MIT 6.S081 聊聊xv6中的文件系统(上)
前言
Lab一做一晚上,blog一写能写两天,比做Lab的时间还长(
这篇博文是半夜才写完的,本来打算写完后立刻发出来,但由于今天发现白天发博点击量会高点,就睡了一觉后才发(几十的点击量也是点击量啊T_T)....
我个人计划采用bottom-up的方式,用两篇blog配合源码讲解xv6的文件系统。
xv6对文件系统的架构做出了如下的分层:

我个人倾向于将设备驱动程序也加入到文件系统的架构中,因此最后形成的架构图如下:

本篇blog讲解首先谈了谈我个人对文件系统的见解,随后讲解xv6的存储介质层、设备驱动层和缓冲层。内容很可能有各种纰缪,如果dalao发现其中的错误,还请在评论区指正。
关于日志层、inode层、命名目录层、文件描述符层,会在下一篇blog中讨论。
我眼中的文件系统
文件管理是操作系统的几大基础功能之一(内存管理、进程管理、设备管理、文件管理)。一般来说,文件是持久化在磁盘上的一组二进制数据,具体类型包括ELF文件、图片文件、音乐文件、视频文件、文本文件等;不同类型的文件有着不同的信息和存储格式,而操作系统无需关心文件的具体内部结构和文件的具体应用,即操作系统不应当关心文件中信息的解释,这是具体的用户程序应当关注的事情。特定格式的文件通常与其对应的用户程序协定好了上下文,以便用户程序可以识别和读取文件内部的信息。一个不算很恰当的例子就是ELF格式的文件,其前32字节(对应ELF32文件)被称作ELF头部,记录着这个文件的类别(可重定位、可执行、Core、共享目标)、版本、对应的段的偏移值等;如果这个文件是可执行文件,在执行改文件时,exec系统调用将按照ELF格式文件的布局读取相应的段,最终将这个ELF文件加载成用户进程。这里虽然操作系统担当了解释文件(exec按照用户程序解释该文件)的角色,但exec调用是知道这个文件的格式的,并依照这个格式对文件的上下文进行了解释。
我们从上文可知,操作系统/文件系统不应当关心文件的具体格式和具体内容。文件系统所负责的任务,应当是向下(存储层)操控对应的设备管理器(一般是磁盘的驱动系统),将对文件的操作转换为对某个设备的操作;向上(面向用户)为用户提供一套所有文件通用的接口(创建、查找、打开、读取、修改、删除,目录等),对用户隐藏底层存储与文件操作的繁琐细节(如并发访问、崩溃恢复等)。
一般来说,讲解文件系统时,总是离不开讲解磁盘等存储设备。既然我们采用了bottom-up的讲解方法,那我们自然要首先从具体的存储介质开始讲起。
存储介质层
xv6钦点的存储介质为磁盘,因此本节我们讨论file system对磁盘做了哪些要求和行为。
磁盘的区域划分
如果你之前学过《操作系统》这门课程的话你应该知道,刚刚拿到手的裸盘是不能直接使用的,必须经过物理格式化和逻辑格式化之后才能被使用。逻辑格式化即在磁盘上写入一系列支持文件系统所需的数据,这些数据将磁盘的空间进行了划分,为实现文件的组织、存储空间的分配与回收提供着相应的支持。xv6对磁盘空间的划分方法如下图所示:
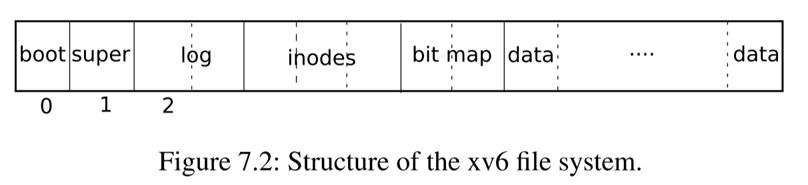
磁盘上的第一个盘块为boot sector,即引导区。一般来说每个磁盘可以划分成多个分区,而每个分区都会有一个引导区,如果在这个分区上安装有操作系统的话,需要将操作系统的引导入口写入到boot sector中。xv6默认磁盘只有一个分区,因此自然也就只有一个引导区。boot sector怎么将内核代码加载到内存中就又是另一个话题了,这里不再赘述。
磁盘的第二个盘块为super block,记录着管理这个磁盘的一系列元数据,我们可以在kernel/fs.h中看到super block的数据结构:
// Disk layout:
// [ boot block | super block | log | inode blocks |
// free bit map | data blocks]
//
// mkfs computes the super block and builds an initial file system. The
// super block describes the disk layout:
struct superblock {
uint magic; // Must be FSMAGIC
uint size; // Size of file system image (blocks)
uint nblocks; // Number of data blocks
uint ninodes; // Number of inodes.
