

数据挖掘(第四周)
# 代码8-1 查看数据特征
import numpy as np
import pandas as pd
inputfile = r'C:\Users\86138\Downloads\data\数据挖掘与分析\GoodsOrder.csv' # 输入的数据文件
data = pd.read_csv(inputfile,encoding = 'gbk') # 读取数据
data .info() # 查看数据属性
data = data['id']
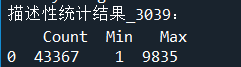
description = [data.count(),data.min(), data.max()] # 依次计算总数、最小值、最大值
description = pd.DataFrame(description, index = ['Count','Min', 'Max']).T # 将结果存入数据框
print('描述性统计结果_3039:\n',np.round(description)) # 输出结果
# 代码8-2 分析热销商品
# 销量排行前10商品的销量及其占比
import pandas as pd
inputfile = r'C:\Users\86138\Downloads\data\数据挖掘与分析\GoodsOrder.csv' # 输入的数据文件
data = pd.read_csv(inputfile,encoding = 'gbk') # 读取数据
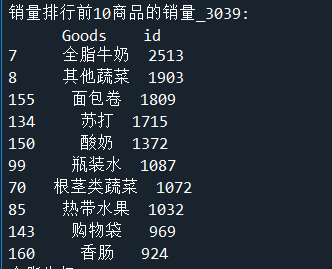
group = data.groupby(['Goods']).count().reset_index() # 对商品进行分类汇总
sorted=group.sort_values('id',ascending=False)
print('销量排行前10商品的销量_3039:\n', sorted[:10]) # 排序并查看前10位热销商品
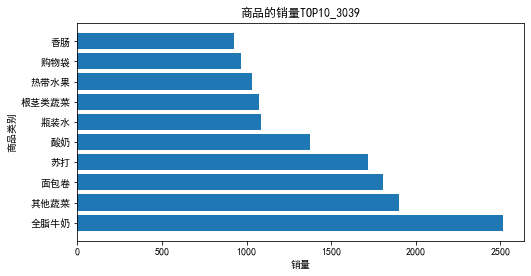
# 画条形图展示出销量排行前10商品的销量
import matplotlib.pyplot as plt
x=sorted[:10]['Goods']
y=sorted[:10]['id']
plt.figure(figsize = (8, 4)) # 设置画布大小
plt.barh(x,y)
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.xlabel('销量') # 设置x轴标题
plt.ylabel('商品类别') # 设置y轴标题
plt.title('商品的销量TOP10_3039') # 设置标题
plt.savefig(r'C:\Users\86138\Downloads\data\数据挖掘与分析\top10_3039.png') # 把图片以.png格式保存
plt.show() # 展示图片
# 销量排行前10商品的销量占比
data_nums = data.shape[0]
for idnex, row in sorted[:10].iterrows():
print(row['Goods'],row['id'],row['id']/data_nums)
条形图如下:
# 代码8-3 各类别商品的销量及其占比
import pandas as pd
inputfile1 = r'C:\Users\86138\Downloads\data\数据挖掘与分析\GoodsOrder.csv'
inputfile2 = r'C:\Users\86138\Downloads\data\数据挖掘与分析\GoodsTypes.csv'
data = pd.read_csv(inputfile1,encoding = 'gbk')
types = pd.read_csv(inputfile2,encoding = 'gbk') # 读入数据
group = data.groupby(['Goods']).count().reset_index()
sort = group.sort_values('id',ascending = False).reset_index()
data_nums = data.shape[0] # 总量
del sort['index']
sort_links = pd.merge(sort,types) # 合并两个datafreame 根据type
