
谈谈raft fig8 —— 迷惑的提交条件和选举条件
谈谈raft fig8 —— 迷惑的提交条件和选举条件
前言
这篇文章的思路其实在两个月前就已经成型了,但由于实习太累了,一直没来得及写出来。大概一个月前在群里和群友争论fig8的一些问题时,发现很多群友对fig 8是充满了迷惑的。我个人在做lab的时候也对fig 8的问题感到非常头疼,真正大概理解这个问题的来龙去脉(大概?)的时间大概是两个月前复习raft的时候,而此时距离我做完lab已经足足一年有余了......这个问题难于理解,其实raft的作者要至少背一部分锅的——2014年的论文里,对于这个问题的讨论不是很充足,很多该回扣的点并没有回扣到。我这里尝试按照我自己的理解,梳理一下fig 8问题的原因。如果你想要看懂这篇文章,请至少把raft的论文完整的读几遍,如果懂basic paxos再好不过了,因为理解了basic paxos对于理解fig 8的问题非常有帮助。
迷惑的提交条件
如果一个操作得到了提交,那么相当于系统给出了一个保证:只要是这个系统是能推进的,那么这个操作日志迟早会被apply。如果日志能够提交,这条日志必须要满足某些条件,在满足了所有的条件的瞬间,这条日志的状态就是已提交的,即使它的index高于commitIndex。
那么细化来说,这些条件是什么呢?对于数据库中的事务,提交条件是该事务所有的WAL Log均已落盘;对于Percolator式的分布式事务,提交条件是Primary成功提交;但是对于Raft中的日志呢?如果回顾论文你可能会比较惊讶,直到讨论fig 8的问题之前,作者似乎都回避了这个问题,只是一味的说,日志只要成功备份到了Majority上,就提交它。初次阅读论文时,我们潜意识中便隐隐约约的埋藏了这样一个先入为主的错误认知——只要日志备份到了Majority上,就可以提交它,连带着提交这条日志之前的所有日志。然后论文来到了5.4,作者开始打我们的脸,告诉了我们日志的真正提交条件:要么被连带提交,要么只能提交一条term == leader.term的日志。
读到这一部分,你只需要知道,在raft算法中,日志真正的提交条件为,要么被连带提交,要么只能提交一条term == leader.term的日志,就可以了。如果日志不满足这个提交条件,那么它被截断是合理的。
迷惑的选举条件
现在让我们先忘掉raft日志的提交条件,先梳理一下raft算法的部分基本规则:
- 采用逻辑时钟term,一个term内至多有一个leader,candidate之间通过选举算法竞选leader;
- 日志流是单向的,只允许日志从leader流向follower;
- 对于日志冲突的场景,直接截断follower不匹配的日志,替代以leader的日志;
综合2和3,我们不难发现,leader必须要拥有所有commitable的日志;根据2,leader是无法从其他机器上学习到它缺失的commitable的日志的,根据3,leader可能截断那些commitable的日志。而根据1我们可以知道,leader当选的充分必要条件为它在那个term内得到了Majority的选票。
现在让我们来审视选举算法。论文中定义了candidate与follower间比较日志新旧的方法:
Raft determines which of two logs is more up-to-date by comparing the index and term of the last entries in the logs. If the logs have last entries with different terms, then the log with the later term is more up-to-date. If the logs end with the same term, then whichever log is longer is more up-to-date.
比较最后一条日志,到底谁最up-to-date。如果candidate更加up-to-date,且其他更优先的条件均已满足(term不超过leader,尚未投出票等等),那么follower会投票给candidate。
算法看似很自然直观,但你会发现,这和我们之前所强调的,当选的leader必须拥有所有commitable的日志这一条件,似乎并不存在一个包含关系,假设存在一个Majority认定candidate的日志更加up-to-date,那个这个candidate真的拥有所有的commitable的日志吗?