uint nlog; // Number of log blocks
uint logstart; // Block number of first log block
uint inodestart; // Block number of first inode block
uint bmapstart; // Block number of first free map block
};
磁盘的第三个区域为log区,其对应的元数据为superblock中的nlog和logstart。这个区域存储着落盘的日志,每条日志对应一个block。实际上,日志本身是某个block经过一次完整的写操作之后的状态。在xv6系统中,为了维护好磁盘状态的一致性,对盘块的写操作暂时不会覆盖原来的盘块,而是将这个盘块作为一条日志存储在日志区,等待日志提交时再将日志区的盘块回写到相应的区域。这一部分的原理和内容将会在后面的日志层中介绍。
磁盘的第四个区域为inodes区,其对应的元数据为superblock中的inodestart和nblocks。每个文件都会对应着inode区的一个inode,每个inode记录着文件的元数据,例如文件类型、文件大小、盘块占据情况等。
磁盘的第五个区域为bitmap,其对应的元数据为superblock中的bmapstart。在xv6中使用位图来记录盘块的使用情况,相应的位图即被存放在了这个区域,为文件系统中盘块的分配与回收提供相应的支持。
磁盘的第六个区域(也就是最后一个区域)即文件盘块,用于存储文件的具体内容或者间接索引块(见Lab8 File System)。
磁盘的逻辑格式化
前文中已经提到,一块裸盘需要经过物理格式化和逻辑格式化后才能被使用,其中逻辑格式化的任务就是将磁盘按照预先设定好的格式进行划分。在本课程我们使用的是硬件模拟器qemu,需要将一个文件作为磁盘。查看一下对应的makefile命令:
qemu-system-riscv64 -machine virt -bios none -kernel kernel/kernel -m 128M -smp 1 -nographic -drive file=fs.img,if=none,format=raw,id=x0 -device virtio-blk-device,drive=x0,bus=virtio-mmio-bus.0
注意到一个命令行参数 file=fs.img,这说明在qemu中将我们的fs.img当做了磁盘。fs.img是通过项目目录下的程序mkfs/mkfs来生成的,我们需要查看一下mkfs/mkfs.c下的代码,这部分的代码正好对应着磁盘的逻辑格式化过程。比较有趣的是,我们可以查看一下mkfs的include情况,可以发现其使用了C标准库文件。这很正常,毕竟我们只需要生成一个符合前文所述的格式的文件即可,无需关心到底使用了哪些库。
// mkfs/mkfs.c
int
main(int argc, char *argv[])
{
int i, cc, fd;
uint rootino, inum, off;
struct dirent de;
char buf[BSIZE];
struct dinode din;
static_assert(sizeof(int) == 4, "Integers must be 4 bytes!");
if(argc < 2){
fprintf(stderr, "Usage: mkfs fs.img files...\n");
exit(1);
}
assert((BSIZE % sizeof(struct dinode)) == 0);
assert((BSIZE % sizeof(struct dirent)) == 0);
fsfd = open(argv[1], O_RDWR|O_CREAT|O_TRUNC, 0666); // create file fs.img. Notice that we used C standard library.
