

XPath在Selenium WebDriver中的应用
在Selenium自动化中,如果id, class, name, etc常规定位器找不到元素,则XPath会用于在网页上查找元素。
这次我将从以下三个方面来讲解下:
1、什么是XPath
2、XPath的使用语法
3、在Selenium中使用Xpath处理复杂和动态的元素
1、XPath是XML Path语言的缩写,主要用于在XML文档中选择文档中的节点。基于XML树状文档结构,XPath可以用于再整棵树中寻找指定的节点。
XPath定位具备强大的灵活性,在XML文档树中的某个节点既可以向前搜索,也可以向后搜索。而CSS定位只能在XML文档树中向前搜索;但XPath的定位速度要比CSS慢些。
下图是XPath的基本格式

XPath的语法:
Xpath=//tagname[@attribute='value']
//:选择当前节点,也就是在文档中全部层级位置位置进行查找。
Tagname: 节点名
@:选择属性。
Attribute:节点的属性名称。
Value:属性的值。
2、XPath语法
我们这里主要讲相对路径,绝对路径基本上不会用到,知道就行了。
对于相对XPath,路径从HTML DOM结构的中间开始。 它以双正斜杠(//)开头,这意味着它可以在网页的任何位置搜索元素。
常用格式如下:定位如下图元素
Relative xpath: //*[@class='featured-box']//*[text()='Testing']