既然我们提到了commitable的日志,那么肯定要讨论commitable的条件是什么。现在让我们成为那个当开始读论文的初学者,根据论文前文,理所应当的认定那个先入为主的条件吧(也就是说,令日志的commitable的条件为日志“已经备份到Majority上”),看一看fig 8的场景(终于到fig 8了,泪目):
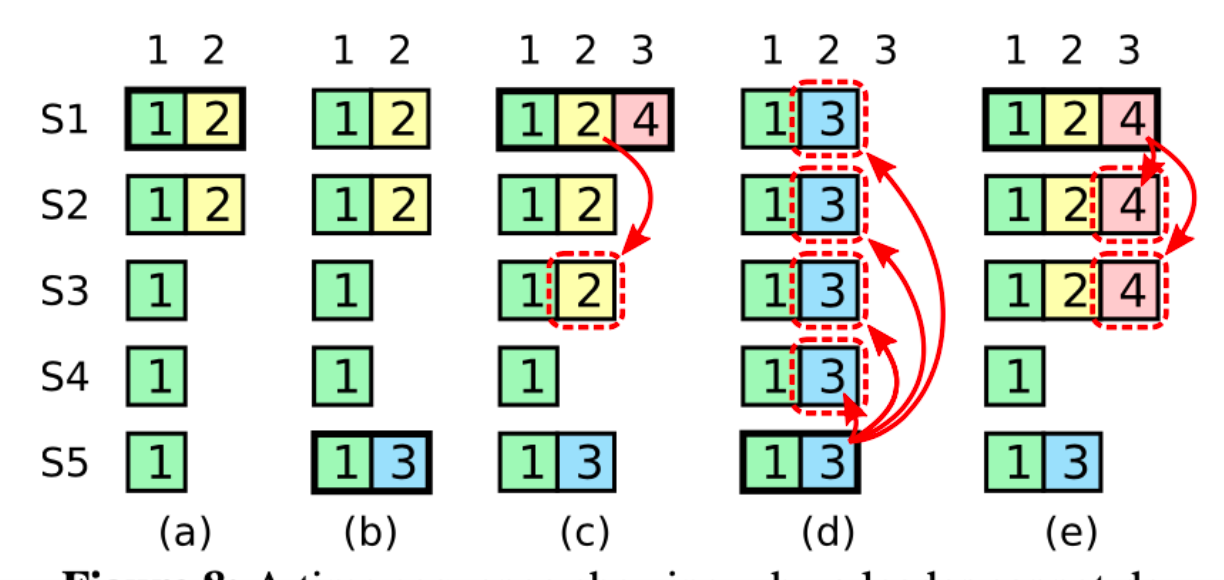
在fig 8的c阶段,s1是term = 4的leader,它先将(index = 2, term = 2)的日志备份到了{s1, s2, s3}上。根据我们所认定的那个commitable条件,既然(index = 2, term = 2)的日志成功备份到了Majority上,那么这条日志就是commitable的,当前日志的commitable集合为{1, 2}。到了d阶段,s5的日志相比于{s2, s3, s4}来说都是more up-to-date的,因此它能得到多数派的投票,成为term 5的leader,但当它成为了term = 5的leader的那一刻它开始了背刺行为:它截断了index = 2的日志,而这条日志是commitable的。究其原因,是因为在d阶段中,commitable的日志集合为{1, 2},而s5并不持有2,因此s5并不持有全部的commitable的日志。
总的来说,在commitable条件设定为“备份到了Majority上”的场景下,我们的选举算法无法满足最核心的那个约束:当选的leader必须持有全部commitable的日志,这正是5.4 safty所讨论的安全性问题。
两个月前当终于想到了这些东西时,我的第一反应就是去谴责那个该死的选举算法,选leader这么重要的算法居然无法满足这么重要的约束条件,那么这个算法就未免太寒颤了。但我很快发现这还真的不是个我行我上的问题:在一轮拉票的过程中仅涉及到了candidate和follower,这两个server间的交互,一次交互你还能指望candidate得到多少的信息呢?而在完全异步的网络环境下,即使是能和一个Majority进行交流,又能做到多少的事情呢?
补日志or加强提交约束?
补日志
我们用精确的语言描述一下fig 8的错误场景:
在commitable的条件为“备份到了Majority上”的场景下,使用现存的选举算法,无法保证当选的leader持有所有commitable的日志,导致commitable的日志存在被截断的风险。
我们不妨先把思维发散一下:既然当选的leader不保证持有全部commitable的日志,那缺啥补啥呗!先把所有commitable的日志补全,再去ReplicateLogs,不就可以了吗?既然现在commitable的日志已经备份到了Majority上,那我只要和任意一个Majority取得联系就肯定能获得commitable的日志!诶等等这样的话选举算法的more-up-to-date貌似意义不大了,反正日志会补全,那保证单主就可以了吧!诶等等如果我们把这个联络Majority的过程普及化,任意一个index处的日志,都要先联络到Majority协商好这个index处写什么日志,再去写下这个日志,这样的话单主的约束也可以去掉,因为每个主都要先和Majority取得联系,那么它们必定会有交集,获悉到其他主想写的日志!
