
数据结构与金融算法 18-19秋季学期 期中考试简略题解
1.一个满二叉树的定义是,所有的节点要么有两个子节点,要么没有子节点。定义Bn为:n个节点的满二叉树,对应的二叉树数量。对称的两个树分别计算。求证:Bn∈Ω(2n)
比如,B1=1,B3=1,B5=2。
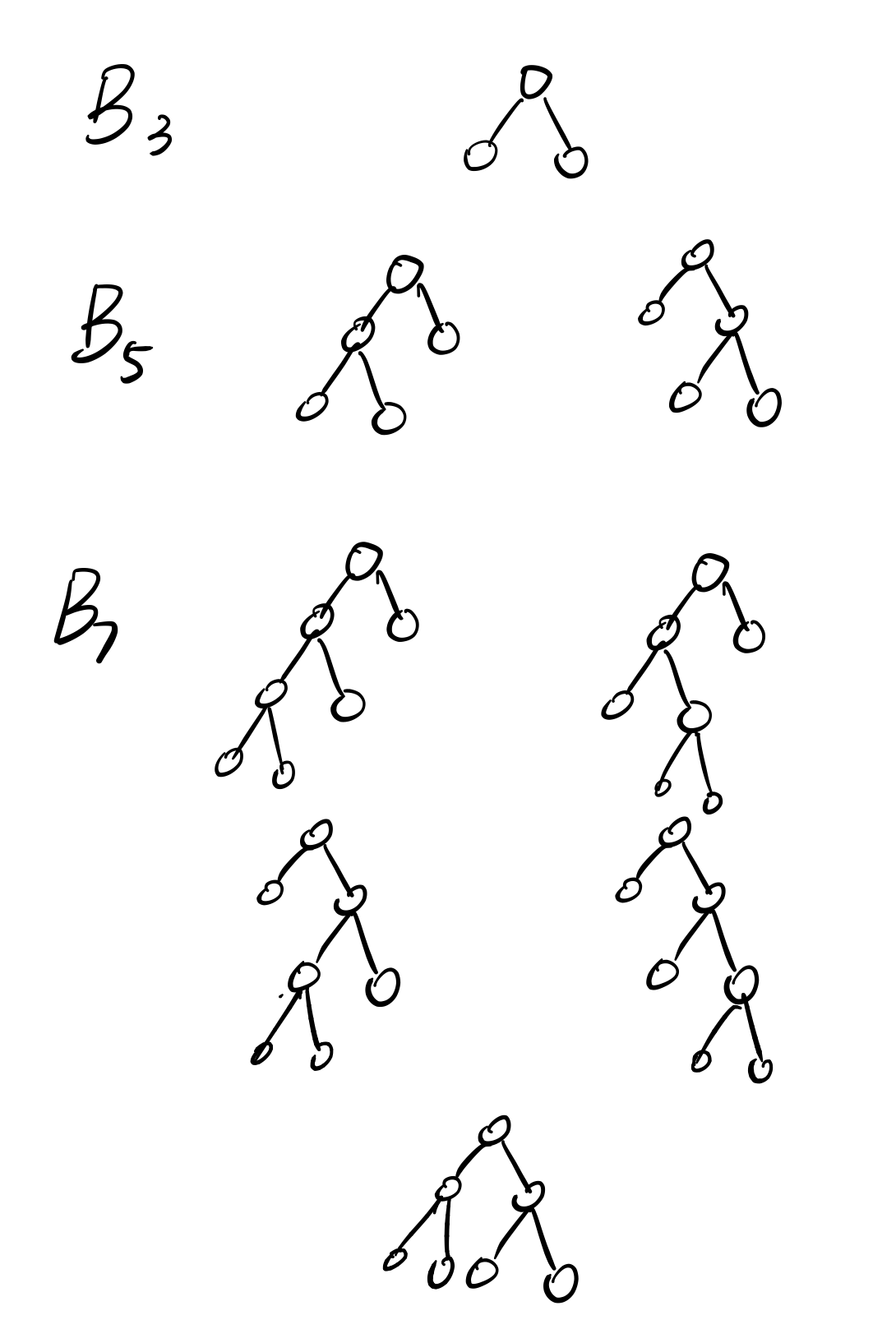
这题的关键在于求出Bn的递推式。多画几次就能发现,实际上对于一颗Bn树,包含的情况有一边子树为B1,一边子树为Bn-2。依次类推可以得到如下递推式:
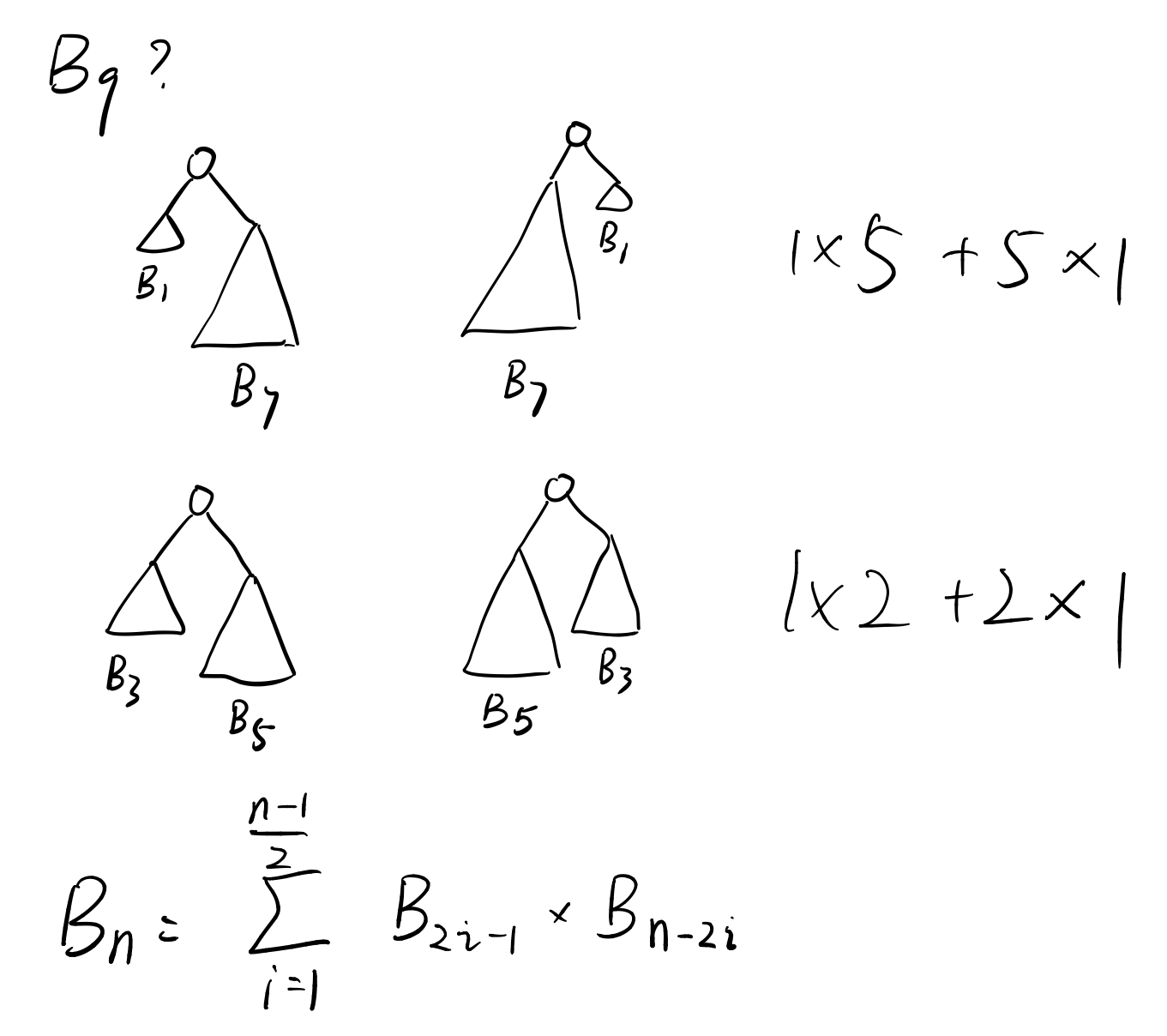
那么,就可以运用一下数学归纳法。如果能从Bn-2,Bn-4之类的入手,得到一个放缩的式子大于等于2n的话,那就再好不过了。
不过很可惜,如果直接Bn = 2Bn-2 x B1 + 2Bn-4 x B3 + 2Bn-6 x B5 + ... ≥ 2 · 2n-2 · 1 + 2 · 2n-4 · 1 + 2 · 2n-6 · 4 + ...,需要算到起码Bn-20之后才能满足放缩条件。这在正常做题中显然是没办法的。
