
记一个关于std::unordered_map并发下rehash引起的的BUG
前言
刷题刷得头疼,水篇blog。这个BUG是我大约一个月前,在做15445实现lock_manager的时候遇到的一个很恶劣但很愚蠢的BUG,排查 + 摸鱼大概花了我三天的时间,根本原因是我在使用std::unordered_map做并发的时候考虑不周。但由于这个BUG无法在我的本地复现,只能提交代码后再gradescope上看到执行日志,而且打印的日志还不能太多,因为gradescope的执行比较慢,打印日志如果稍微多加一点就会报TIMEOUT,所以着实让我抓狂了一段时间。最后的解决也很突然,非常有戏剧性,可以考虑拿来水点东西。感觉自己写blog很拖刷leetcode和背八股的节奏,所以找到实习前可能写不了太多了。
功能描述
15445 Project4要求我们为bustub添加并发访问控制,实现tuple粒度的strict 2PL。简单来说,一个RID表示着一个tuple在磁盘上的位置,因此可以唯一标识tuple;一个事务就是一个线程。事务会并发的对这些tuple进行读写访问,因此必须要引入lock来对访问进行同步,而这个Project要求我们将lock的粒度设定为tuple。为了实现这一点,bustub设定了一个单例的LockManager(但其实现方法并不是单例的),要求任何事务在访问某个RID之前,都要向这个LockManager申请锁。如果事务进行的是读访问操作,要调用LockManager的lock_shared方法申请S-LOCK(共享锁,或者说读锁),否则操作就是写操作,要调用lock_exclusive方法申请X-LOCK(独占锁,或者说是写锁);如果事务已经获取了S-LOCK,希望在不释放S-LOCK的情况下将锁升级为X-LOCK,则要调用lock_upgrade方法。此外,由于strict 2PL只能保证Serializable Schedule,但无法保证不存在死锁,因此LockManager还需要实现死锁检测功能(但这不是本篇blog的重点)。LockManager的声明如下:
class LockManager {
enum class LockMode { SHARED, EXCLUSIVE, UPGRADE };
enum class RIDLockState { UNLOCKED, S_LOCKED, X_LOCKED };
class LockRequest {
public:
LockRequest(txn_id_t txn_id, LockMode lock_mode)
: txn_id_(txn_id), lock_mode_(lock_mode), granted_(false), aborted_(false) {}
txn_id_t txn_id_;
LockMode lock_mode_;
bool granted_;
bool aborted_;
};
class LockRequestQueue {
public:
LockRequestQueue() = default;
LockRequestQueue(const LockRequestQueue &rhs) = delete;
LockRequestQueue operator=(const LockRequestQueue &rhs) = delete;
// DISALLOW_COPY(LockRequestQueue);
RIDLockState state_;
std::mutex queue_latch_;
std::list<LockRequest> request_queue_;
std::condition_variable cv_; // for notifying blocked transactions on this rid
bool upgrading_ = false;
};
public:
/**
* Creates a new lock manager configured for the deadlock detection policy.
*/
LockManager() {
enable_cycle_detection_ = true;
cycle_detection_thread_ = new std::thread(&LockManager::RunCycleDetection, this);
LOG_INFO("Cycle detection thread launched");
}
~LockManager() {
enable_cycle_detection_ = false;
cycle_detection_thread_->join();
delete cycle_detection_thread_;
LOG_INFO("Cycle detection thread stopped");
}
/*
* [LOCK_NOTE]: For all locking functions, we:
* 1. return false if the transaction is aborted; and
* 2. block on wait, return true when the lock request is granted; and
* 3. it is undefined behavior to try locking an already locked RID in the same transaction, i.e. the transaction
* is responsible for keeping track of its current locks.
*/
/**
* Acquire a lock on RID in shared mode. See [LOCK_NOTE] in header file.
* @param txn the transaction requesting the shared lock
* @param rid the RID to be locked in shared mode
* @return true if the lock is granted, false otherwise
*/
bool LockShared(Transaction *txn, const RID &rid);
/**
* Acquire a lock on RID in exclusive mode. See [LOCK_NOTE] in header file.