恭喜你,你已经进入了basic paxos的大门。basic paxos解决的是多个机器对单个Value的共识问题。basic paxos中,也存在一个全局单增的逻辑时钟proposeId。proposer们不能随便的提议Value,在提议Value之前,它们必须要和Majority取得联系,要求它们拒绝一切proposeId < myProposeId的提案,同时,如果Majority中有部分机器已经accept了一个Value(这个Value可能就是已提交的结果),这个proposer就要考虑自己是否需要将自己的提案改成那个Value。这个过程被称为basic paxos的Prepare阶段(basic paxos的第二个阶段为Accept阶段,这里不讨论它)。现在将Value改成单条日志,对单条日志进行Prepare阶段,如果这条日志已经被提交了,那么proposer就可以学到这条日志!对所有的日志均走一遍basic paxos流程,就可以保证所有的日志是一致的,这就是最朴素的multi paxos思想,实际的multi paxos方法会复杂很多,存在着大量的优化。
虽然提到了paxos,但你完全不必去担忧上述那段文字你无法理解。我这里仅仅是想表达一个观点,解决fig 8里的问题,方法不止一种,而raft采用了非常精彩的办法。在raft的一些变种中,也存在着融合paxos思想的方案,例如说PolarFS的Parallel Raft,不需要leader持有全部commitable的日志,只需要leader有最新的checkpoint就可以了,leader上任后,通过merge阶段补全所有日志,这个merge阶段其实就非常类似于paxos的perpare阶段。
不管怎样,先补全commitable的日志,再去ReplicateLogs是一个解决fig 8中所描述问题的方法。值得注意的是,这种方案下,日志commitable的条件仍然是“备份到Majority”上就可以了。如果有人问你,为什么paxos将日志备份到Majority上就可以提交,而raft这样做就要在fig 8上吃瘪,你就可以告诉他,因为paxos的proposer可以通过prepare阶段补全日志。关于paxos算法此处不再讨论,如果想要更详细的了解paxos算法务必阅读《paxos made simple》这篇论文。
加强提交约束
再次回顾一下fig 8中的错误场景:
在commitable的条件为“备份到了Majority上”的场景下,使用现存的选举算法,无法保证当选的leader持有所有commitable的日志。
raft的办法是,将commitbale的条件进行加强:日志要么被连带提交,要么只能提交term = leader.term的日志。如果leader能够提交一条自己term内的日志,毫无疑问,这条日志之前的所有日志均是一致的。
现在再看一下fig 8:
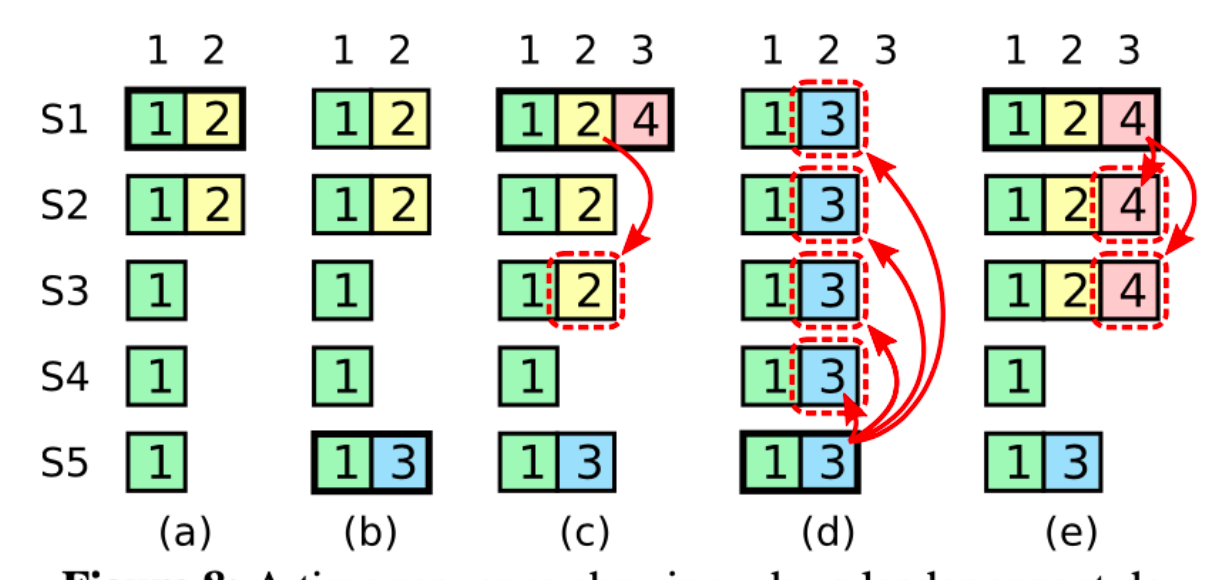
将commitable的条件强化为“日志要么被连带提交,要么只能提交term = leader.term的日志”之后,无论是d还是e,均是允许的,因为index = 2的日志并不满足commitable的条件,所以这条日志不会被c中的s1提交,客户也收不到ok的结果,会一直等待,所以在图d中截断它是允许的。但这个个例并不是重点,真正的重点是,在这样的commitable条件下,“leader必须持有全部的commitable的日志”这一约束条件是满足的!我个人尝试着做了一下证明,放在了文章的末尾。
nop entry的引入
原论文中提到了nop entry。raft作者建议任何leader在上台后,先不要急着响应客户请求生成操作日志,而是先提交一条自己term内的nop-entry,成功提交后,nop entry之前的所有日志就保持了主从一致了,此时再响应客户服务。
nop entry的引入其实还解决了一个更加棘手的问题:在提交条件被强化后,如果新的leader上台后,迟迟不生成新的日志,那么leader就无法提交那些它已经成功备份到Majority,但term < leader.term的日志。
尽管如此,我个人强烈不建议在6.824里引入nop。因为nop也是要占据logIndex的,后台的测试代码会对每个index的日志进行校验。nop并不是测试代码添加的,因此测试代码在匹配index时会报错。在6.824里,无需考虑也不能考虑leader无法显示提交日志导致进度得不到推进的场景。
总结
