MIT 6.S081 聊聊xv6的文件系统(中)日志层与事务
前言
我本想把上篇中没讲完的剩余层全部在本篇中讲完,但没想到越写越多。日志层的代码不多,其思想和解决问题的手段也不算难以理解,但其背后涉及的原理和思想还是非常值得回味的,因此我打算用一整篇完整的blog来讲解日志层,并对其作出一点扩展。
本篇内容应该也会帮你对事务的拥有一个更好地理解。
聊聊xv6的文件系统(上篇):https://www.cnblogs.com/KatyuMarisaBlog/p/14366115.html
浅谈一致性
警告:
本节内容我越写越觉得自己是个民科,整出了一套四不像的东西来强行糊弄自己,如果觉得这部分内容辣眼睛的话就请跳过吧(留下了蔡鸡的泪水)
《xv6 book》中告诉我们,文件系统必须支持crash recovery,即文件系统在访问文件的过程中如果经历断电等情况,经过重启仍然能够正常工作。更加严谨的说法是,文件系统在面临崩溃等情况后,仍然能够保证一致性。这里的一致性可能与我们所预想的定义有所出入。为了能够正确的理解日志层为文件系统提供的作用,我们必须首先正确理解本文中所谈及的一致性的具体含义。
首先我们给出wikipedia上关于一致性的严谨定义:
The semantic definition states that a theory is consistent if it has a model, i.e., there exists an interpretation under which all formulas in the theory are true.
The syntactic definition states a theory T is consistent if there is no formula φ such that both φ and its negation 𠃍φ are elements of the set of consequences of T.
https://en.wikipedia.org/wiki/Consistency
将这个定义迁移到程序设计上,我个人给出我自己关于一致性的论述:对于一个系统M,定义其合法的操作集合P,并假设其当前状态为S,且一切的一致性约束条件都成立,如果经过操作p(p∈P)后状态转换为S’,且S’内部的一切约束性条件仍然成立,那么则称这个系统在操作集合P下能保持一致性。
现在将这个论述套用到文件系统上,设磁盘为我们的系统M,并设定对这个系统的操作集合P为xv6中的事务操作,设定一致性约束条件为磁盘的元数据能正确反映磁盘的状态,文件的元数据能正确反映文件的状态,这即是xv6文件系统的一致性模型。
这种定义可能比较拗口,既不像数学定义那样高度抽象且严谨,也没能做到让人容易理解。为了让这些定义更加形象一些,我们首先脑补一些可能会产生不一致状态的情景。
情景1:
假设释放盘块的操作的先后顺序为先置位图位为0,再将盘块的内容置零,且分配盘块时不再重置盘块的内容(因为认为释放盘块时空间已被置空了,无需重复操作),且没有日志层的支持。
考虑删除文件的操作。删除文件时,会将改文件所涉及的所有盘块一一释放。假设断电发生在置盘块bn的位图位为0后,将bn中的内容清零之前,然后系统重启,注意此时盘块bn的内容并没有被置空。如果这个盘块被分配了出去,则获得这个盘块的文件中就包含了前面那个文件被删除的数据,即脏数据,这一点便违背了一致性约束条件:文件的元数据必须能正确反映文件的状态。
当然我们有很多的办法可以避免这种情况,例如说盘块被分配时再执行一次清空操作、记录文件偏移值等等;
情景2:
仍然考虑删除文件的操作。阅读xv6的相关代码代码可知,文件系统通过struct inode实现对文件内容的读写,其中inode->addr记录着文件的内容所占据的盘块的盘块号(这将在下篇的inode层进行介绍)。如果删除操作是先释放掉存放文件内容的盘块,再将inode回写到inode区其对应的盘块上,且断电发生在盘块内容被删除后,inode被回写前,那么inode便索引到了一块内容已经被清空的盘块,这也违背了我们的一致性约束条件:文件的元数据必须正确反映文件的状态;
情景3:
位图在磁盘空间的分配和回收中担任着重要的角色,因此其可以被看做是磁盘的元数据。我们在魔改操作系统代码时,也可能会使得位图将一个已经被释放掉的盘块标注为已分配,或者将一个已经被分配出去的盘块标注为未分配。这种情况同样违背了我们的一致性约束条件:磁盘的元数据必须正确反映磁盘的状态。
了解前文中所提到的磁盘的一致性约束条件的具体内容后,我们接下来思考下文件的写操作的情景。一次写操作可能涉及到对inode的修改、对bitmap的修改、对data区盘块的修改等。原则上讲,我们必须保证文件的写操作p满足 p ∈ P,即完成文件的写操作后,所有其涉及到的盘块都需要被正确的修改(否则我们写的代码就是有bug的代码),这样磁盘的一致性状态可以在执行p后仍能保持。但文件系统仍然有一个大敌:崩溃。崩溃会使得操作p在执行的中间被打断,而不完整的p无法保证磁盘的一致性。
我们接下来通过几张图片来了解一下系统是如何进入不一致状态的。
系统为什么会进入不一致的状态?