* @param txn the transaction requesting the exclusive lock
* @param rid the RID to be locked in exclusive mode
* @return true if the lock is granted, false otherwise
*/
bool LockExclusive(Transaction *txn, const RID &rid);
/**
* Upgrade a lock from a shared lock to an exclusive lock.
* @param txn the transaction requesting the lock upgrade
* @param rid the RID that should already be locked in shared mode by the requesting transaction
* @return true if the upgrade is successful, false otherwise
*/
bool LockUpgrade(Transaction *txn, const RID &rid);
/**
* Release the lock held by the transaction.
* @param txn the transaction releasing the lock, it should actually hold the lock
* @param rid the RID that is locked by the transaction
* @return true if the unlock is successful, false otherwise
*/
bool Unlock(Transaction *txn, const RID &rid);
/**
* Checks if the graph has a cycle, returning the newest transaction ID in the cycle if so.
* @param[out] txn_id if the graph has a cycle, will contain the newest transaction ID
* @return false if the graph has no cycle, otherwise stores the newest transaction ID in the cycle to txn_id
*/
bool HasCycle(txn_id_t *txn_id);
/** @return the set of all edges in the graph, used for testing only! */
std::vector<std::pair<txn_id_t, txn_id_t>> GetEdgeList();
/** Runs cycle detection in the background. */
void RunCycleDetection();
private:
std::unordered_map<txn_id_t, std::vector<txn_id_t>> BuildTxnRequestGraph();
std::mutex latch_;
std::atomic<bool> enable_cycle_detection_;
std::thread *cycle_detection_thread_;
/** Lock table for lock requests. */
std::unordered_map<RID, LockRequestQueue> lock_table_;
/** Waits-for graph representation. */
std::unordered_map<txn_id_t, std::vector<txn_id_t>> waits_for_;
};
目前你只需要知道这个,为了同步多个线程(事务)的并发访问,线程会调用单例的LockManager中的lock_shared、lock_exclusive、lock_upgrade方法来获取锁,而锁的粒度是RID级别的就可以了。Project4 Part1的要求就是让我们实现上述三个方法。
设计与实现
具体的实现思路不难。我们先看一下LockManager的核心数据结构lock_table_,它实现了从RID到LockRequestQueue的映射,所有的事务在为某个RID申请lock时,必须将自己的请求构建一个LockRequest结构,插入到这个RID对应的LockRequestQueue里面,等待自己的请求被执行。图例如下:
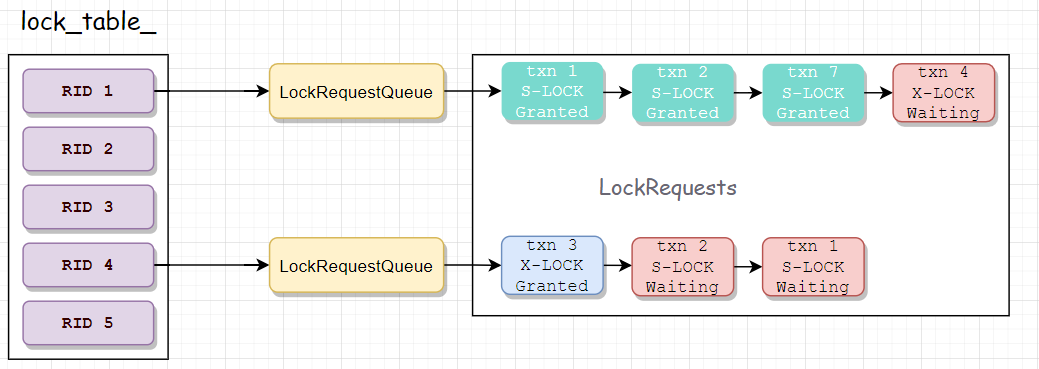
本图中共有5个RID,理所应当有5个LockRequestQueue,这里为了简便起见我只画了其中的两个。上图中有四个事务(1,2,7,4)申请RID 1的锁,三个事务(3,2,1)申请RID 4的锁,请求到来的顺序、授予锁的顺序都是FIFO。由于RID 1的前三个请求都是S-LOCK,因此这把S-LOCK可以被授予给三个事务,而第四个事务(txn 4)的X-LOCK请求则被阻塞;
能画出这个图之后,相应的代码也不难实现了,这里我以伪代码的形式给出lock_shared的逻辑,lock_exclusive和lock_upgrade的逻辑都很类似,故不再给出,我所想讨论的BUG也在下面的代码里面:
bool LockManager::LockShared(Transaction *txn, const RID &rid) {
// Assertions for transaction state, isolation level and so on.