3、什么是XPath轴。
XPath轴从当前上下文节点搜索XML文档中的不同节点。 XPath轴是用于查找动态元素的方法,否则不能通过没有ID,ClassName,Name等的普通XPath方法实现。
轴方法用于查找那些在刷新或任何其他操作时动态更改的元素。 Selenium Webdriver中常用的轴方法很少,如子,父,祖先,兄弟,前置,自我等。
在Selenium中使用XPath处理复杂和动态元素
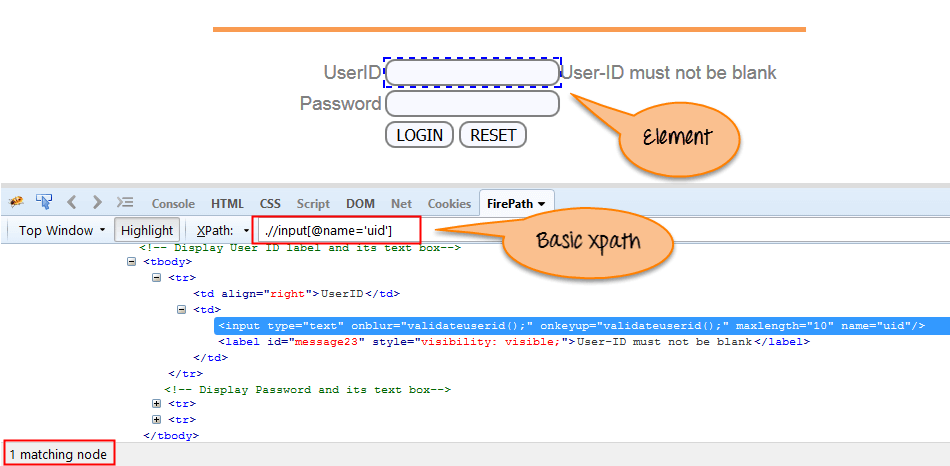
1)基本XPath:
XPath表达式根据XML文档中的ID,Name,Classname等属性选择节点或节点列表,如下所示。
Xpath=//input[@name='uid']
以下是更多基本的常见表达式:
Xpath=//input[@type='text'] Xpath= //label[@id='message23'] Xpath= //input[@value='RESET'] Xpath=//*[@class='barone'] Xpath=//a[@href='http://demo.guru99.com/']
Xpath= //img[@src='//cdn.guru99.com/images/home/java.png']
2)Contains():Contains()是XPath表达式中使用的方法。 当任何属性的值动态变化时使用它,例如登录信息。
包含功能可以找到具有部分文本的元素,如下例所示。
