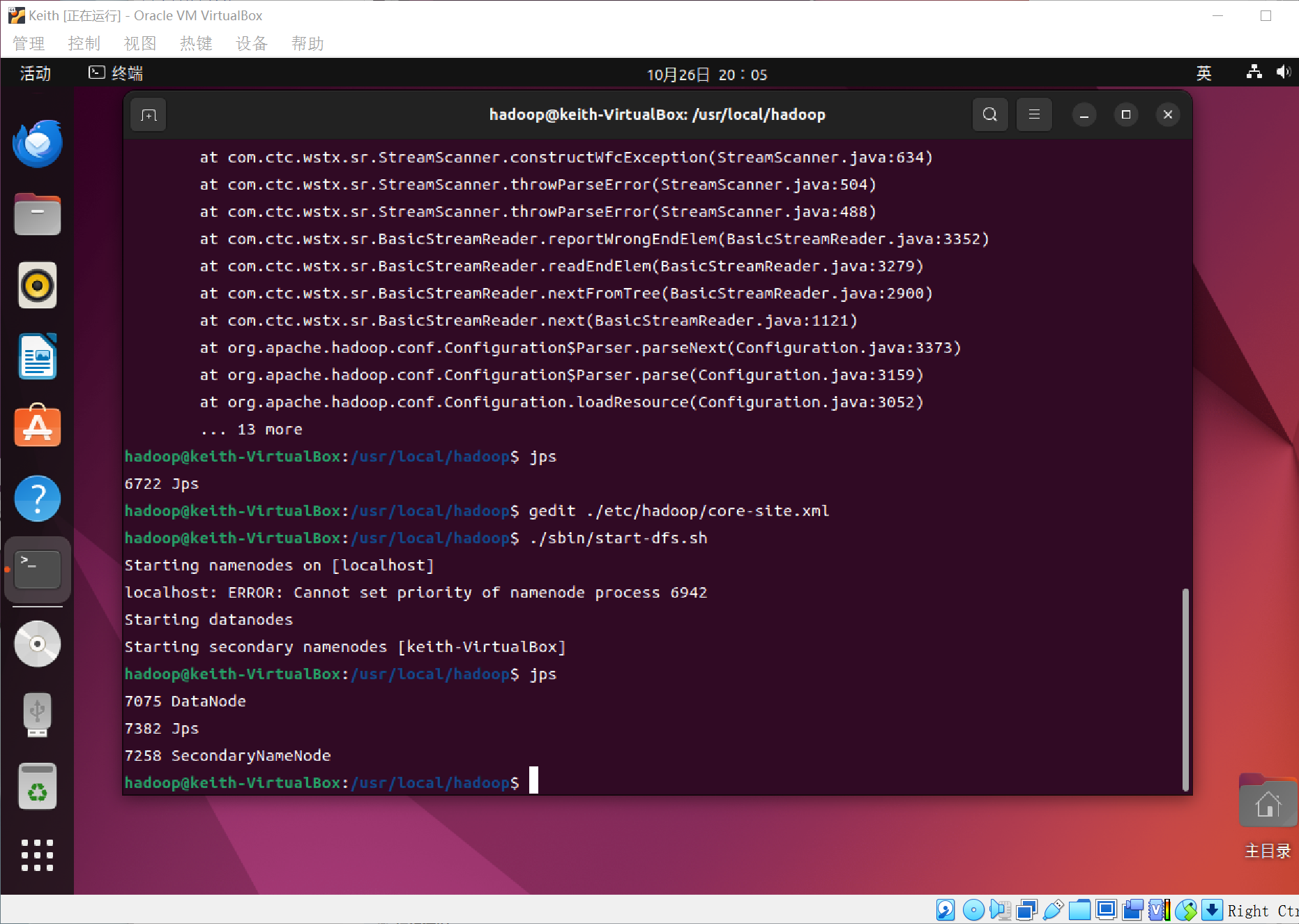
重新修改后,如图这样子:
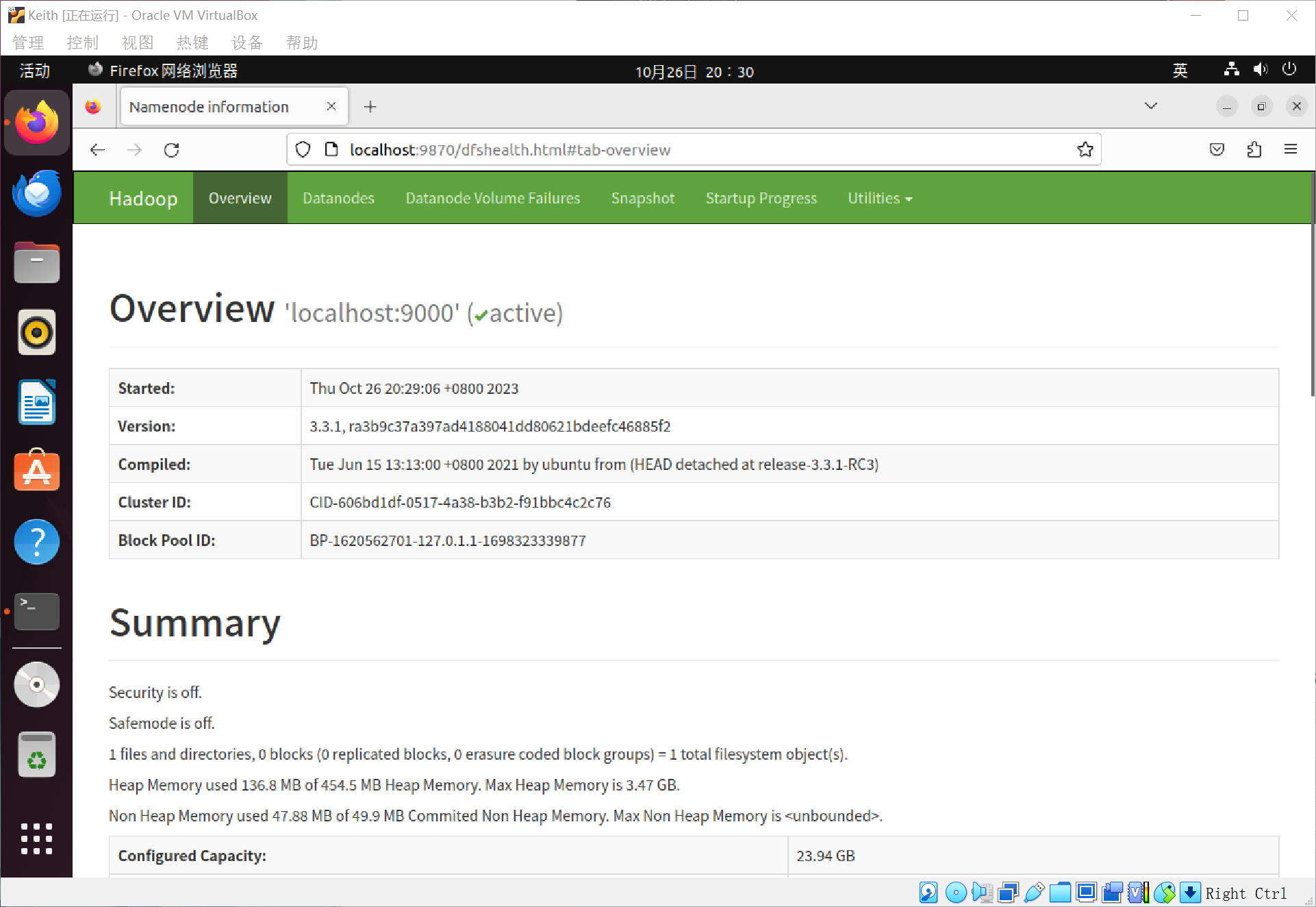
成功启动后,可以访问Web界面 http://locaolost:9870。(Hadoop从3.X版本开始,启动端口变成了9870!!不是50070!)
界面里可以查看NameNode和DataNode信息,还可以在线查看HDFS中的文件
单机模式,grep读取的是本地的数据。
伪分布式,读取的是HDFS上的数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号