但是我们可以验证(猜想),当n足够大时,B(n-1)/2是足够大于2n的。那么只要我们从折半的地方入手,很容易就能从类似B(n-1)/2 x B(n-1)/2这样的式子中推出放缩式。具体细节就不再赘述了,读者可以自行验证。
2. 当前有一个大小为n的无序列表,以及一个数S。设计一个O(nlgn)算法,寻找列表里面是否有两个数加和等于S。
既然是nlgn算法,当然需要先排序一下,这里的代价就是nlgn了。
然后,可以考虑这样一个线性的算法:
假设有序列表为x。现在让两个指针,left和right,分别指向x[0]和x[n-1]。
然后,若x[left] + x[right] > S,则right -= 1,而若是 < S,则left += 1。
终止条件为x[left] + x[right] == S或者left == right。
显然这是一个线性算法。代码如下:
#...处理x,已知S left = 0 right = n-1 while left < right: if x[left] + x[right] < S: left += 1 else if x[left] + x[right] > S: right -= 1 else: return true return false
举一个例子可能有助于理解:

算法的正确性可以这么考虑:由于数组有序,当left右移,l + r的大小就会增加,反之,right左移,l + r就会减小。无论l + r与S有什么关系,每一次循环总能找到进行一次退出或将right - left减少1的操作。由于right - left最大为n -1,因此这个算法是线性的。
3. 现在有n个处于区间[0, m]的整数,要求经过O(n+m)的预处理之后,可以用O(1)的算法返回位于指定区间[a, b]之间的数的个数。
仔细思考一下会发现,预处理其实就是制作出一个类似于离散型分布函数的数组。
设数据数组为S,分布数组为D。首先,我们可以遍历S,对于一个数i,就使D[k] += 1。然后得出一个类似分布律的东西。实际上,把数组里的每个数除以n,就得到了S的分布律。
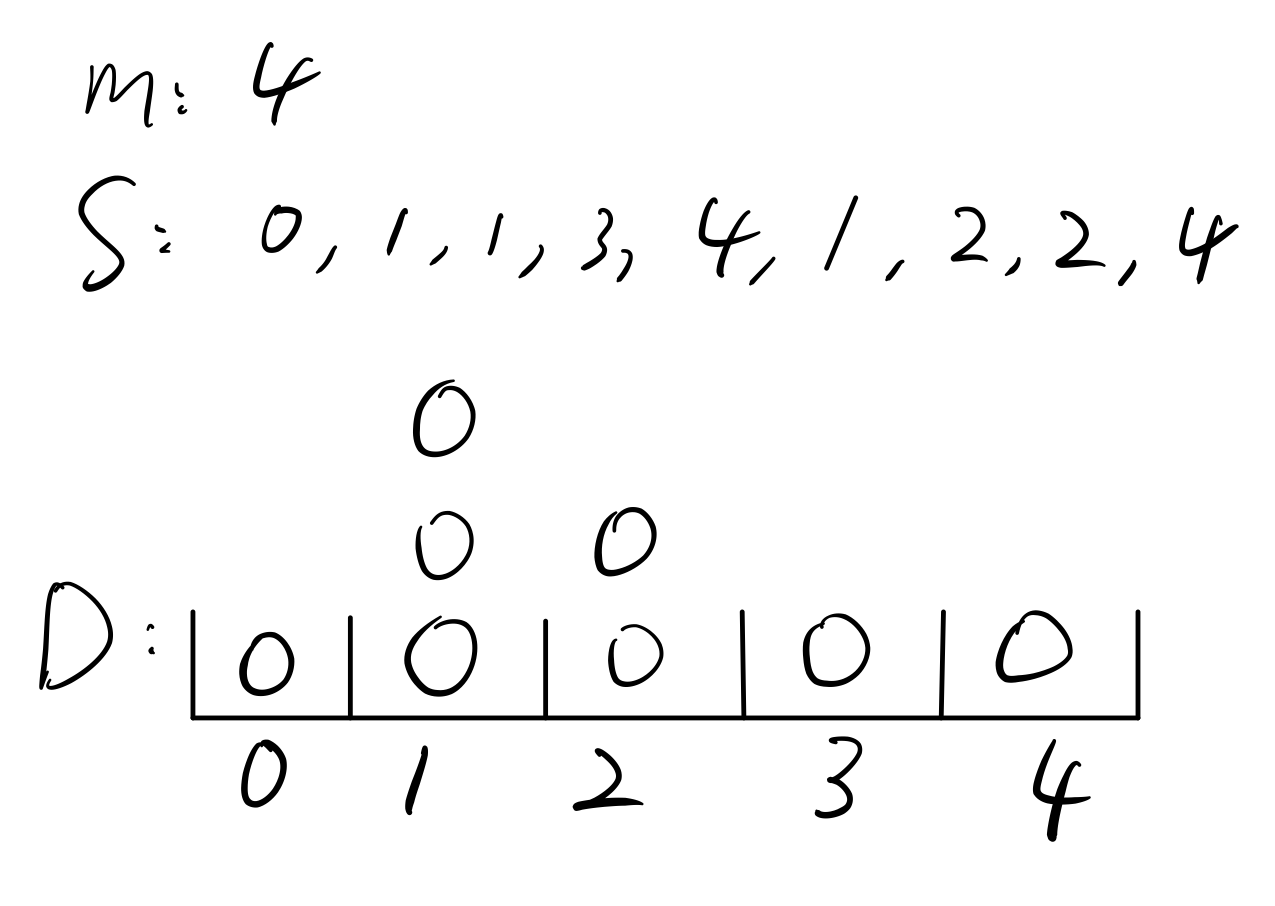
然后,将前一个格的东西加和到后一格,就可以得出分布函数了。
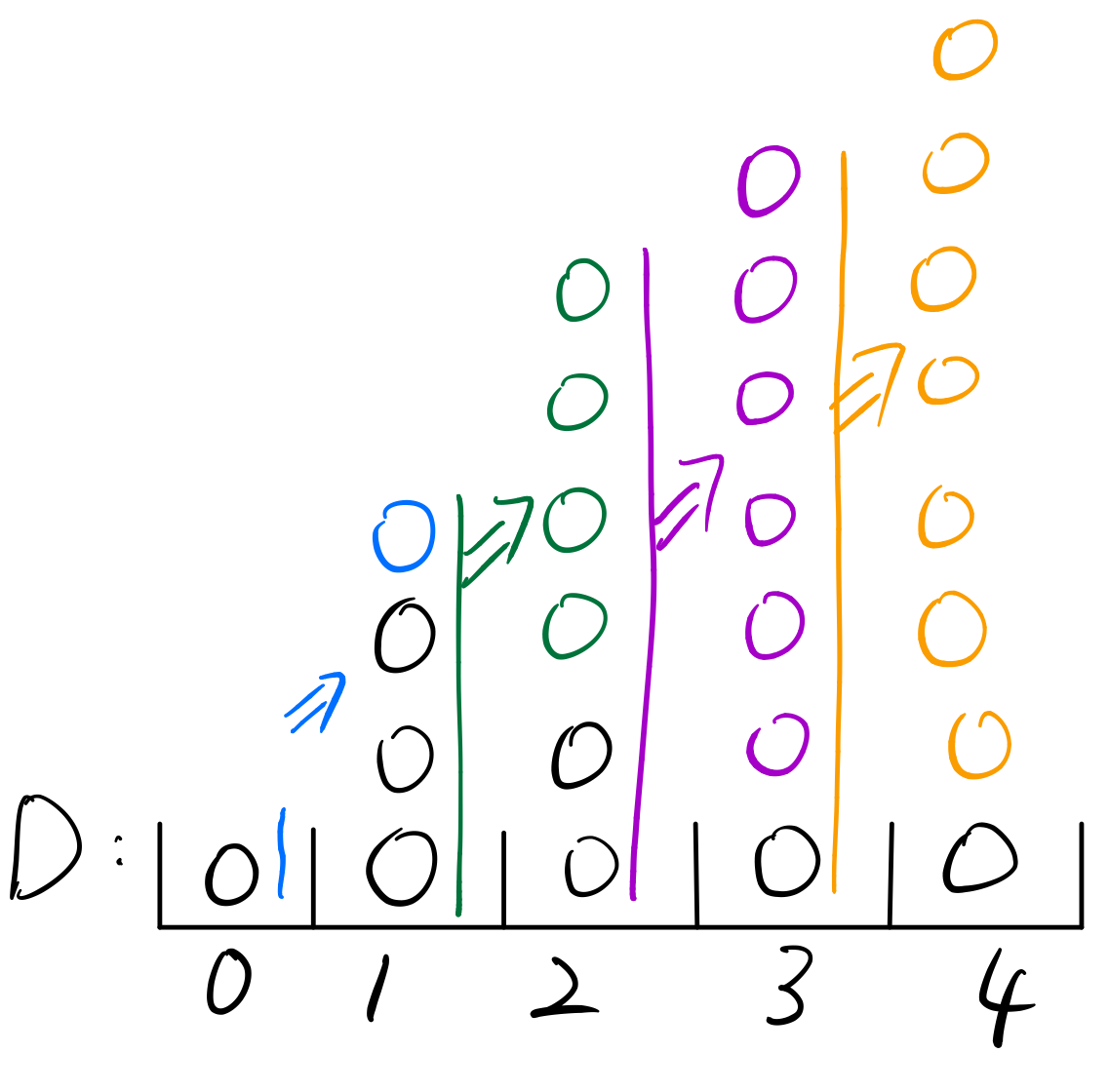
最后要注意,查询函数是D[b] - D[a - 1],否则就会缺少a上的数值了!