导致系统进入不一致状态的原因可以分为三种:
1)对于一个现状态为不一致的系统执行任何操作p,无法预期操作完成后该系统的状态;

2)对于一个现状态为一致的系统,执行操作p(p ∉ P,即操作p无法保证执行后系统能保持一致性),系统可能会进入不一致的状态;

3)对于一个现状态为一致的系统,执行操作p(p ∈ P )的中间被打断,p中断执行;一个未完全执行的操作p很可能不属于P,这也可能导致系统进入不一致的状态;
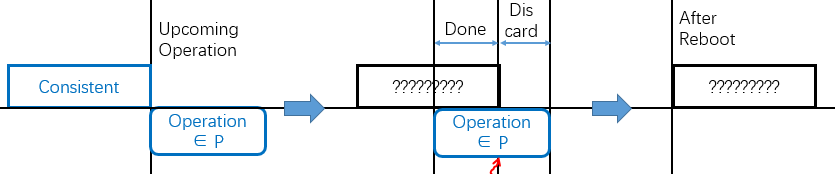
第一种情况不难理解;第二种情况可以这样设想:我们希望设计一个属于P的操作p,但由于我们的设计存在bug,导致我们实现的p’无法完成预期的功能,这样导致系统进入了不一致的状态,而不一致状态的系统的执行结果是无法保证的;第三种情况即对应着我们的断电重启情景。
唯一能够保证一致性的情景是,在系统处于一致状态时,完整的执行属于p的操作:

一致性协议的基本要求
理解以上情形后,我们就可以思考如何通过设计来保证我们的系统的一致性了,而使得系统能够保证一致性的设计与实现即为该系统的一致性协议。我们现在已经可以提出一致性协议的基本要求了:
1)必须保证我们系统的初始状态满足所有的一致性约束条件。这点是显然成立的;
2)必须保证该系统的所有操作op均满足 op ∈ P。xv6的代码组织可以保证这一点;
3)必须保证操作p的原子性,即p要么全部被执行,要么没有被执行;
根据前文中我们给出的一致性模型可知,只要实现了上述三点要求,即可保证我们的系统(磁盘)能够在保持一致性。xv6的日志层提供了事务(transaction)的抽象,其要求我们将对文件的写操作组织到事务中来完成。xv6的设计保证,事务的串行执行和并发执行都是符合我们的一致性协议的,即只要我们将文件的写操作组织到事务中,磁盘的状态必定能保持一致(磁盘的元数据能正确反映磁盘的状态,文件的元数据能正确反映文件的状态)。xv6关于事务的抽象与DBMS的事务十分相似,但其具体实现并不相同(DBMS要求事务能够实现回滚操作,而xv6的事务不需要实现回滚)。接下来我们通过代码来了解xv6的事务抽象与一致性协议的实现。
日志与事务
xv6的事务是通过日志的机制来支持实现的。一份日志就是一个脏块,这些脏块既包括文件的内容所对应的盘块,也包括一系列文件相关、磁盘相关的元数据盘块(例如说bitmap的盘块、inode的盘块等)。我们知道,一次对文件的写操作,可能会涉及到bitmap的改动、inode的改动等等,这些数据块都有可能变为“脏块”,xv6并不会直接将脏块回写到对应的磁盘上,而是会先将这些脏块的副本写入到磁盘的日志区。当一组事务相关的所有日志均已成功存储到日志区后,xv6会将logheader回写到磁盘的日志区,标明这批日志已经可以成功提交。
一批完整的、状态为可提交的日志完全囊括了一组文件写操作所涉及到的所有盘块的全部修改,因此如果在执行这组写操作前磁盘的状态是一致的,那么将这批日志中的块全部回写后,磁盘的状态必定仍会保持一致。概括的来讲,即事务的操作属于 P ,这样我们的一致性协议的前两条需求都可以保证。下面我们上手源码,来了解xv6中事务和日志的设计与实现。
