
ANOSIM分析
ANOSIM分析(analysis of similarities)即相似性分析,主要用于分析高维数据组间相似性,为数据间差异显著性评价提供依据。在一些高维数据分析中,需要使用PCA、PCoA、NMDS等方法进行降维,但这些方法并不显示组间差异的显著性指标,此时可以使用ANOSIM分析解决此问题。
ANOSIM为非参数检验方法,用于评估两组实验数据的整体相似性及相似的显著性。
该方法主要有两个数值结果:一个是R,用于不同组间否存在差异;一个是P,用于说明是否存在显著差异。以下分别对两个数值进行说明:
R值的计算公式如下:
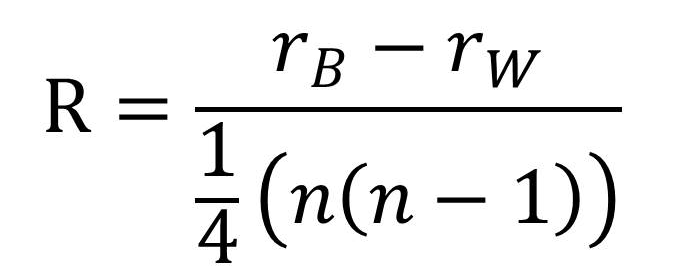
rB:组间差异性秩的平均值(mean rank of between group dissimilarities)
rW:组内差异性秩的平均值(mean rank of within group dissimilarities)
n:总样本个数(the number of samples)
R的范围为[-1,1]
R>0说明组间差异大于组内差异,R<0组间差异小于组内差异。
R只是组间是否有差异的数值表示,并不提供显著性说明。
P值则说明不同组间差异是否显著,该P值通过置换检验(Permutation Test)获得。
置换检验大致原理:(假设原始分组为实验组和对照组)
1、对所有样本进行随机分组,即实验组和对照组。
2、计算当前分组时的R值,即为Ri。
3、重复当前操作N次,对所有Ri及原始R从大到小排序,R所处的位置除以N即为置换检验P值。
举例说明:
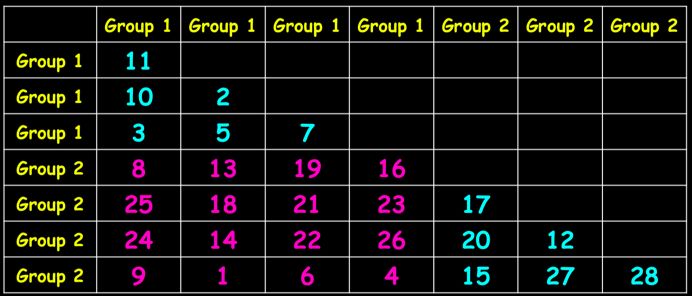
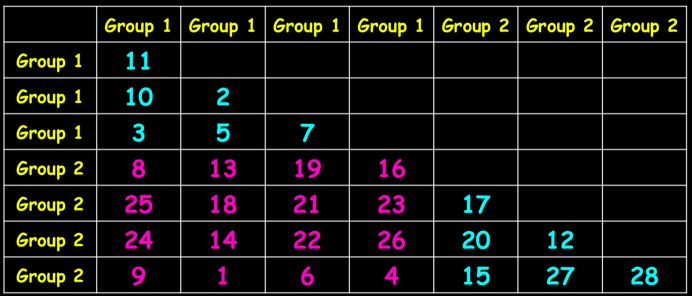
比如我们有case和control两组(Group1 和Group 2),数据如下:
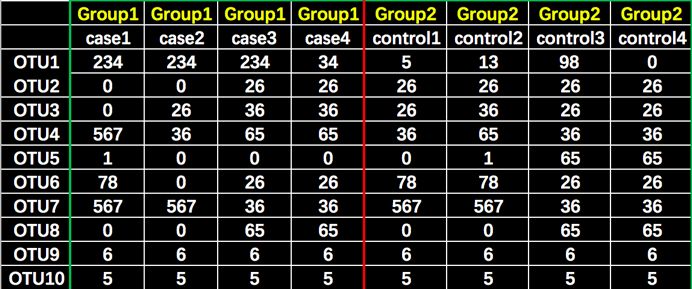
首先需要对样本进行相似性计算,得到如下差异性(即距离矩阵)矩阵:
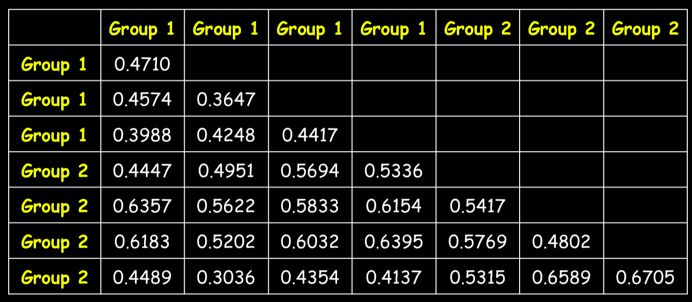
然后计算差异性秩(即从小到大排序),如此便把差异性矩阵转换为秩矩阵:
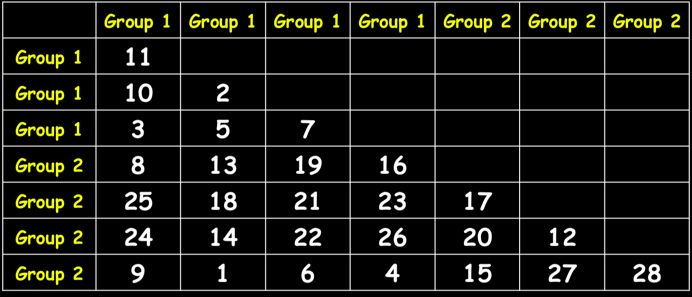
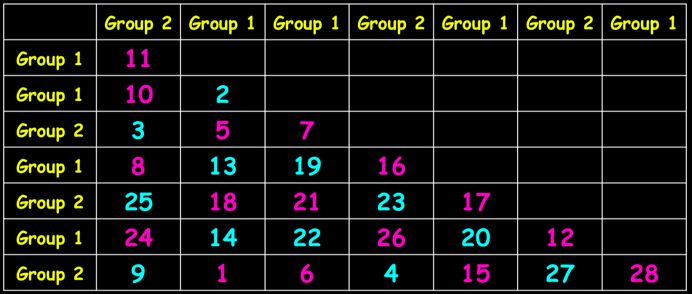
接着计算组内差异性平均秩和组间差异性平均秩,rW=13.08,rb = 15.56,如此R=(15.56-13.08)/(0.25*8*7) = 0.17
利用置换检验的方法计算p值,如下的方法重复1000次, rb= 14.06,rw = 15.08
根据1000次随机后获得的Ri与R进行排序,获得P值。
可以使用R语言进行ANOSIM分析,使用的R包为vegan,函数为anosim。
其帮助文档提供的程序为:
1 2 3 4 5 | data(dune)<br>data(dune.env)dune.dist <- vegdist(dune)dune.ano <- with(dune.env, anosim(dune.dist, Management))summary(dune.ano)plot(dune.ano) |
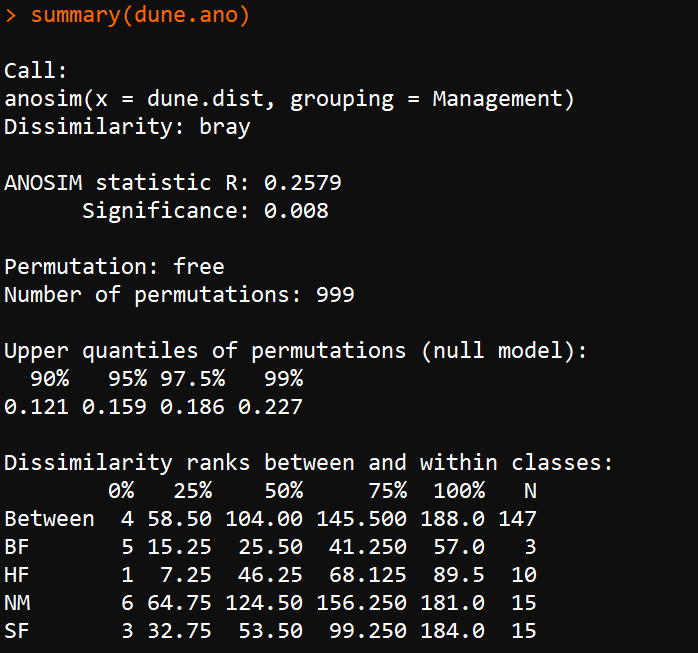
summary(dune.ano)结果为:
plot画出的图形为:
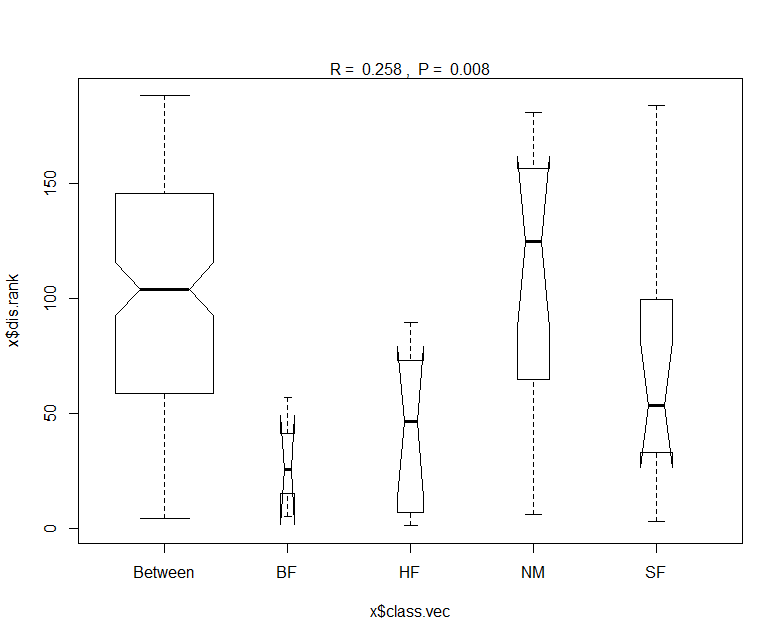
不难看出,图中箱子为summary结果中的Dissimilarity ranks between and within classes的可视化,即组间差异秩分布和组内差异秩分布(下图中的数值分布)。
(致谢:以上内容参考 博文 http://www.360doc.com/content/18/0113/21/33459258_721682039.shtml )
本文作者:--看日出--
本文链接:https://www.cnblogs.com/KanRiChu/p/12016362.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步