
Python中的字符编码
一、文本编辑器存取文件的原理:
#1、打开编辑器就打开了启动了一个进程,是在内存中的,所以,用编辑器编写的内容也都是存放与内存中的,断电后数据丢失
#2、要想永久保存,需要点击保存按钮:编辑器把内存的数据刷到了硬盘上。
#3、在我们编写一个py文件(没有执行),跟编写其他文件没有任何区别,都只是在编写一堆字符而已。
二、python解释器执行py文件的原理 ,例如python3 test.py
#1、python解释器启动,此时相当于启动了一个文本编辑器。
#2、Python解释器相当于一个文本编辑器,当解释器打开一个.py文件的时候,就把这个文件的内容从硬盘上读到了内存中。
#3、Python的解释性决定了解释器,只关心文本内容,不关心文本后缀。文本后缀不是.py的,例如:用python3 test.txt 也能运行出结果。
#4、Python解释器解释执行刚刚加载到内存中的文本内容。
对比Python解释器与文本编辑器:Python解释器可以解释执行文本内容,可以识别Python语法,而文本编辑器就是看一下文本内容,也识别不了语法。
字符编码。
发展:
计算机在🇺🇸发明,发明时为了要让计算机用0101这样的二进制理解他们的语言,创建了编码表,ASCLL编码,用数字与当时🇺🇸的英文字母与字符一一对应。因为当时字符比较少,只有一百多个字符,所以ASCLL编码只用了八位来表示(一个字节),2的8次方等于256,所以ASCLL编码最多可以有256个字符。
后来,各个国家都用上了计算机,但是每个国家的字符都不一样,字符数量也不一样,比如咱们国家有好几万个字符,ASCLL码的极限256个完全满足不了中国字符的要求。所以中国就单独出了一个编码表叫GBK,和我们国家的字符进行一一对应。其他国家,比如日本(shit表)、韩国(fuck表)也有自己各自不同的编码表。
每个国家都有自己的一套编码表,国家之间要进行交流的时候发现,因为计算机编码不同,从而也看不了其他国家做出来的软件。为了解决这个问题,unicode应运而生。
unicode编码表集合了全世界各个国家的字符,将这些字符与数字一一对应。于是就出现了一套全世界各个国家都能用的编码表。ASCLL编码是一个字节,unicode是两个字节。针对于中国的生僻字,可以有四个字节。GBK有两个字节。
这时候乱码问题就没了,随之而来的又出现了另外一个问题。因为英文字符只需要一个字节就可以表示,这时候如果使用unicode,则需要两个字节,这就浪费内存空间了,这个问题不是最关键的,英文unicode需要使用两个字节,进行输入输出的时候就要比使用ASCLL编码的机器,时间上要多出两倍,从而效率也降低了一半。为了解决这个效率问题,又出现了另一种编码表UTF-8。
UTF-8编码是把unicode编码转化成了可变长编码。使用英文字符的时候,UTF-8就是一个字节,使用中文字符的时候通常是三个字节。如果你的文本中包含了大量的英文字符,使用utf-8就是极大的节省空间。