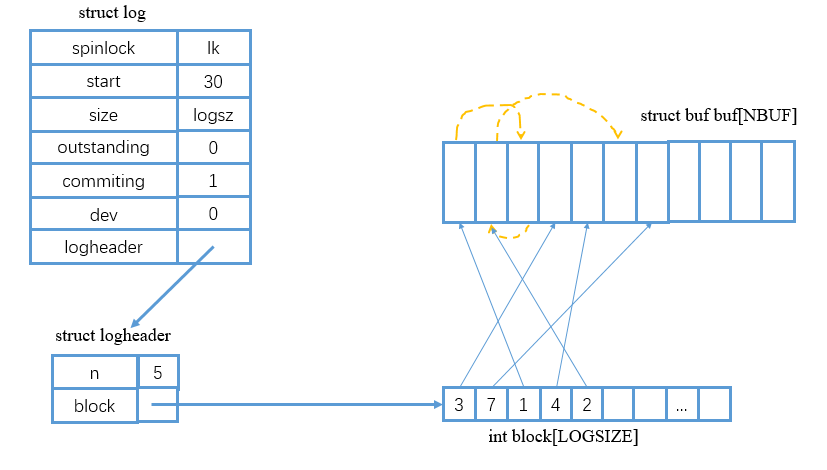
首先我们来看一下xv6中日志的数据结构:
struct logheader {
int n; // the num of logs (mark the length of array)
int block[LOGSIZE]; // the conresponding subscript of buf in buf array
};
struct log {
struct spinlock lock;
int start; // the log start at this block
int size; // the max log num
int outstanding; // how many FS sys calls are executing.
int committing; // in commit(), please wait.
int dev; // the dev num
struct logheader lh;
};
struct log log[NDISK];
struct log中有两个成员十分值得我们注意:outstanding和commiting。commiting标记着一批日志是否在进行提交操作,而outstanding标记着当前等待写日志的文件系统相关的系统调用个数。为了简化设计,xv6对日志的操作进行了一定的限制:1)当一批日志正在被提交时(log.commiting == 1),不接受新的日志;2)日志的提交被推迟到没有FS相关的系统调用时,即某个时刻如果有FS相关的系统调用在使用日志的话,则推迟提交这批日志,这个时刻对应的log.outstanding != 0。这也同时意味着,所有FS相关的系统调用产生的日志不会被分散提交,而是必定一次性全部提交。
下图可能能够帮你更好地观察到日志与缓冲区之间的关系:
mysql给我们提供了关键字COMMIT和END来标注一个事务的开始与结束。与之类似的,xv6提供了begin_op和end_op两个api来标注一个事务的开始与结束,并要求一些FS相关的api,都必须夹在这两个api间执行:
begin_op();
...
bp = bread(...);
bp->data[...] = ...;
log_write(bp);
...
end_op();
这套编程模型告诉我们,我们对盘块进行写操作时,首先要调用begin_op标注事务的开始,然后通过bget拿到盘块对应的缓冲块,并在bp->data上写入数据。写操作执行完成后,需要调用log_write,将这个buf添加到日志中,最后调用end_op标注事务的结束。
void
begin_op(int dev)
{
acquire(&log[dev].lock);
while(1){
if(log[dev].committing){
sleep(&log, &log[dev].lock);
} else if(log[dev].lh.n + (log[dev].outstanding+1)*MAXOPBLOCKS > LOGSIZE){
// this op might exhaust log space; wait for commit.