......
// BUG IS HERE!!!!!!
latch_.lock();
if (lock_table_.find(rid) == lock_table_.end()) {
// INSERTION MAY HAPPENDS HERE!
lock_table_[rid].state_ = RIDLockState::UNLOCKED;
}
// block other txns' visit on this rid,then we could saftly release latch_
std::unique_lock lk(lock_table_[rid].queue_latch_);
latch_.unlock();
// BUG IS HERE!!!!
LockRequest req = MakeRequest(txn->id, LOCK_SHARED);
lock_table_[rid].queue_.emplace_back(req);
auto req_iter = --lock_table[rid].queue_.end();
// waiting on condition_variable
while (wait(lock_table_[rid].queue_.cv_, lk)) ....
// Success, return
lk.unlock();
return true; // unlock the queue
}
lock_table_是一个std::unordered_map<RID, LockRequestQueue>,最开始的时候是空的,当出现一个新的RID时,会向这个unordered_map中添加一对新的 (RID, LockRequestQueue)的Pair。这是一个对unordered_map的写操作,而unordered_map并不是线程安全的,如果多个线程同时调用lock_shared去获取同一个RID的锁,而这个RID之前并不在lock_table_里,那么lock_table可能就会并发的插入同一个RID,这是非常危险的操作!!!我们必须避免这一情景,通常的方法是在可能引入插入的操作之前,获取latch_来保证单线程对lock_table_的访问操作:
// BUG IS HERE!!!!!!
latch_.lock();
if (lock_table_.find(rid) == lock_table_.end()) {
// INSERTION MAY HAPPENDS HERE!
lock_table_[rid].state_ = RIDLockState::UNLOCKED;
}
// block other txns' visit on this rid,then we could saftly release latch_
std::unique_lock lk(lock_table_[rid].queue_latch_);
latch_.unlock();
正如前文所述,由于operator []的使用可能会引入插入操作,因此这里我用latch_.lock()来隔绝其他线程对lock_table_的访问操作,这样可以避免多个线程对同一个RID同时进行插入操作的情景,当lock_table_[rid].state_ = RIDLockState::UNLOCKED;这行代码执行完毕后,这个RID的KV Pair已经存放在了这个unordered_map里面,然后我们拿到更细粒度的锁lock_table_[rid].queue_latch_,就可以释放掉latch_了,因为虽然后续的代码会访问lock_table_里的LockRequestQueue,但由于对应的RID均已经存在,因此这些操作应该看做是对lock_table_的读操作;虽然这个过程中会有新的RID插入,但不应该会对这些已经存在的RID产生影响(这里是我的第一个疏忽),因此无需关注。而那些针对LockRequestQueue的读写操作,由更加细粒度的锁LockRequestQueue.queue_latch_来提供同步,而其在latch_释放之前就已经被获取了,因此也不存在并发问题。
可以看到,这段代码是非常stupid的,因为当初为了写的快一点,我大量的使用了lock_table_[rid]来获取LockRequestQueue的引用,而operator []的操作并不是常量级的,这会引入非常多的开销(本意是测试通过之后再修改)。更重要的是这里是我的第二个疏忽,正是前后这两个疏忽造成了BUG。
BUG产生情景
在完成编码后我在本地跑了上千次测试,都可以完美PASS测试样例,但当我把代码提交到gradescope时却失败了,提示某些请求一直没有得到调度导致超时了。于是我在代码里加了点小trick,把调度失败时lock_table_的状态打印出来,于是产生了下面的日志:
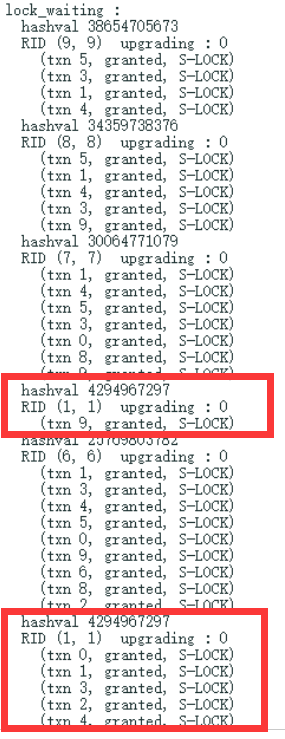
