
SNN_文献阅读_Spiking Deep Convolutional Neural Networks for Energy-Efficient Object Recognition
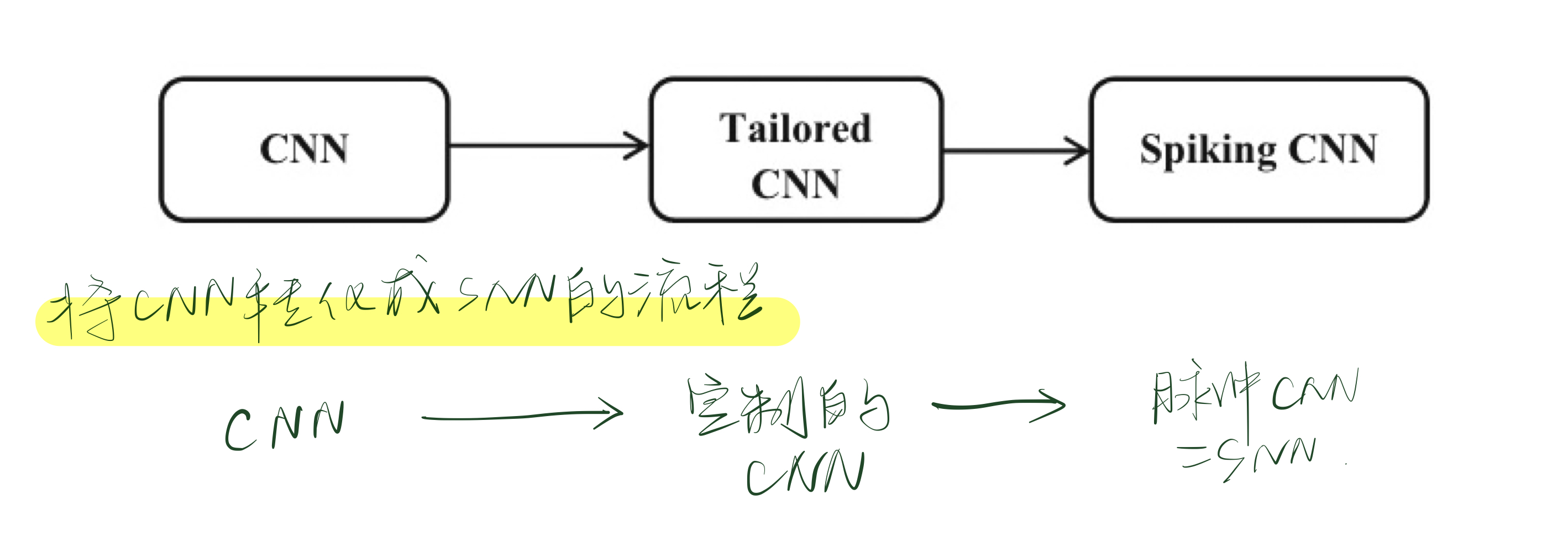
两种方法将CNN转化成为SNN:
- 直接训练一个类似CNN架构的SNN「虽然有类似于STDP等无监督方法,但是处于起步状态」
- 训练初始的CNN,将训练得到的权重直接应用于类似于CNN架构的SNN「将CNN转化为SNN的时候,训练的准确性可能无法保证」
准确性损失的原因:
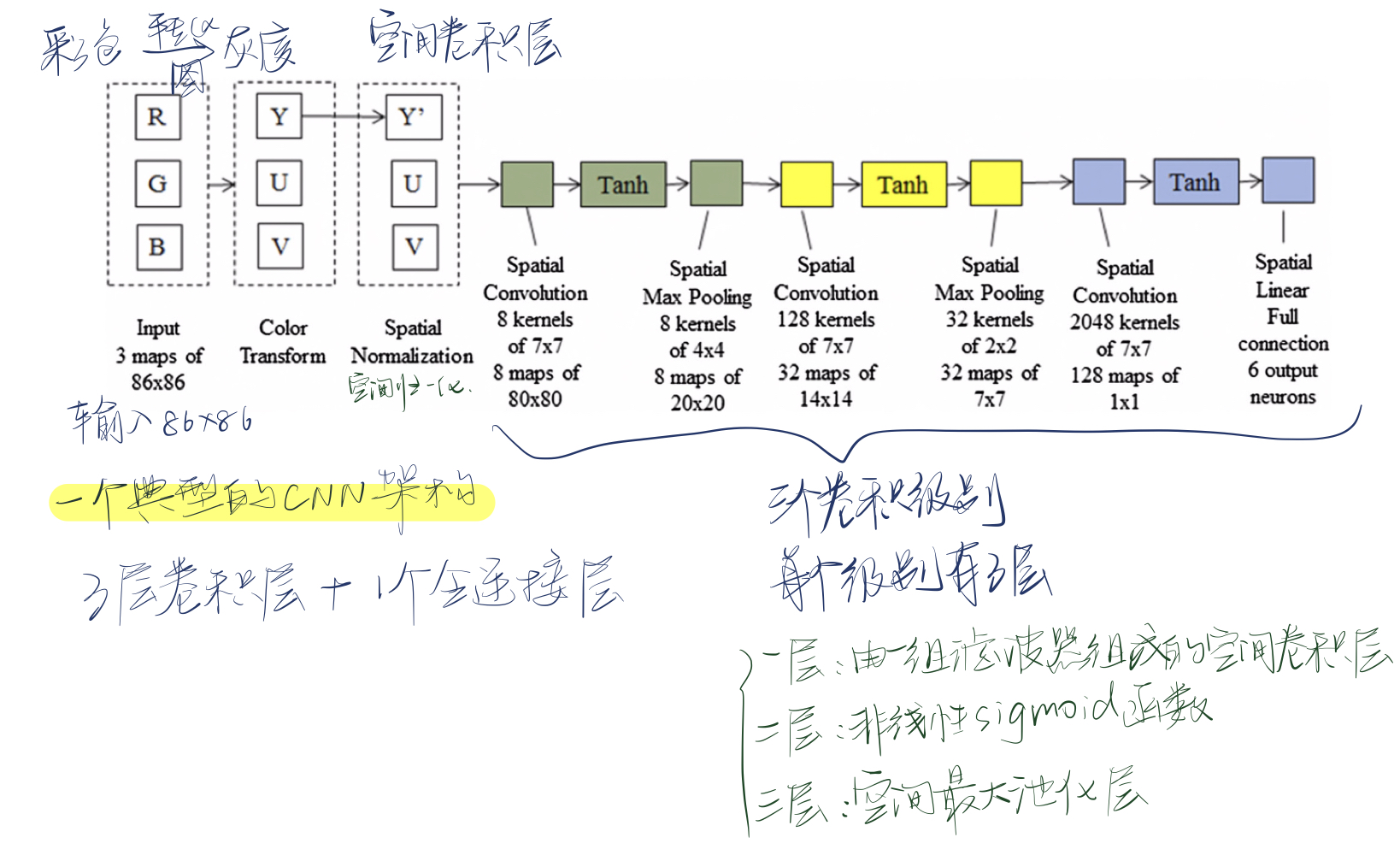
- CNN中的负值在SNN中无法准确表示,原因是:a.sigmoid函数tanh()的输出值介于-1.0和1.0之间;b.在每个卷积层中,每个输出特征映射的值都是输入加上偏差的加权和,权重和偏差都可能为负,导致输出值为负;c.预处理的输出值(例如颜色变换和空间标准化)可能会产生负值。「虽然抑制性神经元可以表示负值,但是需要增加很多的神经元,会增加计算成本。」
