
MySQL-数据库的设计
1.多表之间的关系
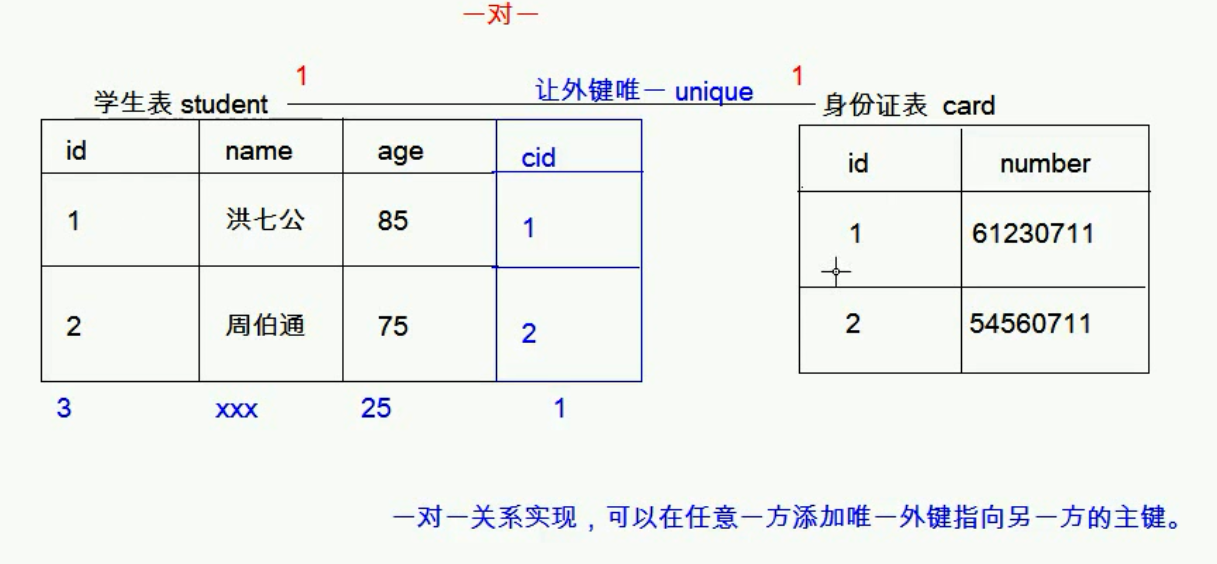
Ⅰ.一对一
如:人和身份证
分析:一个人只有一个身份证,一个身份证只能对应一个人
实现方式:一对一关系中可以在任意一方添加唯一的外键指向另一方1的主键,比如:下面的图中的id为3的字段就不能添加上,因为他的cid和id为1的字段的cid冲突
Ⅱ.一对多(多对一)
如:部门和员工
分析:一个部门对应多个员工,一个员工对应一个部门
实现方式:在多的一方建立外键,指向一的一方的主键

Ⅲ.多对多
如:学生和课程
分析:一个学生可以选择多门课程,一个课程可以被多个学生选择
实现方式:多对多关系需要借助第三张中间表,中间表至少包含两个字段,这两个字段作为第三张表的外键,分别指向两张表的主键

2.数据库范式
概念:设计数据库时,需要遵循的一些规范,要遵循后面的范式要求,必须先遵循前面的所有范式要求
设计关系数据库时,遵循不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小
目前关系型数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)、第五范式(5NF)
分类:
1.第一范式:在每一列都是不可分割的原子数据项
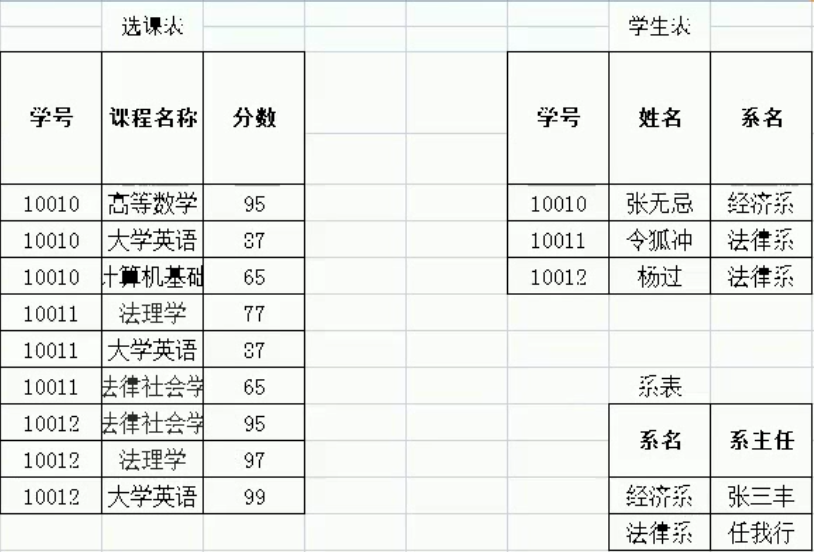
如:在excel表中