在此示例中,我们尝试仅使用属性的部分文本值来标识元素。 在下面的XPath表达式中,使用部分值'sub'代替提交按钮。 可以观察到该元素被成功找到。
“type”的完整值为“submit”,但仅使用部分值“sub”。
Xpath的=//* [Contains(@type,'sub')]
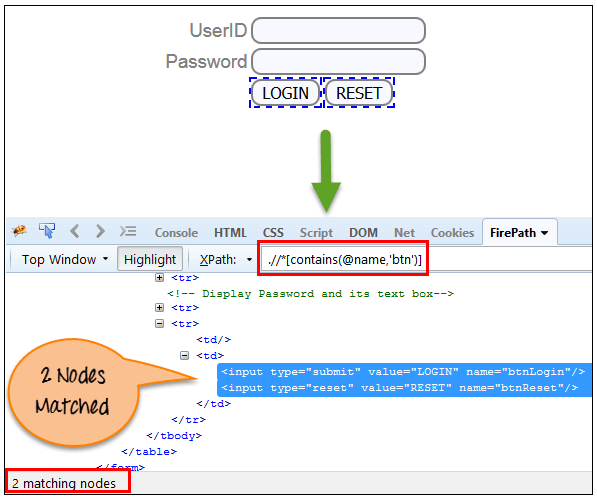
'name'的完整值是'btnLogin',但只使用部分值'btn'。
Xpath=.//*[contains(@name,'btn')]
在上面的表达式中,我们将'name'作为属性,将'btn'作为部分值,如下面的屏幕截图所示。 这将找到2个元素(LOGIN&RESET),因为它们的'name'属性以'btn'开头。
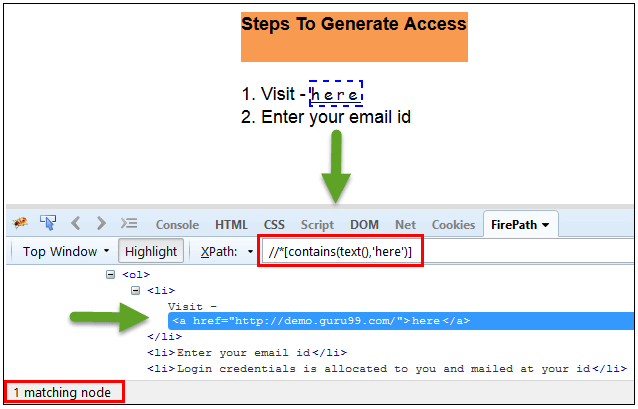
在下面的表达式中,我们将链接的“text”作为属性,将“here”作为部分值,如下面的屏幕截图所示。
这将找到链接('here'),因为它显示文本'here
Xpath=//*[contains(text(),'here')]
Xpath=//*[contains(@href,'guru99.com')]
3)使用OR&AND:
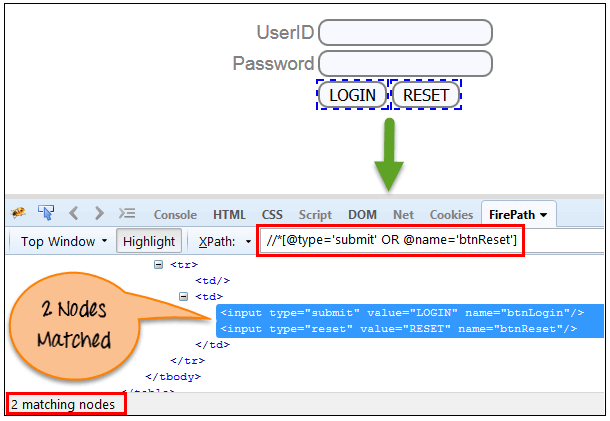
在OR表达式中,使用两个条件,无论第一个条件还是第二个条件都应该为真。 如果任何一个条件为真或两者兼而有之,它也适用。 意味着任何一个条件都应该是真的找到元素。