- 不同于CNN,SNN不能表示误差。每个卷积层中的误差可能是正的也可能是负的,在SNN中不能表示。
- 最大池化需要两层SNN。在CNN中,空间最大池化被限制在输入中一个小的图像邻域上获取最大输出值,在SNN中需要两层神经网络,第一层用来侧向抑制,第二层用来在小图像区域上进行聚集,这种方法需要更多的神经元,并且可能损失复杂性。
改进:
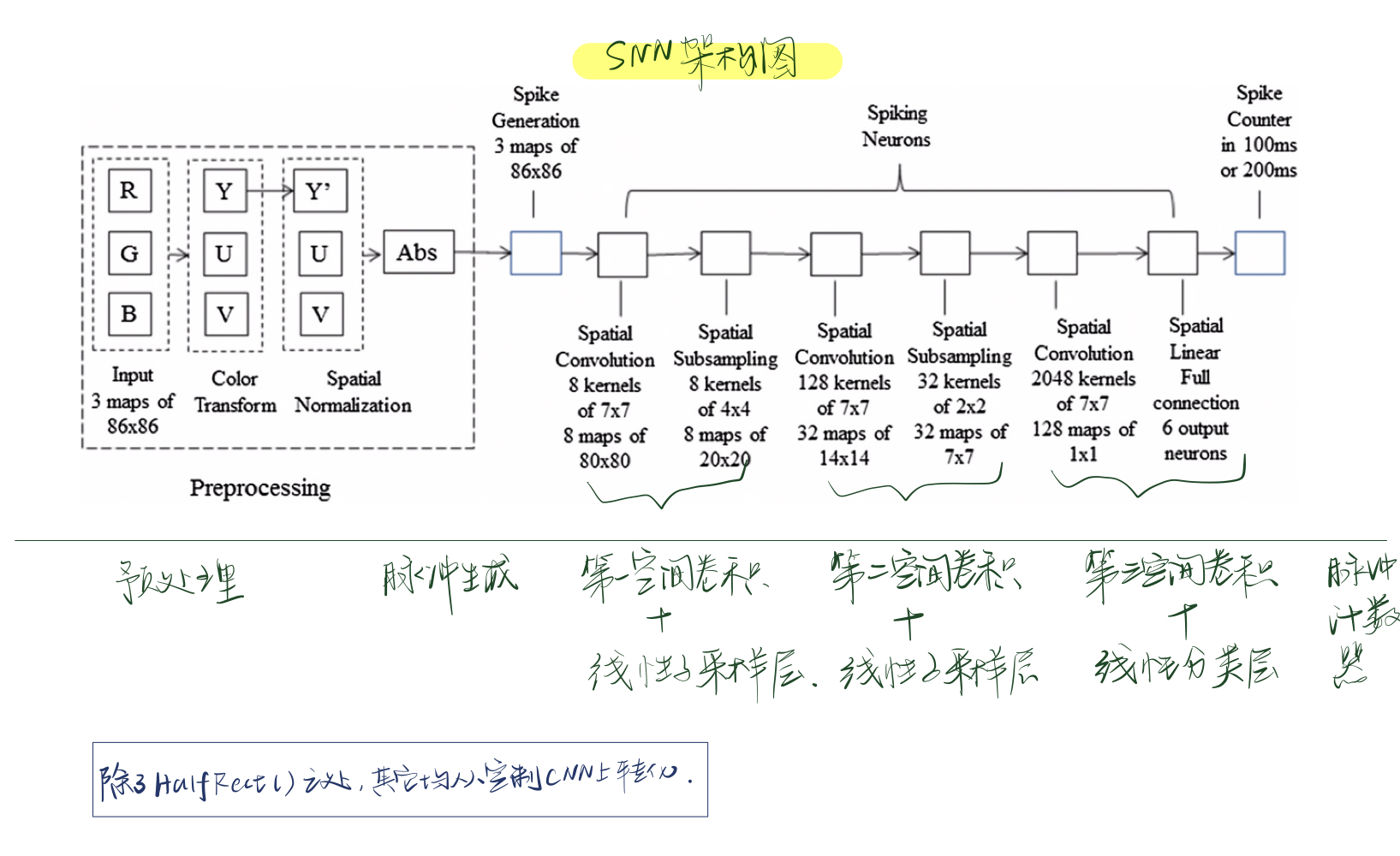
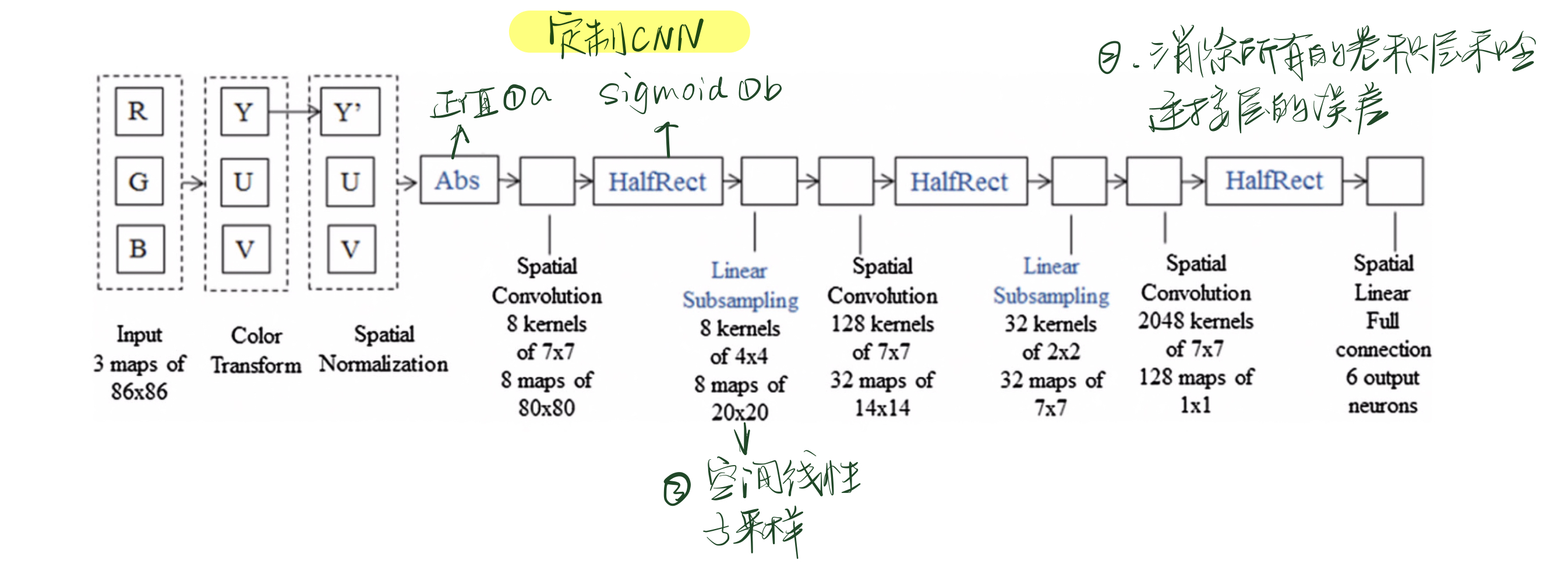
- 使所有层的输出值变为正值。a.在预处理后面加一个abs()函数,使得所有的值变为正值;b.将sigmoid函数从tanh()改成HalfRect(x),定义为\(HalfRect(x)=max(x,0)\),有很多优点,比如在训练的时候收敛的快,而且在\(x>0\)的时候是线性的,将转化的误差降到了最低。
- 消除所有卷积层和全联接层的误差。在每次训练迭代后将所有的误差值置0。
- 不用空间最大池化,而用空间线性子采样。空间线性子采样采用一个单一形式的权重核,将所有像素添加到一个小图像邻域上。空间线性子采样函数可以很容易地转换为脉冲域。