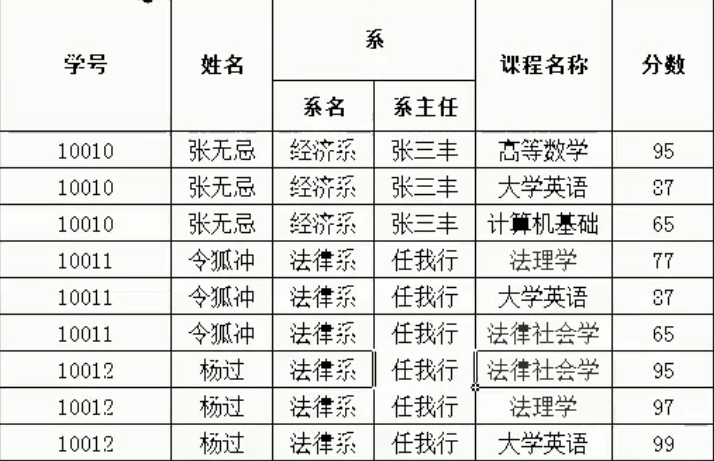
如果要设计成mysql的表,则需要将系分开成系名和系主任两个列,为了保证第一范式
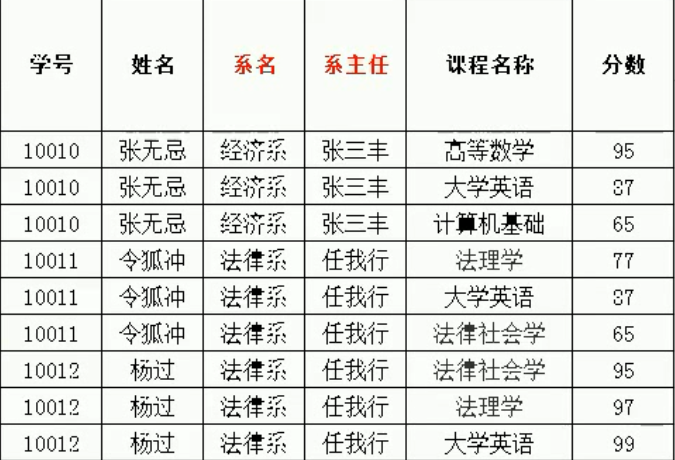
存在的问题:
1.存在比较严重的数据冗余:姓名、系主任、系名存在冗余
2.数据添加存在问题:添加新开设的系和系主任时,数据不合法(新添加的字段只有系名和系主任,是不符合规定的)
3.数据删除存在问题:如果有同学毕业了,删除数据,则会将系的数据也一起删除了
2.第二范式:在1NF的基础上,非码属性必须完全依赖于码(在1NF基础上消除非主属性对主码的部分函数依赖)
几个概念:
1.函数依赖:A——>B,如果通过A属性(属性组)的值,可以确定唯一B属性的值,则称B依赖于A
例如上图中:学号——>姓名; (学号,课程名称)——>分数
2.完全函数依赖:A——>B,如果A是一个属性组,则B属性值的确定则需要依赖于A属性组中所有属性值
例如上图:(学号,课程名称)——>分数
3.部分函数依赖:A——>B,如果A是一个属性组,则B属性值的确定则需要依赖于A属性组中某一些属性值即可
例如上图:(学号,课程名称)——>姓名
4.传递函数依赖:A——>B,B——>C,如果通过A属性(属性组)的值,可以确定唯一B属性的值,在通过B属性(属性组)的值可以确定唯一C属性的值,则称C传递函数依赖于A
例如上图:学号——>系名,系名——>系主任
5.码:如果在一张表中,一个属性或属性组,被其他所有属性所完全依赖,则称这个属性(属性组)为该表的码