在下面的XPath表达式中,它标识单个或两个条件为true的元素。
Xpath=//*[@type='submit' OR @name='btnReset']
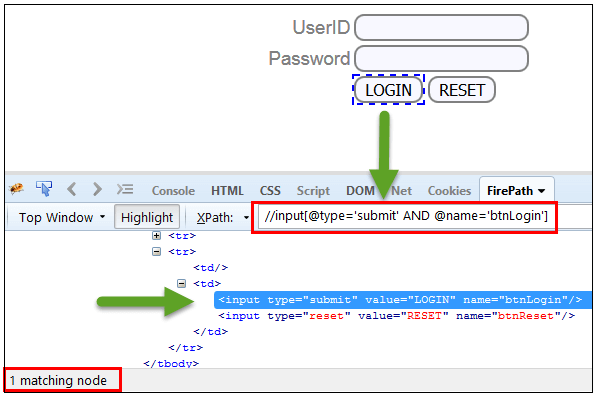
在AND表达式中,使用了两个条件,两个条件都应该为true才能找到元素。 如果任何一个条件为false,则无法找到元素。Xpath=//input[@type='submit' and @name='btnLogin']
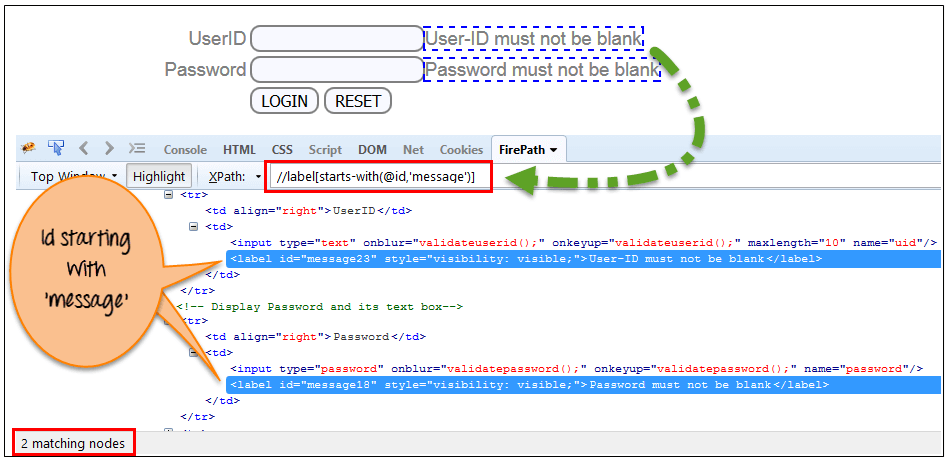
4) Start-with 功能: Start-with功能查找刷新时属性值发生变化的元素或网页上的任何操作。 在此表达式中,匹配属性的起始文本用于查找其属性动态更改的元素。 您还可以找到属性值为静态(不更改)的元素。
例如 - :假设特定元素的ID动态变化,如:
Id =“message12”
Id =“message345”
Id =“message8769”
等等..但最初的文字是一样的。 在这种情况下,我们使用Start-with表达式。
Xpath=//label[starts-with(@id,'message')]
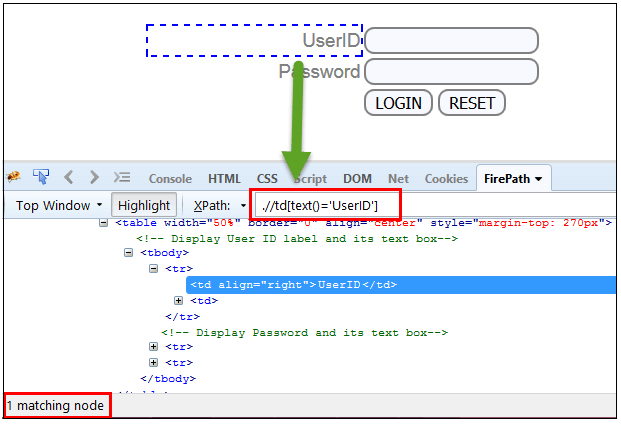
5)Text():在这个表达式中,使用文本函数,我们找到具有精确文本匹配的元素,如下所示。 在我们的例子中,我们找到带有文本“UserID”的元素。