先解释一下日志的输出。一个RID可以由一个二元组(page_num, slot_num)唯一表示,一个请求可以由三元组(txn_id, is_granted, lock_type)表示。我希望通过前文所述的二元组和三元组展示一下LockManager中锁调度的状态。上图中(txn 5, granted, S-LOCKED)表示事务5申请了RID(9, 9)的S-LOCK,且lock_manager已经将S-LOCK授权给了它。
注意到这个日志里有两个 RID(1, 1),且它们的hashval是一模一样的,这说明std::unordered_map中出现了两个同样的键!。我后面又多次提交代码查看lock_table_的状态,但都获得了类似的结果,即std::unordered_map中总是会有两个相同的键,或者说,拥有同样的hasval的键被分到了两个bucket中,而我们通过下标访问lock_table_[rid]时,至多只能访问到其中的一个bucket,因此也只有这个bucket中的LockRequest可能被调度,而另一个bucket由于无法被访问到,因此其中的请求就可能永远都不会被调度了,这就导致了测试代码的超时。
我们知道,std::unordered_map通过Key获取对应的Value的规则是首先计算这个Key对应的hashval % bucket_num获取得到K-V对所在的bucket,虽然不同的Key会有不同的hashval,但他们可能会有相同的hashval % bucket_num,因此可能会被放入到同一个bucket中;为了从bucket中找到唯一的K-V对,又需要调用operator ==来找到唯一的目标Key;因此发现这个BUG后,我第一个想法就是RID的实现可能存在问题,于是去仔细查看了RID的operator ()方法和operator ==的实现,然后打消了这个念头。其实前文中我也提到了,我在日志中打印了RID对应的hashval,两个键的hashval都是一样的,却在不同的bucket中,这种情景基本不可能是operator ()方法和operator ==实现错误所能触发的、
【世界名画之:我代码错了,肯定是XXX的问题】
然后我又考虑是不是因为我前面试图降低锁粒度的方法存在问题,但用纸笔模拟了多种情景、又拿状态机之类的理论推导了一下,最终也宣告了我的怀疑破产。
这样一来我的思路就完全断掉了,于是我希望能获取到更多的这个BUG产生时的程序上下文信息。由于测试代码只涉及到了10个RID,而这种情况出现时,lock_table_的size会膨胀到11,因此这个时机可以作为一个排查BUG、获取当前lock_table_状态的切入点,因此我又往自己的代码里添加了一系列的逻辑,边打印日志边准备捕获这个瞬间,但测试代码又被TIMEOUT了,因为gradescope的执行速度比较慢,打印太多日志会导致超时,拿不到我想要的东西。
这样一时间我的调试就陷入了僵局,我猜不到这个BUG产生的可能原因,无法在本地复现这个BUG,甚至无法通过日志的方式获取到更多的信息。
BUG的解决
这个BUG的解决也很富有戏剧性,大概有两天我的思路没有进展,直到第二天晚上偶然打开cppreference时注意到了std::unordered_map的一个之前没注意到的细节:rehash。最初始时,std::unordered_map最初一般只有7个bucket,但随着插入量的增长,同一个bucket中的元素越来越多,越来越多的时间会被花费在bucket内部的线性查找上,因此std::unordered_map会在适当时机进行扩容操作,增添bucket的数量,并将之前的k-v pair重新分配到其对应的桶中。
https://en.cppreference.com/w/cpp/container/unordered_map
我自己写了一点测试代码了解rehash的行为后,猜测可能是并发访问下rehash造成了std::unordered_map的undefined行为,但这种想法一旦成立,也就意味着我前文中降低锁粒度所思考的逻辑存在着严重的问题。验证方法也很简单,在lock_table_创建时,把桶的数量开到足够大,这样就不会出现rehash的情景了:
LockManager() {
enable_cycle_detection_ = true;
cycle_detection_thread_ = new std::thread(&LockManager::RunCycleDetection, this);
// reserve enough buckets to avoid rehash
lock_table_.reserve(100);
LOG_INFO("Cycle detection thread launched");
}
修改后再次提交到gradescope,顺利通过。这样基本石锤了时rehash导致lock_table中出现了两个相同的key;
BUG的分析
当然,我不能使用这种投机取巧的方法去过测试,我又重看了前面的lock_shared方法,很快发现了问题,这里我换一批注释:
bool LockManager::LockShared(Transaction *txn, const RID &rid) {
......