if(fsfd < 0){
perror(argv[1]);
exit(1);
}
这一部分代码对编译环境和某些数据结构进行了检查,例如说int必须占据4字节大小、一个盘块必须能被struct dinode和struct dirent无缝填满等。
我们在kernel/param.h中定义了一系列文件系统相关的参数,其中包括魔数字、文件系统大小、inode最大数量等,并且可以以此推算出superblock中其他的元数据的值,即各个区域在磁盘上的范围。这些元数据被记录到superblock中。随后通过wsect方法,将磁盘(文件)的所有部分全部置零。
在mkfs/mkfs.c中还定义了xint、xshort方法,这些方法的目的是改变字节序(即我们常说的大端存储和小端存储),这部分的内容不再赘述,如果不了解可以参照一下相应的wikipedia:https://zh.wikipedia.org/wiki/字节序。
memset(buf, 0, sizeof(buf));
memmove(buf, &sb, sizeof(sb));
wsect(1, buf); // write super block which contains meta data of file system.
将superblock写入到磁盘的第一个盘块上。
rootino = ialloc(T_DIR);
assert(rootino == ROOTINO);
bzero(&de, sizeof(de));
de.inum = xshort(rootino);
strcpy(de.name, ".");
iappend(rootino, &de, sizeof(de));
bzero(&de, sizeof(de));
de.inum = xshort(rootino);
strcpy(de.name, "..");
iappend(rootino, &de, sizeof(de));
根目录是磁盘上的第一个文件。首先调用ialloc分配一个inode。由于它是一个目录文件,因此要拥有默认的两个表项“.”和“..”,iappend将这两个表项写入到磁盘的盘块上。
for(i = 2; i < argc; i++){
// get rid of "user/"
char *shortname;
if(strncmp(argv[i], "user/", 5) == 0)
hortname = argv[i] + 5;
else
shortname = argv[i];
assert(index(shortname, '/') == 0);
if((fd = open(argv[i], 0)) < 0){
perror(argv[i]);
exit(1);
}
// Skip leading _ in name when writing to file system.
// The binaries are named _rm, _cat, etc. to keep the
// build operating system from trying to execute them
// in place of system binaries like rm and cat.
if(shortname[0] == '_')
shortname += 1;
inum = ialloc(T_FILE); // allocate each file a inode
bzero(&de, sizeof(de));
de.inum = xshort(inum);
strncpy(de.name, shortname, DIRSIZ);
iappend(rootino, &de, sizeof(de));
while((cc = read(fd, buf, sizeof(buf))) > 0)
iappend(inum, buf, cc); // write into disk
close(fd);
}
mkfs/mkfs接收了一系列的命令行参数,这些参数正好对应着makefile中的 $UPROGS,即我们添加到磁盘中的用户程序。这部分代码为每一个用户程序分配一个inode,并将内容写入到对应的盘块上,置其占据的位图位为1。这样我们也可以理解为什么我们启动了内核之后,能够看到这些程序了。
// fix size of root inode dir
rinode(rootino, &din);
off = xint(din.size);
off = ((off/BSIZE) + 1) * BSIZE;
din.size = xint(off);
winode(rootino, &din);
balloc(freeblock);
exit(0);
}
最后修改一下根目录的大小,mkfs/mkfs执行就结束了。
我们可以看到,mkfs/mkfs担当了磁盘的逻辑格式化的角色,在根据我们的设计在磁盘上实现了对区域的划分,并将一些用户程序写入到了文件系统中。如果感兴趣的话,你也可以考虑将360全家桶和百度全家桶也写入到文件系统里(捌要命啦
值得注意的是,上述代码中都没涉及到对0号盘块,即boot sector的写操作,而且内核也没被写入到磁盘中。内核应该是通过其他的方式被加载到内存中的,这里我也没有做进一步的探究。
总结
xv6采用磁盘作为文件存储的介质。磁盘最初一般是一块裸盘,需要经过物理格式化和逻辑格式化后才能被使用。其中的逻辑格式化即根据预先设计好的格式,对磁盘进行划分。xv6系统中的mkfs/mkfs承担了磁盘逻辑格式化的任务,将磁盘空间划分成了boot sector、super block、log、inodes、bitmap、data等区域,为文件系统实现文件组织、空间的分配与回收提供着重要的支持。