sleep(&log, &log[dev].lock);
} else {
log[dev].outstanding += 1;
release(&log[dev].lock);
break;
}
}
}
先看一下begin_op。根据前面的讨论,当一批日志正处于提交阶段时(logp[dev].commiting == 1)不应当创建新的日志;
另外,xv6限制了一个事务中修改盘块的数量(MAXOPBLOCKS),以避免日志溢出。对于设备dev来说,之前的事务已经产生了log[dev].lh.n条尚未提交的日志,同时现在尚有log.[dev].outstanding条事务尚未完成全部操作,再加上本事务最多需要写MAXOPBLOCKS条日志,因此最终的越界检查条件为 log[dev].lh.n + (log[dev].outstanding+1)*MAXOPBLOCKS > LOGSIZE,如果可能存在越界的情况,则睡眠等待。经过这两个判别条件后即允许这个事务执行,这里简单的将log[dev].outstanding += 1,为这个事务的日志预留好空间,然后返回。
void
log_write(struct buf *b)
{
int i;
int dev = b->dev;
if (log[dev].lh.n >= LOGSIZE || log[dev].lh.n >= log[dev].size - 1)
panic("too big a transaction");
if (log[dev].outstanding < 1)
panic("log_write outside of trans");
acquire(&log[dev].lock);
for (i = 0; i < log[dev].lh.n; i++) {
if (log[dev].lh.block[i] == b->blockno) // log absorbtion
break;
}
log[dev].lh.block[i] = b->blockno;
if (i == log[dev].lh.n) { // Add new block to log?
bpin(b);
log[dev].lh.n++;
}
release(&log[dev].lock);
}
log_write将日志的buf下标标注到log[dev].lh[block]中。如果之前这个buf已经被添加到过日志中了,则无需多此一举(即log absorbtion),否则,需要调用bpin让这个buf的引用计数增一,避免这个脏块在回写前被bget给回收掉。
void
end_op(int dev)
{
int do_commit = 0;
acquire(&log[dev].lock);
log[dev].outstanding -= 1;
if(log[dev].committing)
panic("log[dev].committing");
if(log[dev].outstanding == 0){
do_commit = 1;
log[dev].committing = 1;
} else {
// begin_op() may be waiting for log space,
// and decrementing log[dev].outstanding has decreased
// the amount of reserved space.
wakeup(&log);
}
release(&log[dev].lock);
if(do_commit){
// call commit w/o holding locks, since not allowed
// to sleep with locks.
commit(dev);
acquire(&log[dev].lock);
log[dev].committing = 0;
wakeup(&log);
release(&log[dev].lock);
}
}
end_op标记着一次事务的结束。首先使记录着当前未执行完事务数量的标记log[dev].outstanding递减(此时记录着buf数量的log[dev].lh.n已经被正确修改了)。如果此时已经没有尚未完成的FS操作,则标注log[dev].commiting为1,并调用commit提交日志,将这批日志(脏块)写入到磁盘上的日志区。接下来我们阅读一下commit以及其相关的代码:
static void
commit(int dev)
{
if (log[dev].lh.n > 0) {
write_log(dev); // Write modified blocks from cache to log
write_head(dev); // Write header to disk -- the real commit
install_trans(dev); // Now install writes to home locations
log[dev].lh.n = 0;
write_head(dev); // Erase the transaction from the log
}
}
static void
write_log(int dev)
{
int tail;
for (tail = 0; tail < log[dev].lh.n; tail++) {