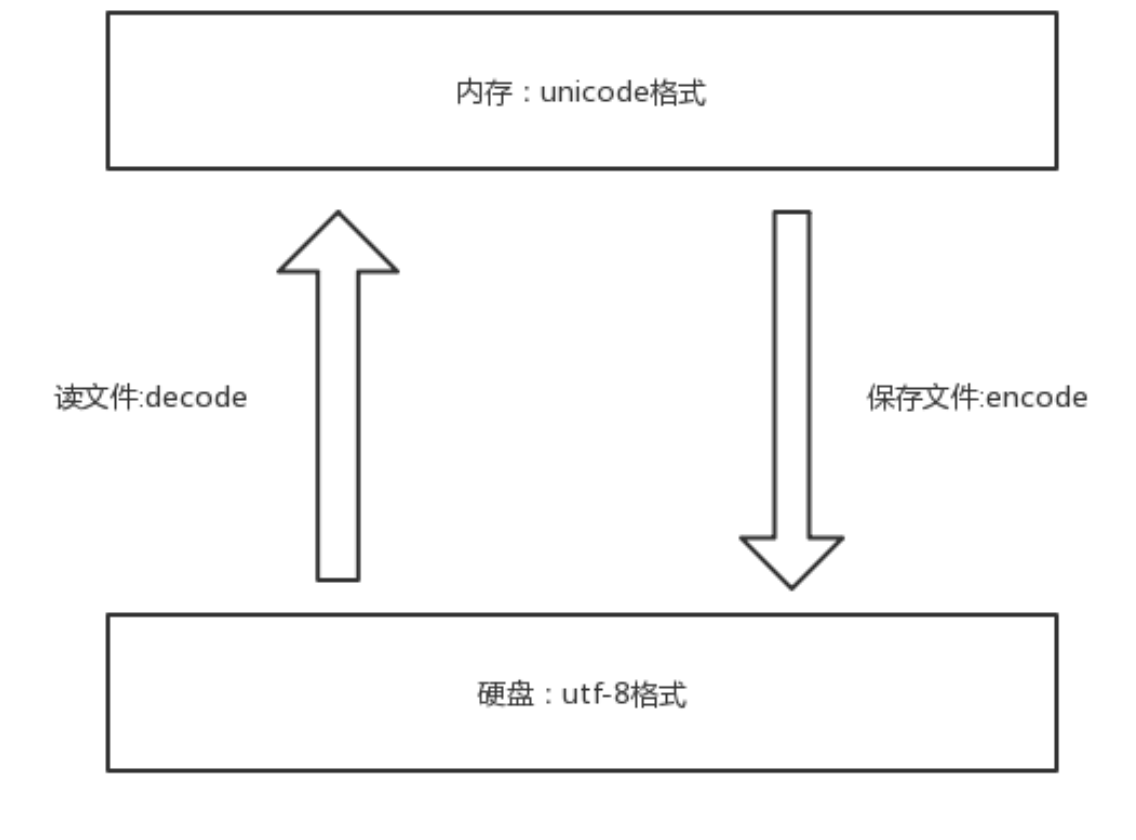
很多老软件依然会使用各种各样的编码,运行软件的时候是把软件的内容刷到内存中的,面对硬盘中各种各样的编码软件,想让我们的计算机能够兼容所有的编码,在软件运行时要不出乱码正常运行,在内存中必须有一种兼容万国的编码,就必须使用到unicode。
基于现状,在内存中,编码就固定是unicode了。但是,我们不能用unicode编码来编写程序的文件,因为如果你写的文件都是英文的话,在文件读入内存或是写入硬盘的时候,就会徒增IO次数,降低执行效率。所以这时候,我们需要utf-8来进行读写。
在文件读入内存或者写入硬盘的时候,要使用utf-8编码。内存中的编码就固定是unicode。
python2与Python3解释器编码的区别:
将test.py文件以GBK保存的时候,无论用python2来运行,或者是Python3来运行,都会报错。因为python2中默认使用的是ASCLL编码,因为当时Python在创建时,unicode还未出生。在python3中默认使用的是utf-8编码。要想不报错,除非在文件头使用 # coding:GBK
使用python3运行gbk文件时:

使用python2运行GBK文件时: 
总结:
保证不乱吗的核心法则就是,字符按照什么标准而编码的,就要按照什么标准解码
比如文件保存是用gbk编码保存到硬盘的,将文件解码刷到内存中显示时,就要使用GBK解码。不然就会乱码
内存中统一使用的都是unicode编码。 编码,就是把在内存中的unicode编码,编码encode成你想要的编码形式如utf-8/日本的shift编码保存在硬盘中。要打开文件的时候,
就需要使用文件对应的编码进行解码,解码成unicode刷到内存中进行展示。
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器 如果服务端encode的编码格式是utf-8, 客户端内存中收到的也是utf-8编码的结果。
内存的编码使用unicode,不代表内存中全都是unicode,程序执行的时候可能会创建字符,这个字符就可能是其他编码
当python解释器执行到产生字符串的代码时(例如s=u'林'),会申请新的内存地址,然后将'林'以unicode的格式存放到新的内存空间中,所以s只能encode,不能decode
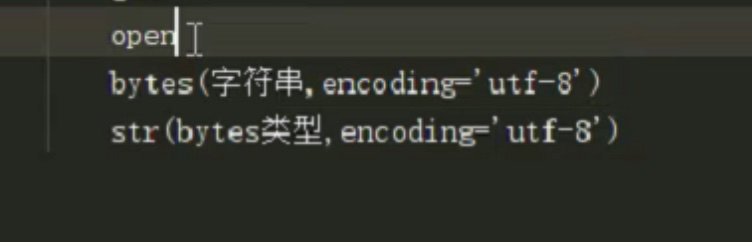
str.encode('utf-8') 将unicode编码转为utf-8编码的二进制文件可以存储到硬盘中
针对二进制文件: decode('utf-8') 将utf-8编码的二进制文件从硬盘中解码成unicode,可以刷到内存中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号