设备驱动层
操作系统并不会直接操作相应的设备,而是要通过相应的设备驱动程序来操纵对应的设备。我们在linux中经常使用mount命令来“挂载”一个块设备。当块设备通过usb等接口插入到主板上时,操作系统即可识别到有一个块设备已经与主板建立了连接,但此时并不能对这个设备进行操作,而必须通过mount命令后,才能实现对块设备的读写,而mount命令的功能之一就是寻找到该块设备对应的设备驱动程序。经过mount之后,操作系统即可通过设备驱动程序来操作设备了。
在make qemu的命令行输出中,我们可以看到 -device virtio-blk-device 这个命令行参数,即要求qemu模拟virtio-blk-device这个硬件,根据这个名字来看,这是一个块设备,其对应的设备驱动程序的代码在kernel/virtio_disk.c中。这部分的代码看一眼就头大(I/O设备的代码应该是最复杂的代码了,我舍友写蓝牙代码的时候头都快炸了),我们没精力也没必要去认真阅读这些代码。我们只需要知道以下内容:
1)xv6采用了MMIO(内存映射I/O),即不通过I/O指令访问设备,而是在内存中划分出一块特殊的区域,并映射到对应的设备上,对这部分区域的读写操作将被映射到对设备的操作;
2)virtio_disk.c的代码承担的是设备驱动程序的角色,文件系统通过调用virtio_disk_rw,实现对设备的写操作;
3)在设备驱动程序的辅助下,一切对磁盘的操作,被统一为对磁盘上盘块的读/写操作;
最后做个总结,设备驱动层应当包含着一系列的设备驱动程序。操作系统不能也不应该直接操作相应的设备,而是需要通过设备对应的设备驱动程序来实现对设备的操作。在xv6中,qemu将会模拟设备virtio-blk-device,其对应的设备驱动程序的代码在kernel/virtio_disk.c下,这个设备驱动程序向上层提供了一个重要的接口virtio_disk_rw,通过这个接口,操作系统与磁盘的一切交互(文件系统的请求、数据的读写等),全部通过对特定盘块的读写操作来实现。
缓冲层
我们知道,I/O操作和内存操作的速度差距是非常大的,这导致很多程序的速度瓶颈源自于I/O的效率。目前一个广泛采用的方式是将文件的部分块读取到内存中作为缓冲,将对磁盘的访问操作转换为对内存的操作,并通过一致性协议维持内存中文件块与磁盘文件块的一致性。除此以外,缓冲区还要承担另一个任务:同步对磁盘块的并发访问。接下来我们仔细分析xv6的源码,来了解xv6是如何实现这些需求的。
api简介
xv6的缓冲层代码在kernel/bio.c下。我们首先看一下buf的数据结构以及binit的代码:
struct buf {
int valid; // has data been read from disk?
int disk; // does disk "own" buf?
uint dev;
uint blockno;
struct sleeplock lock;
uint refcnt;
struct buf *prev; // LRU cache list
struct buf *next;
uchar data[BSIZE];
};
struct {
struct spinlock lock;
struct buf buf[NBUF];
// Linked list of all buffers, through prev/next.
// head.next is most recently used.
struct buf head;
} bcache;
void
binit(void)
{
struct buf *b;
initlock(&bcache.lock, "bcache");
// Create linked list of buffers
bcache.head.prev = &bcache.head;
bcache.head.next = &bcache.head;
for(b = bcache.buf; b < bcache.buf+NBUF; b++){
b->next = bcache.head.next;
b->prev = &bcache.head;
initsleeplock(&b->lock, "buffer");
bcache.head.next->prev = b;
bcache.head.next = b;
}
}
首先看一下struct buf的成员,dev和blockno标识着这个缓冲块对应的设备和该设备的盘块号,data中存放的是对应盘块上的数据内容。
然后我们再阅读binit和bcache来了解一下缓冲块的组织形式,可以得知,xv6预先准备了NBUF个缓冲块,虽然这些缓冲块是被存放在数组里面的,但我们访问缓冲块的时候并不希望通过数组下标访问,而希望使用链表的方式来访问(这样可以为LRU提供良好的支持)。在binit被调用后,所有的缓冲块被串接成一条链表。
接下来我们来了解一下缓冲块的分配与回收的相关代码:
static struct buf*
bget(uint dev, uint blockno)
{
struct buf *b;
acquire(&bcache.lock);
// Is the block already cached?
for(b = bcache.head.next; b != &bcache.head; b = b->next){
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
release(&bcache.lock);
acquiresleep(&b->lock);
return b;
}
}
// Not cached; recycle an unused buffer.
