

使用scrapy编写爬虫:爬取豆瓣Top250读书的评论
作者:@keenleung
本文为作者原创,转载请注明出处:https://www.cnblogs.com/KeenLeung/p/12244280.html
目录
介绍
安装
创建scrapy项目
项目结构说明
配置 settings.py
设置数据模型 items.py
爬虫代码 common_spider.py
处理数据 pipelines.py
运行
介绍
以前我们写爬虫,要导入和操作不同的模块,比如requests模块、gevent库、csv模块等。而在Scrapy里,你不需要这么做,因为很多爬虫需要涉及的功能,比如麻烦的异步,在Scrapy框架都自动实现了。
我们之前编写爬虫的方式,相当于在一个个地在拼零件,拼成一辆能跑的车。而Scrapy框架则是已经造好的、现成的车,我们只要踩下它的油门,它就能跑起来。这样便节省了我们开发项目的时间。
安装
pip3 install scrapy
创建scrapy项目
先cd到你存放项目的文件夹位置,然后,使用命令:scrapy startproject 项目名称,创建项目
这里以【获取豆瓣 Top250 读书的评论(图书名称、评论人、评论时间、评论内容),链接地址:https://book.douban.com/top250?start=0】作为演示项目
创建项目:
scrapy startproject doubancomment
项目结构说明
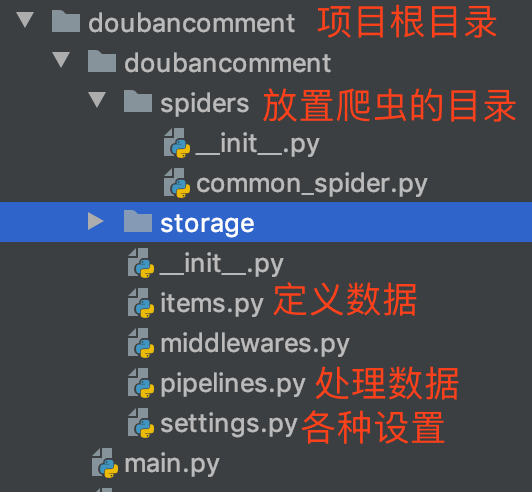
配置 settings.py

USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36 OPR/66.0.3515.36 (Edition Baidu)' # 是否遵循robots协议 ROBOTSTXT_OBEY = False # 控制下载速度 DOWNLOAD_DELAY = 0.5 # 开启管道 ITEM_PIPELINES = { 'doubancomment.pipelines.DoubancommentPipeline': 300, }
设置数据模型 items.py
import scrapy class DoubancommentItem(scrapy.Item): # 图书名称 bookname = scrapy.Field() # 评论人 common_id = scrapy.Field() # 评论时间 common_date = scrapy.Field() # 指数 common_vote_num = scrapy.Field() # 评论内容 common_content = scrapy.Field()
爬虫代码 common_spider.py
# 获取豆瓣读书Top250的评论 import scrapy from bs4 import BeautifulSoup from ..items import DoubancommentItem class Common_spider(scrapy.Spider): # 爬虫名称 name = 'comment' # 允许爬取的网站域名 allowed_domains = ['book.douban.com'] # 起始网址 start_urls = [] # 获取前2页书籍的评论 for x in range(2): url = "https://book.douban.com/top250?start={}".format(25*x) start_urls.append(url) # 解析起始网址 def parse(self, response): soup = BeautifulSoup(response.text, 'html.parser') pl2_list = soup.find_all("div", class_='pl2') for pl2 in pl2_list: # 书籍链接 book_link = pl2.find("a")['href'] # 评论链接 common_link = book_link + "comments/" yield scrapy.Request(common_link, callback=self.common_parse) # 解析评论 def common_parse(self, response): soup = BeautifulSoup(response.text, 'html.parser') # 书籍名称 bookname = soup.find_all("p", class_='pl2 side-bar-link')[1].find("a").text li_list = soup.find_all('li', class_='comment-item') for li in li_list: common_info = li.find(class_='comment-info') # 评论人 common_id = common_info.find("a").text # 评论时间 if len(common_info.find_all("span")) > 1: common_date = common_info.find_all("span")[1].text else: common_date = common_info.find("span").text # 指数 common_vote_num = li.find(class_='vote-count').text # 评论内容 common_content = li.find(class_='comment-content').find("span").text item = DoubancommentItem() item['bookname'] = bookname item['common_id'] = common_id item['common_date'] = common_date item['common_vote_num'] = common_vote_num item['common_content'] = common_content yield item
处理数据 pipelines.py
from openpyxl import Workbook import os class DoubancommentPipeline(object): def __init__(self): self.wb = Workbook() self.sheet = self.wb.active self.sheet.append(['图书名称', '评论人', '评论时间', '指数', '评论内容']) # 处理数据 def process_item(self, item, spider): line = [item['bookname'], item['common_id'], item['common_date'], item['common_vote_num'], item['common_content']] self.sheet.append(line) return item # 爬虫结束时,会调用这个方法 def close_spider(self, spider): # 目录不存在 -> 创建目录 data_dir = os.path.dirname(__file__) + "/storage/data/" if not os.path.isdir(data_dir): os.makedirs(data_dir) # 保存文件 self.wb.save(data_dir + "comment.xlsx") # 关闭文件 self.wb.close()
运行
方式一:cd到根目录,执行命令:scrapy crawl 爬虫的名称
scrapy crawl comment
方式二:cd到根目录,创建文件 main.py:
from scrapy import cmdline cmdline.execute(['scrapy', 'crawl', 'comment'])
也就是将方式一的命令,写成列表的形式,然后,执行 main.py
执行完毕,会有这样的提示:[scrapy.core.engine] INFO: Spider closed (finished)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架