关于fig8的讨论就到这里了。我们再次梳理一下原论文中的一些比较坑的点。首先是fig 8中场景d的正确性。在commitable的条件为"备份到Majority上即可"时,a → b → c → d是错误的,因为c中index = 2的日志成功备份到了Majority上,commitable的集合为index = {1, 2},index = 2的日志不允许被截断。当commitable的条件为“日志要么被连带提交,要么只能提交term = leader.term的日志”时,a → b → c → d是正确的,因为在c中,index = 2 的日志term不等于s1的term,因此s1并不会提交它,所以到了d时,commitable的集合仍然是index = {1},所以d可以截断index = 2的日志。
为什么我们要强化提交条件?因为我们在raft算法的设定下,我们必须要保证leader必须持有全部的commitable的日志"这一条件,而选举算法无法保证这样的leader当选,为此,要么让leader在ReplicateLogs前补全所有commitable的日志,要么另辟蹊径。raft的解决办法是强化了提交条件,在这个提交条件下,选举算法所选出的leader必定持有全部的commitable的日志。
前文中我提到“raft作者要为fig 8难以理解背一部分锅”,也很大程度上是因为作者没有对fig 8出现的根本原因进行讨论,在提出加强提交条件后也没有用文墨去回扣到选举条件上。
关于提高约束条件后算法正确性的证明
证明算法正确,等价于证明将commitable的约束条件提升至"日志要么被连带提交,要么只能提交term = leader.term的日志",后,当选的leader必定持有全部的commitable的日志。可以用反证法,下文是我自己的证明,个人不保证证明是正确的,毕竟人菜瘾大(
反证法
(1) 令TL是最后一次保持约束条件且成功commit了日志的leader,TL的最后一条commitable的日志index为c_index,term为c_term,假设在TL之后的第一个错误leader为FL,即第一个不持有全部的commitable的日志,但仍然成功当选的leader。(TL.term, FL.term)间可能存在0个或者多个leader,这些leader进行过ReplicateLog,但没能成功commit任何新的日志,也正是因此,在这期间c_term和c_index是不变的。
(2) 根据假设可知FL ∉ Majority_1。根据TL的定义可知,集群中必定有一个Majority_1,它们都持有这些commitable的日志。令TL的最后一次提交时,TL的term为commit_term。根据当前的commitable条件,有commit_term == c_term。
(3) 根据投票算法我们可知,存在一个Majority_2认为FL的日志是more up-to-date的。这只有两种可能:要么FL.last_log.term == c_term,但index更高,要么虽然FL.last_log.index < c.index,但FL.last_log.term > c_term。第一种情景是不可能的,因为这样的机器只能出现在Majority_1中,这与我们的假设矛盾,
(4) 考虑第二种场景,如果FL.last_log.term == FL.term,那么这条日志是FL自己添加的,因此它不可能靠这个日志去赢得选举,这条日志只能是来自于之前term的leader。因此到了这里我们得到了一个恒等式:TL.term == commit_term == c_term < FL.last_log.term < FL.term。
(5) 根据这个不等式可知,存在一个before_leader,它是term为 FL.last_log.term时刻的leader,它给自己添加了一条/几条日志,还没来得及commit就step down了。根据(4) 中FL.last_log.term > c_term == commit_term == TL.term可知,before_leader 的当选时刻是在TL成功的commit之后;又根据我们对TL的定义可知,before_leader肯定是一个持有全部commitable日志的leader(但它并没有成功commit更多的日志,否则要将它归于TL),因此before_leader在生成日志(FL.last_log.term, FL.last_log.idx)时,必定是持有所有的commitable的日志的,且FL.last_log.index > c.index (新日志是append进来的)。对应的,既然FL.last_log之前的日志来自于before_leader(复制条件),那么它们的日志在这之前应该一致,因此FL必须有这些commitable的日志,这与我们的假设相矛盾。综上所述,我们的假设均被否定,结论得证。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号