// Notice that we travel the list reversely.
for(b = bcache.head.prev; b != &bcache.head; b = b->prev){
if(b->refcnt == 0) {
b->dev = dev;
b->blockno = blockno;
b->valid = 0;
b->refcnt = 1;
release(&bcache.lock);
acquiresleep(&b->lock);
return b;
}
}
panic("bget: no buffers");
}
void
brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
acquire(&bcache.lock);
b->refcnt--;
if (b->refcnt == 0) {
// no one is waiting for it.
b->next->prev = b->prev;
b->prev->next = b->next;
b->next = bcache.head.next;
b->prev = &bcache.head;
bcache.head.next->prev = b;
bcache.head.next = b;
}
release(&bcache.lock);
}
void
bpin(struct buf *b) {
acquire(&bcache.lock);
b->refcnt++;
release(&bcache.lock);
}
void
bunpin(struct buf *b) {
acquire(&bcache.lock);
b->refcnt--;
release(&bcache.lock);
}
bget方法获取一个特定的buf。注意bget方法接受的两个参数:dev和blockno,这两个参数可以索引到所指定的设备的所指定的盘块。这个方法首先遍历链表,查看(dev, blockno)所对应的的盘块是否已经被分配了一个buf,如果已经分配了,则返回这个buf;否则,从空闲的buf中选择一个buf,标注buf与(设备, 盘块)的映射关系(b->dev = dev,b->blockno = blockno),并将这个buf返回,此时这个buf尚未读取入对应的磁盘盘块(b->valid == 0, b->data没有意义),对盘块的读取操作被推迟到调用bread时再进行。
brelse方法释放一个特定的buf。每个buf都有一个refcnt成员,该成员也承担着引用计数的作用,不过其所计的数比较特殊:当不同的进程调用bget获取同一个盘块的buf时,bget方法会返回这个buf对应的指针,同时将buf的引用计数增1,表明某个进程还在使用着这个buf;当这个buf->data内容已经被更新时,文件系统需要寻找一个时机,将这个buf回写到磁盘上,为此,必须保证回写前这个buf不能被回收掉。对于这种情形,xv6提供了bpin和bunpin两个方法,当完成buf的写操作后,会调用bpin方法,使refcnt增一,这样可以避免在调用brelse时该buf被回收。值得注意的是,如果一个进程调用了brelse,并不意味着这个缓冲块会被很快写入到磁盘上;一方面讲,可能还有其他的进程将这个缓冲块给pin住,阻止缓冲块的回写操作;另一方面,将缓冲块在系统中多存放一段时间,以减少总的I/O次数,对于系统来说是件好事。这些缓冲块回写的时机,我们将会在日志层进行讨论。
最后是bread和bwrite方法。bread从磁盘上读取(dev, blockno)对应的磁盘块到buf->data中,bwrite将buf->data的内容回写到(dev, blockno)上,它们对设备的读写操作都是通过调用设备驱动代码所提供的virtio_disk_rw来实现的,这也印证了我们在设备驱动层所提出的结论:操作系统与磁盘的一切交互(文件系统的请求、数据的读写等),全部通过对特定盘块的读写操作来实现。
LRU置换算法
buf的数量明显小于盘块的数量,因此缓冲池必须要有相应的置换算法,当已经没有未分配的缓冲块时,要选择重复利用一个已经没有进程引用的缓冲块。为了提高缓冲区的命中率,xv6选择了LRU置换算法,即优先淘汰掉那些最长时间未使用的缓冲块。
