
SNN_文献阅读_Text Classification in Memristor-based Spiking Neural Networks
SNN中局部学习和非局部学习,基于梯度的规则都需要对用于表示单个连续值的脉冲训练窗口上的累积误差进行平均,这种方法在更新权重时考虑了每一个脉冲的影响。在计算速度和空间效率等方面,特别是当代表单个数值的脉冲序列很长的时候,以及在设计中涉及到记忆功能的时候,效率很低。
此外,与one-hot向量相比,在文本分类任务中,单词embedding和word2vec更常用于表示单词,以提高空间效率和映射单词之间的关系,提高分类精度。在训练过程中,他们被看作使用BP反向传播算法进行训练过的线性层。
但是在SNN中,embedding需要被转化为脉冲然后作为输入输入到网络中进行训练。到目前为止,还没有如何在SNN中训练单词嵌入的理论支持。
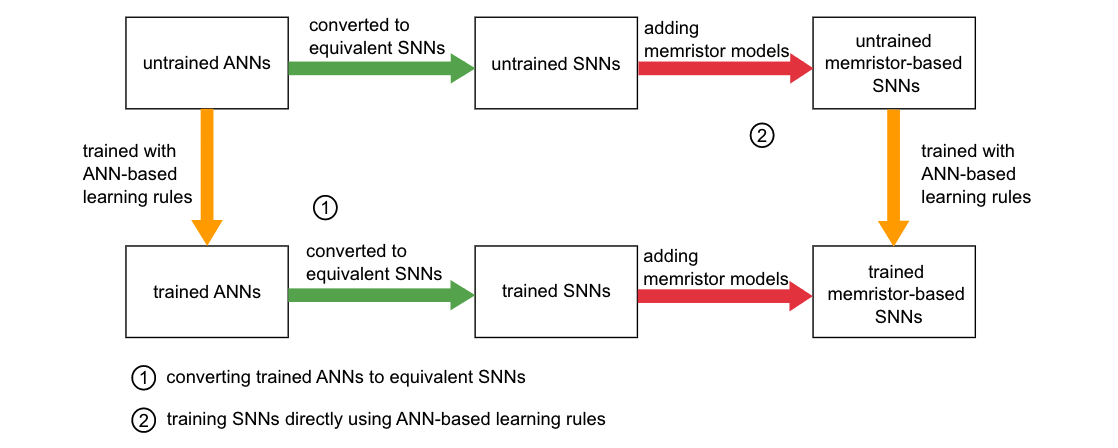
两种转换方法的原理图:
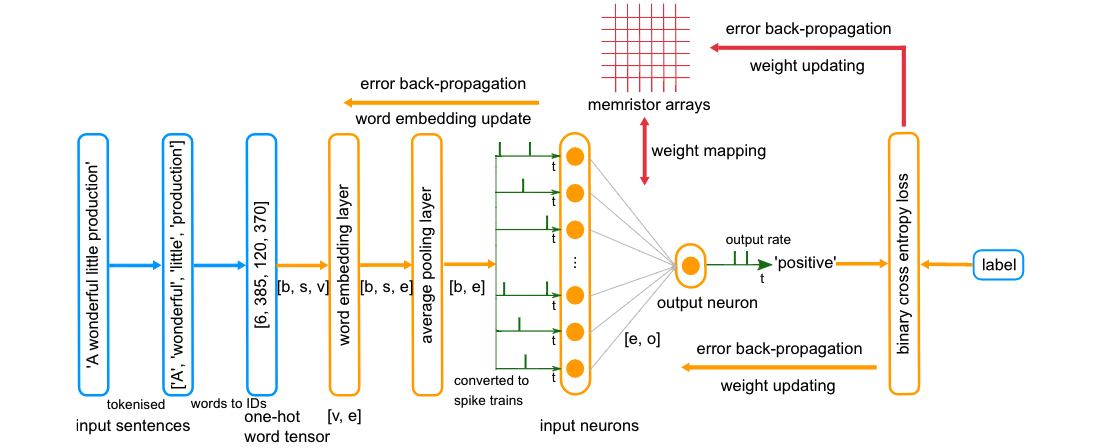
蓝色模块:输入模块
橙色模块:ANN结构模块
绿色:SNN特定结构模块
红色:忆阻器相关模块
b:批次大小,batchsize
s:句子长度
e:单词嵌入维度
o:输出维度
b、s、v
b:batch
s:句子长度
v:one-hot向量的维度
例如:
[’A‘,’Wonderful‘,’Little‘,’Production‘]
ID:[6,385,120,370]
将句子填充为相同的长度(s相同)
将词表转化为One-hot向量,将同一个batch的one-hot向量打包为(b * s * v)的输入表示张量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号