Xpath=//td[text()='UserID']
6)XPath轴方法:这些XPath轴方法用于查找复杂或动态元素。 下面我们将看到其中的一些方法。
a)Following:选择当前节点之后的所有元素()[UserID输入框是当前节点],如下面的屏幕所示。
Xpath=//*[@type='text']//following::input
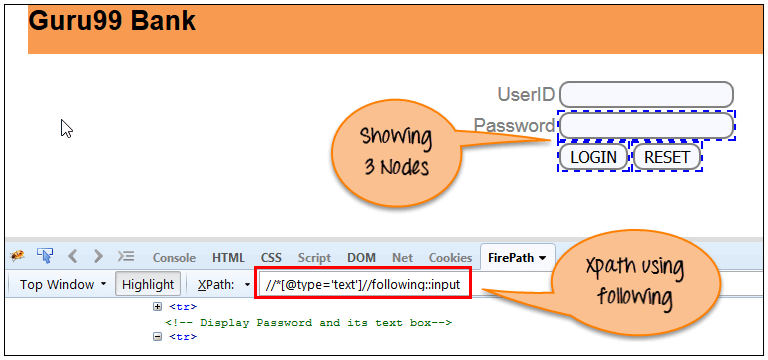
通过使用“following”轴 密码,登录和重置按钮,有3个“输入”节点匹配。 如果您想专注于任何特定元素,那么您可以使用以下XPath方法:
Xpath=//*[@type='text']//following::input[1]
您可以通过输入[1],[2] ............等来根据需要更改XPath。
输入为“1”时,下面的屏幕截图找到特定节点“密码”输入框元素
b)Ancestor:Ancestor轴选择当前节点的所有祖先元素(祖父母,父母等),如下面的屏幕所示。
也就是当前节点的所有上层节点
在下面的表达式中,我们找到当前节点的祖先元素(“ENTERPRISE TESTING”节点)。
Xpath=//*[text()='Enterprise Testing']//ancestor::div
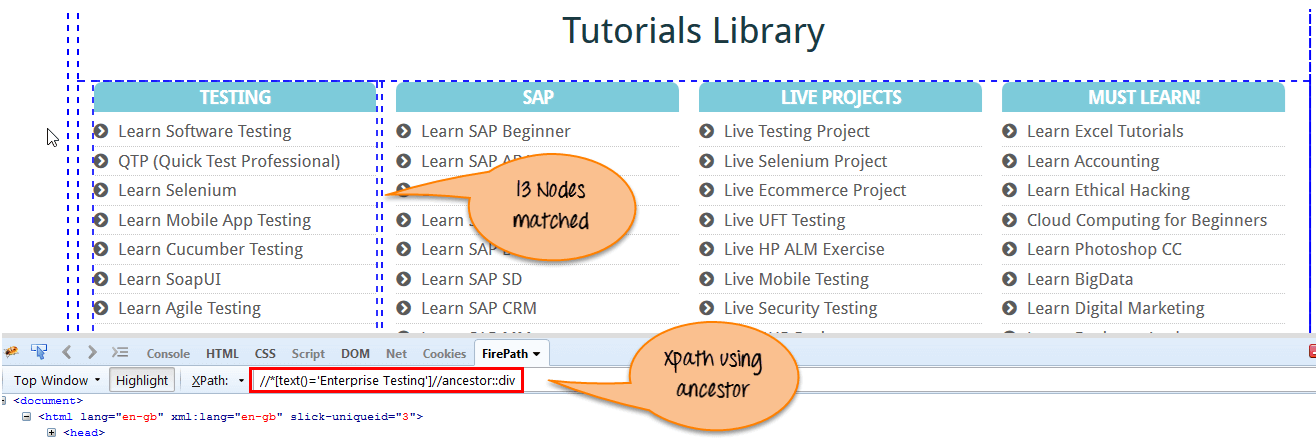