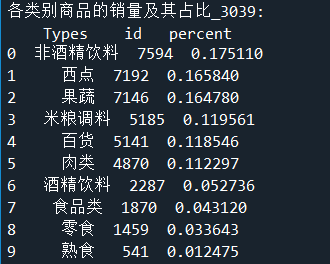
# 根据类别求和,每个商品类别的总量,并排序
sort_link = sort_links.groupby(['Types']).sum().reset_index()
sort_link = sort_link.sort_values('id',ascending = False).reset_index()
del sort_link['index'] # 删除“index”列
# 求百分比,然后更换列名,最后输出到文件
sort_link['count'] = sort_link.apply(lambda line: line['id']/data_nums,axis=1)
sort_link.rename(columns = {'count':'percent'},inplace = True)
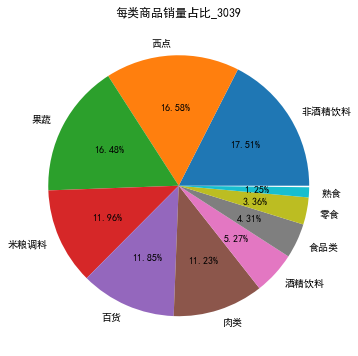
print('各类别商品的销量及其占比_3039:\n',sort_link)
outfile1 = r'C:\Users\86138\Downloads\data\数据挖掘与分析\percent.csv'
sort_link.to_csv(outfile1,index = False,header = True,encoding='gbk') # 保存结果
# 画饼图展示每类商品销量占比
import matplotlib.pyplot as plt
data = sort_link['percent']
labels = sort_link['Types']
plt.figure(figsize=(8, 6)) # 设置画布大小
plt.pie(data,labels=labels,autopct='%1.2f%%')
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.title('每类商品销量占比_3039') # 设置标题
plt.savefig(r'C:\Users\86138\Downloads\data\数据挖掘与分析\persent_3039.png') # 把图片以.png格式保存
plt.show()
饼状图如下:
# 代码8-4 酒精饮料内部商品的销量及其占比
# 先筛选“酒精饮料”类型的商品,然后求百分比,然后输出结果到文件。
selected = sort_links.loc[sort_links['Types'] == '酒精饮料'] # 挑选商品类别为“非酒精饮料”并排序
child_nums = selected['id'].sum() # 对所有的“酒精饮料”求和
selected['child_percent'] = selected.apply(lambda line: line['id']/child_nums,axis = 1) # 求百分比
selected.rename(columns = {'id':'count'},inplace = True)
print('酒精饮料内部商品的销量及其占比_3039:\n',selected)
outfile2 = r'C:\Users\86138\Downloads\data\数据挖掘与分析\child_percent.csv'
sort_link.to_csv(outfile2,index = False,header = True,encoding='gbk') # 输出结果
# 画饼图展示酒精饮品内部各商品的销量占比
import matplotlib.pyplot as plt
data = selected['child_percent']
labels = selected['Goods']
plt.figure(figsize = (8,6)) # 设置画布大小
explode = (0.02,0.03,0.04,0.05,0.06,0.07,0.08,0.08,0.3,0.1,0.3) # 设置每一块分割出的间隙大小
plt.pie(data,explode = explode,labels = labels,autopct = '%1.2f%%',
pctdistance = 1.1,labeldistance = 1.2)
plt.rcParams['font.sans-serif'] = 'SimHei'
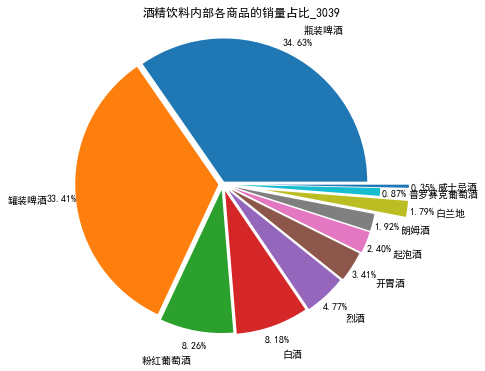
plt.title("酒精饮料内部各商品的销量占比_3039") # 设置标题