latch_.lock();
if (lock_table_.find(rid) == lock_table_.end()) {
// INSERTION AND REHASH MAY HAPPENDS HERE!
lock_table_[rid].state_ = RIDLockState::UNLOCKED;
}
std::unique_lock lk(lock_table_[rid].queue_latch_);
latch_.unlock();
LockRequest req = MakeRequest(txn->id, LOCK_SHARED);
// IF REHASH AND THIS LINE IS RUNNING AT THE SAME TIME, WHAT WILL HAPPEN ?
lock_table_[rid].queue_.emplace_back(req);
auto req_iter = --lock_table[rid].queue_.end();
// AND WHAT MAY HAPPEND HERE ???
while (wait (lock_table_[rid].queue_.cv_, lk)) ....
lk.unlock();
return true; // unlock the queue
}
错误已经很明显了,我在插入LockRequest前,使用了operator []来获取对应的LockRequestQueue的引用,本意是认为新的RID的插入并不会影响这一过程,但如果在operator []执行的过程中发生了rehash,那么 bucket_num的值就会发生改变(应该是从7变为11),而这个过程中,同一个hashval就可能被送到不同的bucket中,因此就产生了undefined behaviour。
那么这个BUG该如何解决呢?再次阅读cpp reference我们可以得知,rehash不会导致引用或者指针失效,因此我们可以在持有latch_的时候,直接获取到对应的LockRequestQueue的引用,以后只通过这个引用来访问LockRequestQueue,伪代码如下:
bool LockManager::LockShared(Transaction *txn, const RID &rid) {
......
latch_.lock();
if (lock_table_.find(rid) == lock_table_.end()) {
// INSERTION AND REHASH MAY HAPPENDS HERE!
lock_table_[rid].state_ = RIDLockState::UNLOCKED;
}
// acquire the reference of LockRequestQueue;
LockRequestQueue &queue = lock_table_[rid];
latch_.unlock();
// rehash does not invalid reference queue, so it's safe here.
std::unique_lock lk(queue.queue_latch_);
LockRequest req = MakeRequest(txn->id, LOCK_SHARED);
queue.queue_.emplace_back(req);
auto req_iter = --queue.queue_.end();
while (wait (queue.cv_, lk)) ....
lk.unlock();
return true; // unlock the queue
}
还剩下一个问题:在rehash的过程中,引用是否会失效?我个人查了查相关资料,没有找到对应的讨论情况。虽然我个人认为引用不会失效,但很明显我们不应该依靠这种侥幸心理来写代码,后续重构的时候我会像一个更好地方法来解决这个问题。
总结
std::unordered_map<Key, Value>是一个无法保证线程安全的数据结构,我们必须自己来处理它的并发访问。并发访问可以支持单个进程的写操作,或者多个进程的并发读操作。一般情况下我们可以把对Value的写操作,看做是一个对std::unordered_map<Key, Value>的读操作,因为这个操作并不改变Key与Value的映射关系。operator[]是一个十分需要小心使用的方法,因为它既可能对应一个读操作,也可能对应一个写操作,如果这个方法触发了插入行为,那么其中的元数据就会被修改,如果装载引子接近了上限值时还可能触发rehash,因此operator []不应该并发的调用。
这算是我个人遇到的最难受的BUG之一了,既没法在本地复现,又没法得到更多的信息。个人非常大的失误是不了解std::unordered_map的行为,并且在BUG定位的时候没能跳出逻辑圈。实际上,试图降低锁粒度对我这种经验很少的鶸来说,是非常危险的行为,因此我个人十分不建议在缺少全局分析、缺乏经验、没有足量的测试的情况下写并发代码,能单机解决它不香嘛(

 浙公网安备 33010602011771号
浙公网安备 33010602011771号