我们重温一下brelse的代码,当一个缓冲块的refcnt递减至0时,说明所有进程都已不再引用这个缓冲块,且xv6的代码组织可以保证,当refcnt为0时,该缓冲块一定不是脏块,即buf->data必定与(buf->dev, buf->blockno)对应的盘块内容一致;这种情况下,这个buf已经可以被回收利用了;此时,brelse代码会将这个缓冲块放置在链表的最前端。然后我们重温一下bget的代码;当第一个for循环结束时,表明(dev,blockno)对应的盘块并没有被分配相应的缓冲区,因此我们需要找到一个空闲的buf;注意到第二个循环是逆序遍历链表的,因此最新被释放的buf必定会最晚被选中淘汰,由此实现了LRU置换算法。
Lock
缓冲层共涉及到了两类锁,第一类锁是struct bcache中的自旋锁bcache.lock,第二类锁是struct buf中的睡眠锁。我接下来会讲解一下这两类锁的功能。
当我们设计数据结构的时候,如果用到了锁,就一定要十分明确我们希望用锁保护那些成员。xv6的缓冲层中,对锁的设计和锁的作用的边界划分的非常清晰,并充分发挥了睡眠锁和自旋锁各自的优势,十分值得我们学习(当然如果你在项目里用了自旋锁就活该被整 →_→ )
简单的说,struct buf中的睡眠锁的作用是同步多进程对盘块的读写操作,即每个盘块(buf)只允许一个进程访问它的data字段,而bcache.lock负责保护所有的buf中的其他成员(type、valid、链表指针等);这一点可能让我们觉得比较诡异,struct buf中的锁居然不保护struct buf中的全部成员,这些成员反而要交给另一把锁来保护,而且这把锁还是一把自旋锁。
实际上,xv6的代码中广泛使用着自旋锁。我们知道,自旋锁的实现原理是在一个死循环中不断通过CAS指令来检查状态变化,这个过程相当于cpu一直在空等,也正是因此给了我们一种自旋锁浪费了cpu的利用率的感觉;但如果希望提升cpu利用率而选择了睡眠锁反而有副作用,因为睡眠锁如果获取失败,进程会进入睡眠状态等待下一次被调度,这浪费的一轮cpu反而延长了等待时间,南辕北辙。因此对于内核代码来说,更适合使用自旋锁。当然,我们要在不需要自旋锁的时候尽早释放掉它。
经过上述的解释后,我想你应该也可以理解为什么要用一把自旋锁来保护几十个buf的成员变量了,因为这些操作都是对内存的操作,所需要花费的时间不会太长,而内核代码是十分注重效率的,自旋锁虽然会让cpu空等,但拿到锁所需要的时间相比睡眠锁来说更短。在遍历buf的链表、访问buf除了data段的成员时,都需要持有着bcache.lock。
对buf->data成员的读写,要通过睡眠锁来保护,因为这其中会涉及到I/O操作,其等待的时间会很长。此外,当调用bget成功获取到buf时,也要获取buf的睡眠锁,以防止其他进程对这个buf进行读写操作,这样就达到了同步多进程对盘块的读写操作的目的。
关于缓冲区置换算法的一些思考
在内存之上、寄存器之下引入cache对程序执行速度的提升效率有目共睹,程序的局域性原理也因此深入人心。类似的,我们可能希望将程序的局域性原理推广到文件的访问上,例如说,我曾经分析认为,brelse释放掉的buf,很可能在不久的将来再次被bget到,即一个磁盘块在现在被访问后,在不就的将来很可能会被再次访问。基于这种情形,LRU算法是一种很适合缓冲池的置换算法,因为每次被relse的会被放在链表的最前端,这样它更容易被bget到,对程序的执行效率也有一定帮助。
这种想法是站不住脚的,且不说一次cache miss操作所造成的时间损失远高于遍历链表造成的时间损失,而且LRU算法的初衷,并不包含“一个磁盘块在现在被访问后,在不就的将来很可能会被再次访问”这一想法;xv6选择LRU作为置换算法,每次将brelse的盘块放在链表的最前端,也并不是认为“brelse释放掉的buf,很可能在不久的将来再次被bget到”,而是仅仅简单的希望淘汰掉最久没使用的buf而已。
再深入想想的话,“一个磁盘块在现在被访问后,在不就的将来很可能会被再次访问” 这一想法,很可能是不成立的。为此,让我们首先来复习一下程序的局域性原理所包含的内部含义:
1)时间局部性:如果一个地址被访问,那么在不久的将来,这个地址很可能会再次被访问;
2)空间局部性:如果一个地址被访问,那么在不久的将来,与这个地址所临近的地址很可能会被访问;