通过使用“Ancestor”轴匹配13个“div”节点。 如果您想专注于任何特定元素,那么您可以使用下面的XPath,根据您的要求更改数字1,2;
Xpath=//*[text()='Enterprise Testing']//ancestor::div[1]
c)Child:选择当前节点(Java)的所有子元素,如下面的屏幕所示。
Xpath=//*[@id='java_technologies']/child::li
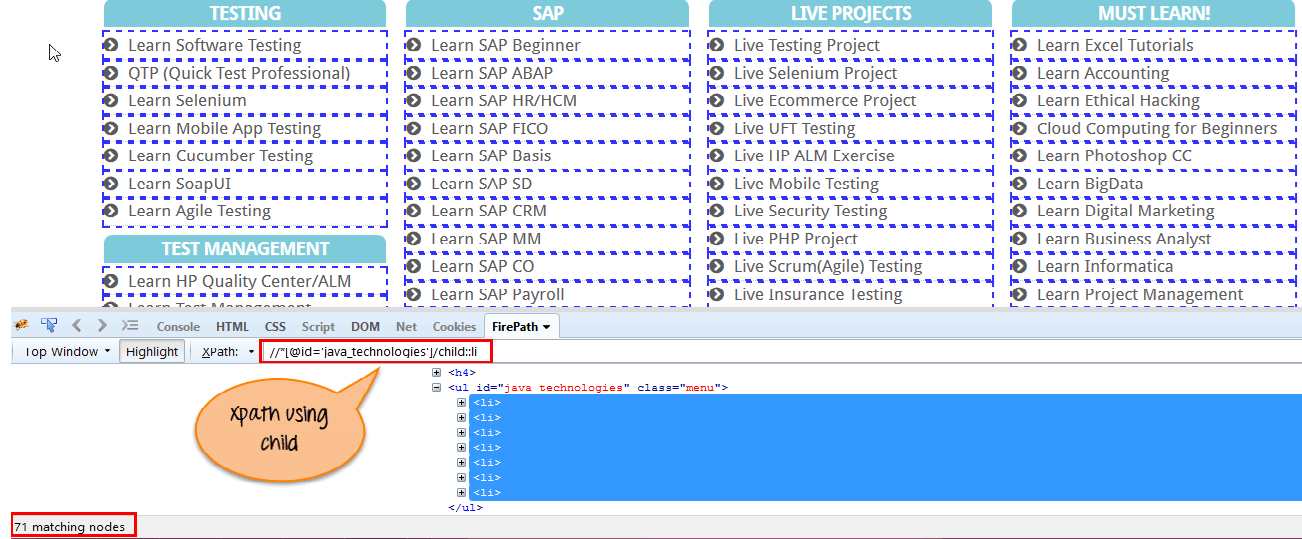
通过使用“Child”轴匹配71个“li”节点。 如果您想专注于任何特定元素,那么您可以使用以下xpath:
Xpath=//*[@id='java_technologies']/child::li[1]
d)Preceding:选择当前节点之前的所有节点,如下面的屏幕所示。
在下面的表达式中,它标识了“LOGIN”按钮之前的所有输入元素,即Userid和password输入元素。
Xpath=//*[@type='submit']//preceding::input
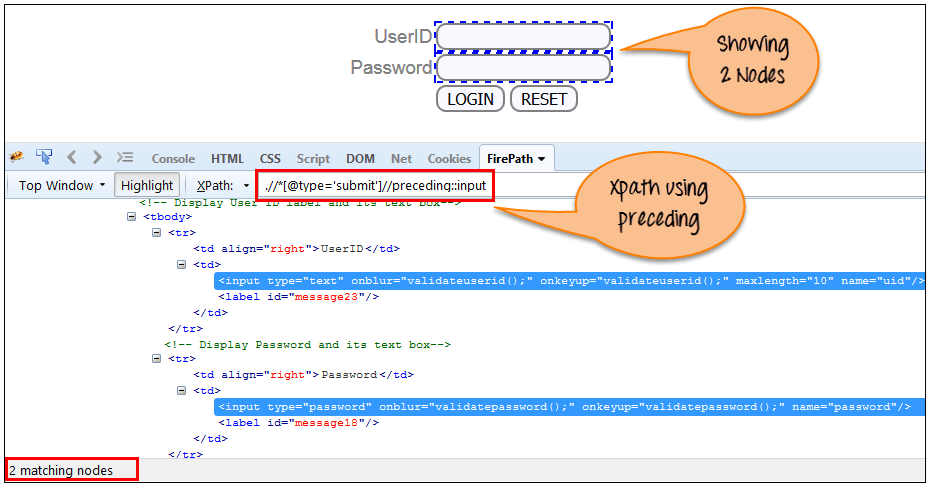
通过使用“Preceding”轴匹配2个“输入”节点。 如果你想专注于任何特定的元素,那么你可以使用下面的XPath:
Xpath=//*[@type='submit']//preceding::input[1]