采用上述三条改进,可以将CNN转化为定制CNN。
integrate-and-fire neuron model模型进行更新:
\(V(t)=V(t-1)+L+X(t)\)
\(如果V(t)\geq \theta,脉冲和复位V(t)=0\)
\(如果V(t)<V_{min},复位后V(t)=V_{min}\)
\(L\)是常数,为泄漏参数;\(X(t)\)是连接的神经元的所有突触在时间\(t\)的总输入。当神经元电压\(V(t)\)超过阈值\(\theta\)的时候,神经元会激发一个脉冲,并且其膜电位\(V(t)\)置0。膜电位不能低于静止状态\(V_{min}\)。
第\(i\)层的神经元\((i,j)\)可以定义为:
\(X_{i,j}(t)=\displaystyle\sum_{p,q=-3}^3A_{p+i,q+j}(t)K_{pq}\)
其中\(A_{p+i,q+j}\)是来自前一层的输入脉冲(0或者1),\(K_{pq}\)是大小为7$\times$7的卷积核权重,由同一映射中的神经元共享。
ANN2SNN不仅局限于使用integrate-and-fire neuronmodel模型,还可以使用其他模型进行训练。
脉冲生成层的定义:\(I_{ijk}\)是输入到脉冲生成层的图像匹配。在时间\(t\)内,如果满足\(rand()<cI_{ijk}\),第\(k\)层图像匹配的神经元\((i,j)\)发射一个脉冲。其中,\(rand()\)是\((0.0,1.0)\)之间的随机数生成器,\(c\)是一个常数,用来缩放生成脉冲的频率。
实验结果:
Neovision2 Tower Dataset:
CIFAR-10 Dataset:
硬件:
\(Total\ energy=(5\times 10^5+2\times 10^7)]\alpha\\\cong2\times 10^7\alpha\ Joules/chip\)
\(P=2\times 10^7\alpha Joules/chip\times 30frame/s\times 5chips/ram=3\times 10^9\alpha Joules/s=3\times 10^9\alpha Watts\)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号