struct buf *to = bread(dev, log[dev].start+tail+1); // log block
struct buf *from = bread(dev, log[dev].lh.block[tail]); // cache block
memmove(to->data, from->data, BSIZE);
bwrite(to); // write the log
brelse(from);
brelse(to);
}
}
static void
write_head(int dev)
{
struct buf *buf = bread(dev, log[dev].start);
struct logheader *hb = (struct logheader *) (buf->data);
int i;
hb->n = log[dev].lh.n;
for (i = 0; i < log[dev].lh.n; i++) {
hb->block[i] = log[dev].lh.block[i];
}
bwrite(buf);
brelse(buf);
}
static void
install_trans(int dev)
{
int tail;
for (tail = 0; tail < log[dev].lh.n; tail++) {
struct buf *lbuf = bread(dev, log[dev].start+tail+1); // read log block
struct buf *dbuf = bread(dev, log[dev].lh.block[tail]); // read dst
memmove(dbuf->data, lbuf->data, BSIZE); // copy block to dst
bwrite(dbuf); // write dst to disk
bunpin(dbuf);
brelse(lbuf);
brelse(dbuf);
}
}
write_log负责将日志写入到磁盘的日志区,缓冲块指针to对应着日志区上放置这条日志的盘块,from对应着一条处于提交状态的日志。mommove将日志的内容从from复制到to之后,对to调用bwrite,实现日志块的回写操作。
write_head修改磁盘日志区的元数据区,即将logheader回写,而logheader的成员blocks标注了事务中涉及到的日志的位置。这一方法必须在write_log执行完成之后才能被调用。否则如果系统在write_head之后,write_log之前发生崩溃,则会产生日志缺失的情况,使得系统在重启时无法通过日志还原系统的状态。
install_trans负责使用日志覆盖掉对应的盘块。该方法读取logheader.blocks数组,将每个对应的日志区的盘块安装到文件区。
当成功用日志覆盖掉对应的盘块后,系统已经无需再继续持有这些日志,因此会再次调用write_head修改日志区的logheader来清除日志,并设定log[dev].lh.n = 0。
重做日志
崩溃不仅仅可能发生在文件读写时,也可能发生在系统恢复时,如果发生在系统恢复时,那么不完整的日志安装操作也可能使系统进入不一致状态。xv6的日志的实现方式可以巧妙的解决这一情景,因为xv6的日志实现方式是重做日志。我个人简单的将重做日志定义如下:
假设当前系统的状态为s1(s1是一致的状态,因为日志只会在一致状态下生成),一组事务的操作会使系统从状态s1进入s2(根据事务的定义,s2也是一致状态),这组事务在执行过程中被中断时,系统所有的可能状态构成集合SI(即系统从s1过渡到s2之间的全部过渡态,包含很多的不一致状态)。可重做日志需要保证,对于任意状态 s’ ∈ SI,安装完毕所有日志后,系统必定能进入状态s2。
很容易证明,xv6的日志是重做日志,因为xv6日志的本质就是经过完整访问操作之后的脏块。
事实上,日志可以有很多种实现,像xv6这样以脏块作为日志就是一种可行的方法。另一种可行的实现方法是将操作作为日志(以下简称为操作日志),而不是像xv6一样,将操作后的结果(脏块)作为日志。操作日志的采用还是比较普遍的,例如很多为银行业务而设计的DBMS会采用操作日志。在6.824的Lab中,也是采用了操作日志,使用raft算法在集群上同步操作日志,并在系统崩溃后通过回放操作日志中的操作来恢复状态机的状态。
前几天重读raft的论文的时候看到一个一笔带过的概念idempotent,也就是
幂等,用来描述重做日志可以说是十分贴切的。
系统崩溃的情景
在小节日志与事务中我提到,xv6的api设计可以保证一切事务 p ∈ P,这样我们一致性协议三个条件中的前两个都可以得到满足。下面我们来分析一致性协议的第三条要求(即原子性)是如何满足的,或者说我们来分析,xv6是如何在系统崩溃的情况下,仍然能保证磁盘状态的一致性的。
你应该很早就注意到了日志层中的这段代码,这段代码要求xv6系统启动之初,将日志区现存的全部可以安装的日志,安装到其对应的盘块上:
static void
recover_from_log(int dev)
{
read_head(dev);
install_trans(dev); // if committed, copy from log to disk