例如上图:该表中的码为:(学号,课程名称)
主属性:码属性组中所有属性
非主属性:除去码属性组中的属性
因此,在上表中,(学号,课程名称)为码,完全依赖码的属性只有分数(也就是说,必须通过学号,课程名称两个条件才能确立的属性),其他的都不是完全依赖(姓名,系名,系主任)
解决后的表格:
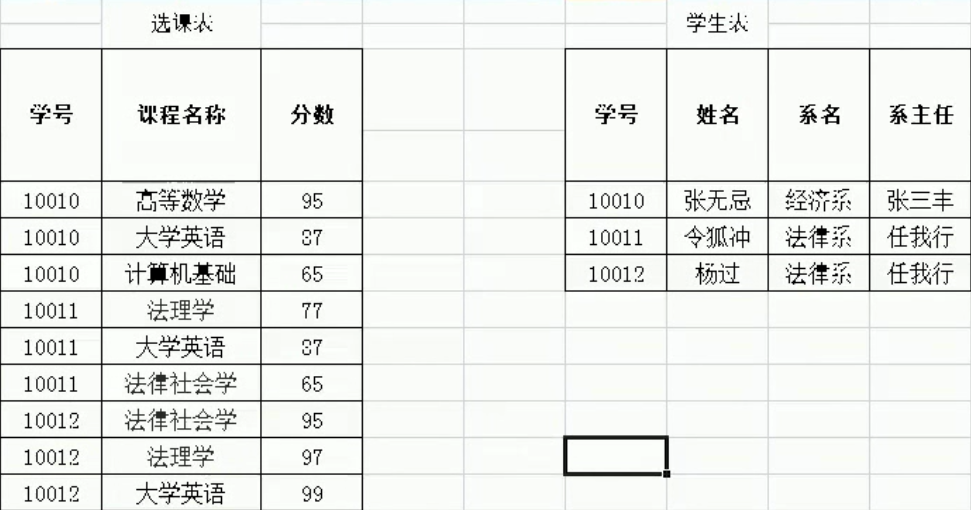
存在的问题(1NF中第一个问题就解决了):
2.数据添加存在问题:添加新开设的系和系主任时,数据不合法(新添加的字段只有系名和系主任,是不符合规定的)
3.数据删除存在问题:如果有同学毕业了,删除数据,则会将系的数据也一起删除了
3.第三范式:在2NF的基础上,任何非主属性不依赖于其他非主属性(在2NF上消除传递依赖)
解决部分依赖的表格:
3.备份和还原
1.命令行:
备份:mysqldump -u用户名 -p密码 数据库名称 > 保存的路径
还原:
1.登录数据库 mysql -uroot -proot
2.创建数据库 create database 数据库名称
3.使用数据库 use 数据库名称
4.执行文件 source 文件路径
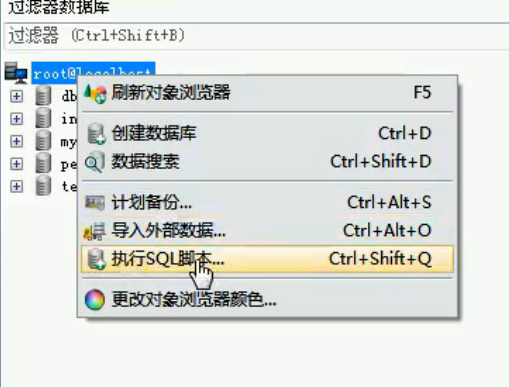
2.图形化工具:
备份:

备份路径:

还原:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号