plt.axis('equal')
plt.savefig( r'C:\Users\86138\Downloads\data\数据挖掘与分析\child_percent_3039.png') # 保存图形
plt.show() # 展示图形
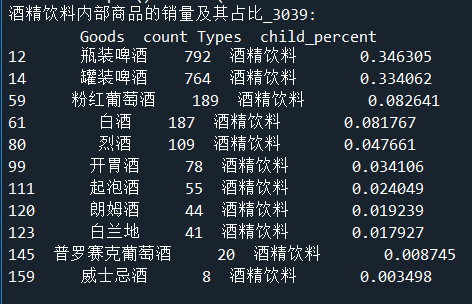
饼图如下:
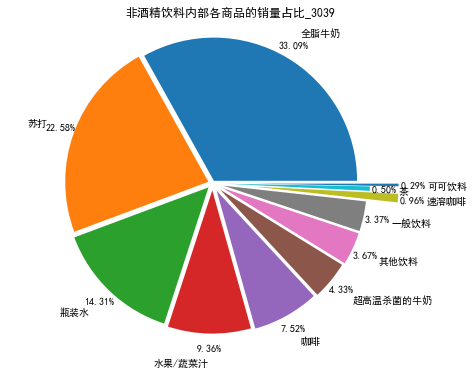
# 代码8-4 非酒精饮料内部商品的销量及其占比
# 先筛选“非酒精饮料”类型的商品,然后求百分比,然后输出结果到文件。
selected = sort_links.loc[sort_links['Types'] == '非酒精饮料'] # 挑选商品类别为“非酒精饮料”并排序
child_nums = selected['id'].sum() # 对所有的“非酒精饮料”求和
selected['child_percent'] = selected.apply(lambda line: line['id']/child_nums,axis = 1) # 求百分比
selected.rename(columns = {'id':'count'},inplace = True)
print('非酒精饮料内部商品的销量及其占比_3039:\n',selected)
outfile2 = r'C:\Users\86138\Downloads\data\数据挖掘与分析\child_percent.csv'
sort_link.to_csv(outfile2,index = False,header = True,encoding='gbk') # 输出结果
# 画饼图展示非酒精饮品内部各商品的销量占比
import matplotlib.pyplot as plt
data = selected['child_percent']
labels = selected['Goods']
plt.figure(figsize = (8,6)) # 设置画布大小
explode = (0.02,0.03,0.04,0.05,0.06,0.07,0.08,0.08,0.3,0.1,0.3) # 设置每一块分割出的间隙大小
plt.pie(data,explode = explode,labels = labels,autopct = '%1.2f%%',
pctdistance = 1.1,labeldistance = 1.2)
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.title("非酒精饮料内部各商品的销量占比_3039") # 设置标题
plt.axis('equal')
plt.savefig( r'C:\Users\86138\Downloads\data\数据挖掘与分析\child_percent_3039.png') # 保存图形
plt.show() # 展示图形
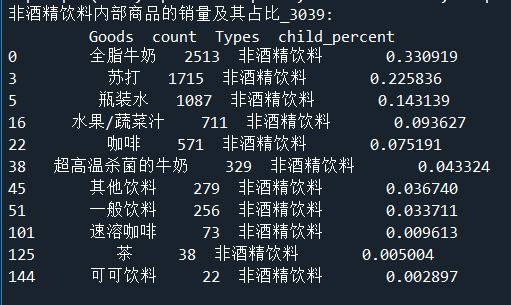
饼图如下:
# 代码8-5 数据转换
import pandas as pd
inputfile=r'C:\Users\86138\Downloads\data\数据挖掘与分析\GoodsOrder.csv'
data = pd.read_csv(inputfile,encoding = 'gbk')
# 根据id对“Goods”列合并,并使用“,”将各商品隔开
data['Goods'] = data['Goods'].apply(lambda x:','+x)
data = data.groupby('id').sum().reset_index()
# 对合并的商品列转换数据格式
data['Goods'] = data['Goods'].apply(lambda x :[x[1:]])
data_list = list(data['Goods'])
# 分割商品名为每个元素
data_translation = []
for i in data_list:
p = i[0].split(',')
data_translation.append(p)
print('数据转换结果的前5个元素_3039:\n', data_translation[0:5])

posted on 2023-03-15 15:15 蓝螃蟹Karry0921 阅读(39) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号