log[dev].lh.n = 0;
write_head(dev); // clear the log
}
如果你无法接受之前采用的接近数学语言的说法,那我们来条分缕析,考察崩溃发生的全部情景。一个事务的操作可以被分为以下几个部分,如图所示:

内存中的操作,例如说log_write、file_write等
将脏块写入到磁盘的日志区(write_log)
日志全部落盘,接下来要修改logheader,标注好哪些日志盘块中有日志(write_head)
利用日志覆盖其对应的盘块(install_trans)
所有日志安装成功,修改logheader记录已经没有日志可写
崩溃的情景可能有6个,已经在图上标出。现在我们仅考虑单个事务的情况,后面我们再推广到多个事务并发的情况;
情景1下是系统在没有事务执行时发生崩溃,情景2是系统正在处理事务,但事务尚未执行写磁盘操作。由于执行事务前磁盘的状态是一致的,而当前的事务尚未对磁盘的状态进行修改(没有执行写盘块的操作),因此崩溃重启后,磁盘的状态仍然是一致的。
情景3表示崩溃发生在脏块写入到磁盘的日志区时,注意此时虽然日志区发生了状态变化,但日志还没有被安装,也就是说inode区、data区仍然是一致的。重启时,由于logheader还没来得及被回写,因此logheader的成员n为0,因此这批日志不会被安装,且看起来好像日志区没有日志一样。这样,磁盘的状态仍然是一致的,只是那些落盘的日志永无执行之日而已。
情景4表示崩溃发生在写logheader时。为了方便分析起见,我们不妨认为崩溃不会发生在写盘块的过程中,而只会发生在写盘块的间隙中间,即能保证写盘块的操作必定是原子的。这种情形下,如果logheader没有被回写,那么情况4等价于情况3,如果logheader成功被回写,那么情况4等价于情况5;但无论哪种情况,最终都可以使系统进入一致性状态。
情景5发生在磁盘将日志区的日志安装到对应的盘块期间。前文中已经讨论过,不完整的事务操作可能使磁盘进入不一致状态,因此这种崩溃情景会导致磁盘进入不一致的状态。但系统在重启后会调用recover_from_log方法来重做日志。由于情景5发生时这批事务的所有日志必定都在日志区,因此重做这批日志必定能使系统进入一直状态。
情景6发生在日志已经全部安装之后、重置logheader之前。这种情景等价于情景5,只不过是将日志重新执行一次而已。
接下来考虑并发的情景,根据前面的情景讨论,崩溃发生在内存操作时是不会引起不一致的现象的,而磁盘的操作又通过锁来保证了串行性。因此在并发情景下,仍然可以保证磁盘状态的一致性。
一种可能会导致不一致的情景 —— 盘块写操作的非原子性
前文中花费了海量的笔墨来讨论xv6日志层下一致性的实现原理,现在我们来讨论一个非常极端的corner case,这种情景可能会导致磁盘进入不一致的状态。
回顾一下write_log方法,它要将内存中的logheader回写到日志区对应的logheader上,而log[dev].lh.blocks标注着事务中所涉及的全部日志的日志块编号。一个logheader正好占据一个盘块的大小,只需要调用一次bwrite即可完成回写。但我们考虑一种非常极端的情景:如果程序的崩溃发生在logheader回写的过程中会怎样?
这种情景可能会产生不完整的数据,一种情况是log[dev].lh.blocks数组仅仅只写了一部分,另一部分还没被持久化到磁盘上。如果重启系统,recover_from_log会读取logheader区,根据log[dev].lh.blocks数组的内容来索引日志,将日志安装到对应的data区;而由于log[dev].lh.blocks的数据是不完整的,那么就无法保证一个事务中的全部日志均能被安装,也就破坏了一致性协议的第三条目:操作必须保证原子性。更为严重的情景是那些占据了多个字节的成员,如果系统崩溃发生时这些成员的对应字节并没有被完整写完,那么这个成员的值就是无效的了,这可能会诱发更大程度的损害。
归根结底的原因,是我们的一切操作都要基于盘块的写操作,而盘块的写操作无法保证原子性,这种原子性的缺失仅会在上述情形下使磁盘有进入不一致状态的可能,避免方法其实也不难想到 —— 虽然对盘块的写操作无法保证原子性,但对盘块的任意一个bit应该是可以保证原子性的。由此,我们可以在磁盘的log区再设立一个标志bit,当logheader块回写完毕后再置这个bit为1。每次系统重启前需要先检查这个bit,如果为1的话,说明logheader已经成功回写完毕,因此可以安装这些日志。
你咋整出这套民科理论来讲一致性的?
这个想法的源头在于我读日志层的代码时的一个突发奇想,假设我在xv6中执行下面的程序:
int main(int argc, char **argv) {
int fd = open("test.txt", O_CREATE|O_RDWR, 0666);
int ret = write(fd, "abcde", 5);
if (ret == 5) {
printf("nice!");
}
exit(0);
}
在执行代码的时候如果程序输出了“nice”,然后系统崩溃掉了,我把系统重启去读取这个文件,能从这个文件里看到我写入的“abcde”吗?更加严谨的说,如果一个write系统调用成功返回了n个字节,那么这n个字节能不能保证成功的落盘了呢?