空间局域性原理成立的条件在于,程序的指令是顺序连续存放的,程序的执行流一般也是顺序的(bne指令会打断顺序执行,不过也仅仅是在bne指令处跳转,跳转后直到下一跳bne指令之前,程序仍然是顺序执行的),此外,顺序遍历数据也是程序系统中最常见的访问数据方式,这些特性都完美契合空间局域性原理。时间局域性原理的分析就比较复杂了,但不难找到一些例子,例如说频繁调用的子程序、频繁访问的常量,以及广泛存在的循环代码等。
回顾了程序局域性原理后,我们拿着这两条原理来考察文件的访问操作,看看文件的访问是否能与这两条原理有所契合。但这并不是一个容易思考的问题,程序的局域性原理之所以成立,是因为程序的数据和代码在组织上连续、程序代码的顺序执行、占据大量cpu时间的循环代码、数据访问一般情况下是连续的等等原因共同作用的结果,而文件访问的情景是非常丰富的,而“一个磁盘块在现在被访问后,在不就的将来很可能会被再次访问” ,也仅仅是其中一个可能存在的情景而已。我这里考虑三类访问情景(顺序访问、大范围随机访问、重复扫描访问),这三类情景应当是比较常见的文件访问情景,并考虑基于LRU和基于MRU的缓冲池置换算法的优劣性。
1)首先考虑以顺序访问为主的情景,即对文件只顺序进行一次扫描。这种情景下LRU和MRU的置换情形是一模一样的,即假设缓冲池的容量为N,那么从第 N + 1 个盘块开始,每读取一个文件盘块都要发生一次缓冲页置换,只是被淘汰出的缓冲页不一样而已。
2)然后再考虑重复扫描访问的情景,即对文件重复进行多次顺序扫描。仍然假设缓冲池的容量为N,对于LRU置换算法来说,仍然是从第 N + 1 个盘块开始,每读取一个文件盘块都会发生一次缓冲页置换;但对于MRU算法来说,从第二次扫描开始,必定会有N + 1块盘块命中缓存,相比于全部是Miss的LRU置换算法来说,MRU置换算法显然能获得更高的效率。
3)最后考虑大范围随机访问的情景,即每次访问时,文件的每一个盘块都有相等的概率被访问到;这种情形下MRU算法和LRU算法的行为都会非常复杂,我个人没有能力对这种情形做出推断。在wikipedia中查询MRU的相应条目后可以看到如下的资料:
In findings presented at the 11th VLDB conference, Chou and DeWitt noted that "When a file is being repeatedly scanned in a [Looping Sequential] reference pattern, MRU is the best replacement algorithm."[7] Subsequently, other researchers presenting at the 22nd VLDB conference noted that for random access patterns and repeated scans over large datasets (sometimes known as cyclic access patterns) MRU cache algorithms have more hits than LRU due to their tendency to retain older data.[8]
https://en.wikipedia.org/wiki/Cache_replacement_policies#Most_recently_used_(MRU)
即由于基于MRU的置换算法有保留比较老的数据的倾向,在重复扫描文件和随机访问大数据集的情形下,其cache的命中率相比基于LRU置换算法的缓冲池更高,因此访问效率也更高。
目前为止我所思考的情形,仅限于单线程访问,在多线程的情形下可能会更加复杂,但这些思考已经足够了。通过上述情形我们可以知道,将局域性原理推广到文件访问上存在着诸多逻辑和事实上的冲突,缓冲区的置换算法应当依据其对应系统最常见的I/O情景来选择,而不能依赖经验进行推论。其实回顾一下,很多书本上告诉我们,缓冲区的设计时为了缓和I/O效率与内存访问效率差距带来的问题,并没有将局域性原理扩展到文件访问的情形下,因此我的这种观点,可以说是既找不到来源,也找不到依据了。
本篇blog就到此结束了,下一篇blog会讨论文件系统的剩余部分。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号