e)follow-sibling:选择上下文节点的以下兄弟节点。 兄弟姐妹与当前节点位于同一级别,
也就是当前节点的平级节点
如下面的屏幕所示。 它将在当前节点之后找到该元素。
xpath=//*[@type='submit']//following-sibling::input

f)Parent:选择当前节点的父节点,如下面的屏幕所示。
Xpath=//*[@id='rt-feature']//parent::div
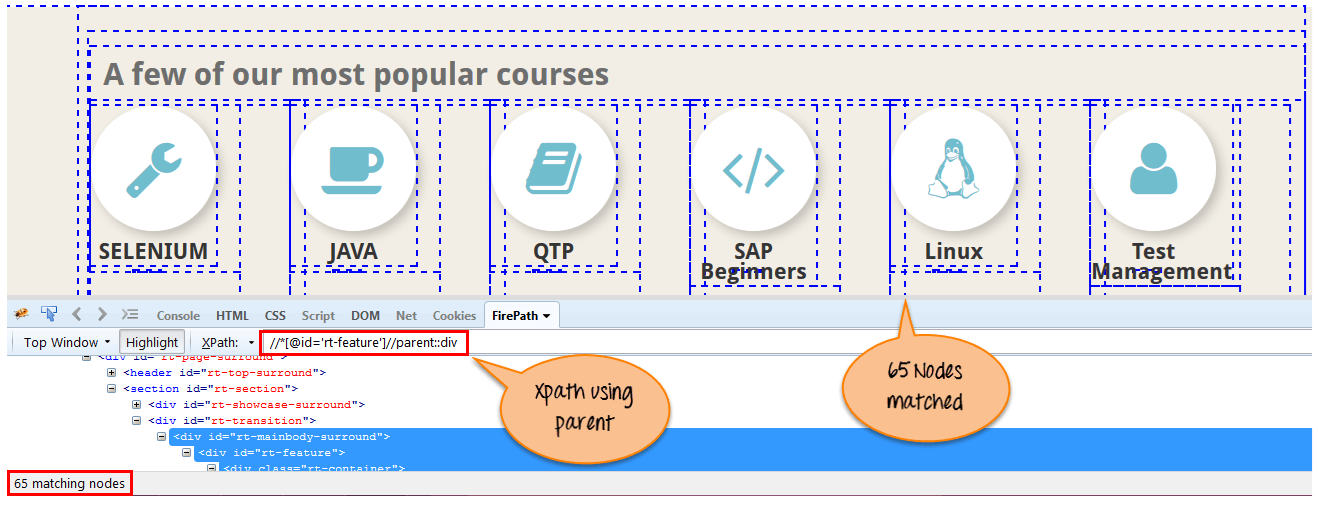
使用“parent”轴匹配65个“div”节点。 如果你想专注于任何特定的元素,那么你可以使用下面的XPath:
Xpath=//*[@id='rt-feature']//parent::div[1]
g)Self:选择当前节点或“self”表示它指示节点本身,如下面的屏幕所示。
Xpath =//*[@type='password']//self::input
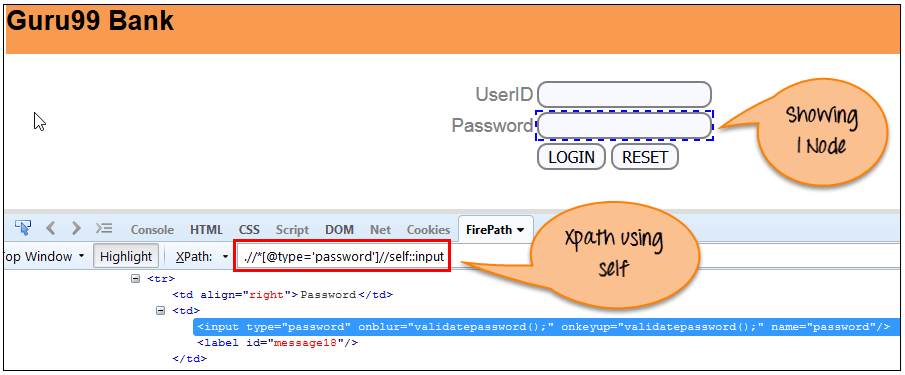
h)Descendant:选择当前节点的所有下层节点
Xpath=//*[@id='rt-feature']//descendant::a
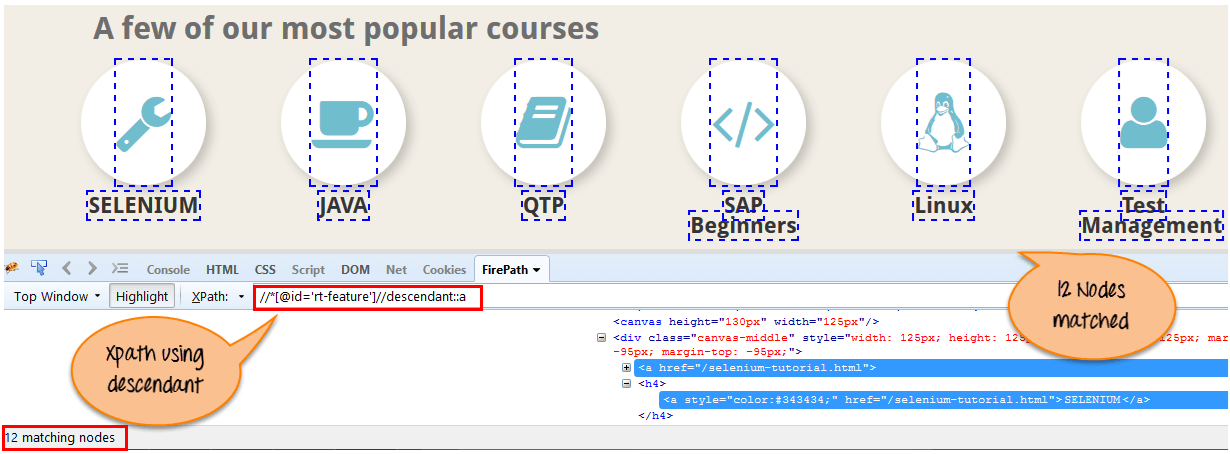
Xpath=//*[@id='rt-feature']//descendant::a[1]
XPath Axes是用于查找动态元素的方法,否则通过普通的XPath方法无法找到