经过阅读xv6的源码,我发现这是不能保证的,因为write中,只需要将buf->refcnt增1后,就可以返回,即write返回时,我们不能保证具体的数据已经被回写到磁盘上。这一点给了我很大的冲击,虽然我知道调用flush刷新缓冲区可以保证内容顺利回写,但这也意味着仅依靠write的成功返回完全无法保证数据的持久化,这种情况是不是一种常见的情况,还是只出现在了xv6里面?为此我查阅了一些资料,最终在write的 manpage 里面找到了如下的描述:
A successful return from write() does not make any guarantee that data has been committed to disk. On some filesystems, including NFS, it does not even guarantee that space has successfully been reserved for the data. In this case, some errors might be delayed until a future write(), fsync(2), or even close(2). The only way to be sure is to call fsync(2) after you are done writing all your data.
原来大家都一样(不靠谱)啊....(不过如果大家都不靠谱,那只能说明自己的想法不靠谱了orz)
这个时候我继续思考,这种情形会不会导致错误,即会不会造成磁盘数据不一致的情形,然后发现这是不会的,虽然这五个字节没被写入,但对这个文件的读写操作,并不会出现bitmap标注错误、读写不完整的盘块等恶劣情况。这个时候我意识到,产生上面的想法是因为我对一致性的理解产生了误差。日志层所提供的一致性到底是一种什么样的一致性,对应的一致性约束条件到底是什么?根据这些一致性约束条件,我能够推理出哪些必定能保持一致性的情景?这些都是我在读这些源码的时候没有仔细思考的问题。再次重读了一下代码后,我就给出了前文中我所认为的一致性约束的具体内容。
最后的最后,既想利用严谨的数学语言来实现对这些问题的高度抽象,发现自己根本没那种程度的数学能力和洞察力,又希望能通过各种简单的示例来抓住重点,但又发现这些例子不能完全说服自己,整出了一套四不像的理论,也把自己完成了民科,以后还是得多看书多写码多思考吧。
回顾总结
本篇blog主要讨论了xv6的日志层的实现以及其相关的原理。关于文章中提到的一致性、事务的数学定义都是我个人的胡言乱语,如果希望学习相关概念请抄起大部头书来进行学习。
日志层的作用是保证磁盘系统的一致性,为了能够理解日志层的功能,我们需要对一致性的概念首先进行了解。我们在很多的地方都能看到一致性这个概念,例如说数据库中数据的一致性、分布式系统共识算法达成的一致性,以及xv6中磁盘状态的一致性等。宽泛的来说,系统的一致性指系统内部的一致性约束条件均能得到满足。对于磁盘系统来说,一致性约束条件为磁盘的元数据能正确反映磁盘的状态,文件的元数据能正确反映文件的状态。
磁盘在通过mkfs/mkfs生成时是满足所有的一致性约束条件的,在与xv6连接后,xv6会通过文件读写操作改变磁盘的状态。一次完整的文件读写操作可能会涉及到data区、inode区、bitmap区的修改。xv6的文件系统代码我们可以认为是没有bug的,即一次完整的文件读写操作是磁盘系统的一个合法操作,因此完整的执行完这些操作后,磁盘系统的状态仍然是一致的。但系统崩溃、断电等情况会导致一个完整的操作被中断,此时系统很可能进入不一致的状态。为了应对这种问题,xv6引入了日志和事务的概念。
事务是xv6对日志层的上层(inode层)提供的一种辅助抽象,其要求将一切对文件的访问操作组织在begin_op和end_op之间。文件的读写操作都是在缓冲区上进行的,而不会立即落盘,也无法保证最终会落盘(但磁盘的一致性状态仍然是得到保持的)。xv6会在当前没有等待的FS系统调用的时候,将一组事务所访问的所有盘块写入到磁盘的日志区,日志区的这些盘块即为日志,其本质就是一块对应于data区的脏块。只有当事务所涉及的所有日志都顺利持久化到日志区后,文件系统才会将日志区的日志安装到data区,这样可以保证一组事务的全部操作都会被写入到磁盘上。
当崩溃发生时,系统可能会进入不一致状态。根据前文讨论,系统唯一可能进入不一致状态的情景为日志的安装过程或logheader回写的过程被打断。在这种情景下,日志必定已经全部落盘,且日志是一种重做日志,因此系统重启后,通过重做这些日志,必定能使系统进入一致的状态。
根据日志层所保证的一致性约束条件(磁盘的元数据能正确反映磁盘的状态,文件的元数据能正确反映文件的状态)容易推论,我们无法保证一次write系统调用的成功返回后所写的内容能够落盘。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号