4. 对于一个栈,给定两个操作:
Ordered-push( x ):如果x < 栈顶元素first,就弹出first,直到满足x ≥ first为止,然后插入x。
Pop( x ):弹出first。
用摊还分析计算操作代价。
考虑实际代价:
- O-push:2i + 2。假设弹出了i个元素,则比较次数为i + 1,弹出次数为i,插入次数为1,共2i + 2。
- Pop:1。
那么,如何分析会计代价呢?
一般的会计代价分析,需要将一个大代价的操作平摊到小代价操作上。然而由于这题的O-push大部分的代价本质上也是pop,所以分摊到小pop操作上显然是不合适的。
所以,这题需要O-push自我分摊。方案是这样的:
- 弹出i个元素之前,必然需要先进行i次O-push操作。
- 那么,就可以将2i分摊到pop出的i个元素中,每个元素分配2的代价。
这样,会计代价就是:
- O-push:-2i + 2。-2i是分摊出去的,2是被分摊到的。
- Pop:0
所以,摊还代价为:
- O-push:4
- Pop:1
整个数据类型的操作代价是O(1)。
5. 对于一个有向图,
(1)设计O(n+m)的算法,判断从一个特定的点v是否可以到达图上所有点;
(2)设计O(n+m)的算法,判断图中是否存在点,可达图上所有点。
首先摆dfs框架:
def dfs(adjVers, color, v): color[v] = gray <preorder proc> remAdj = adjVers[v] while remAdj: w = remAdj.first() if (color[v] == white): <exploratory proc for vw> wAns = dfs(adjVers, color, w) <backtrace proc for vw> else: <checking nontree edge vw> remAdj = remAdj.rest() <postorder proc> color[v] = black return ans
先看看第一题。方法是多种多样的。
- 我们可以利用活跃区间,即记录一个点探索到的时间和结束探索的时间。在从v开始进行dfs的时候,如果v是最后一个结束访问的节点,即可以得出v可以到达所有的点。
- 除此之外,也可以利用点的着色,看看v之后是否还有白色点。如果没有则v满足条件。
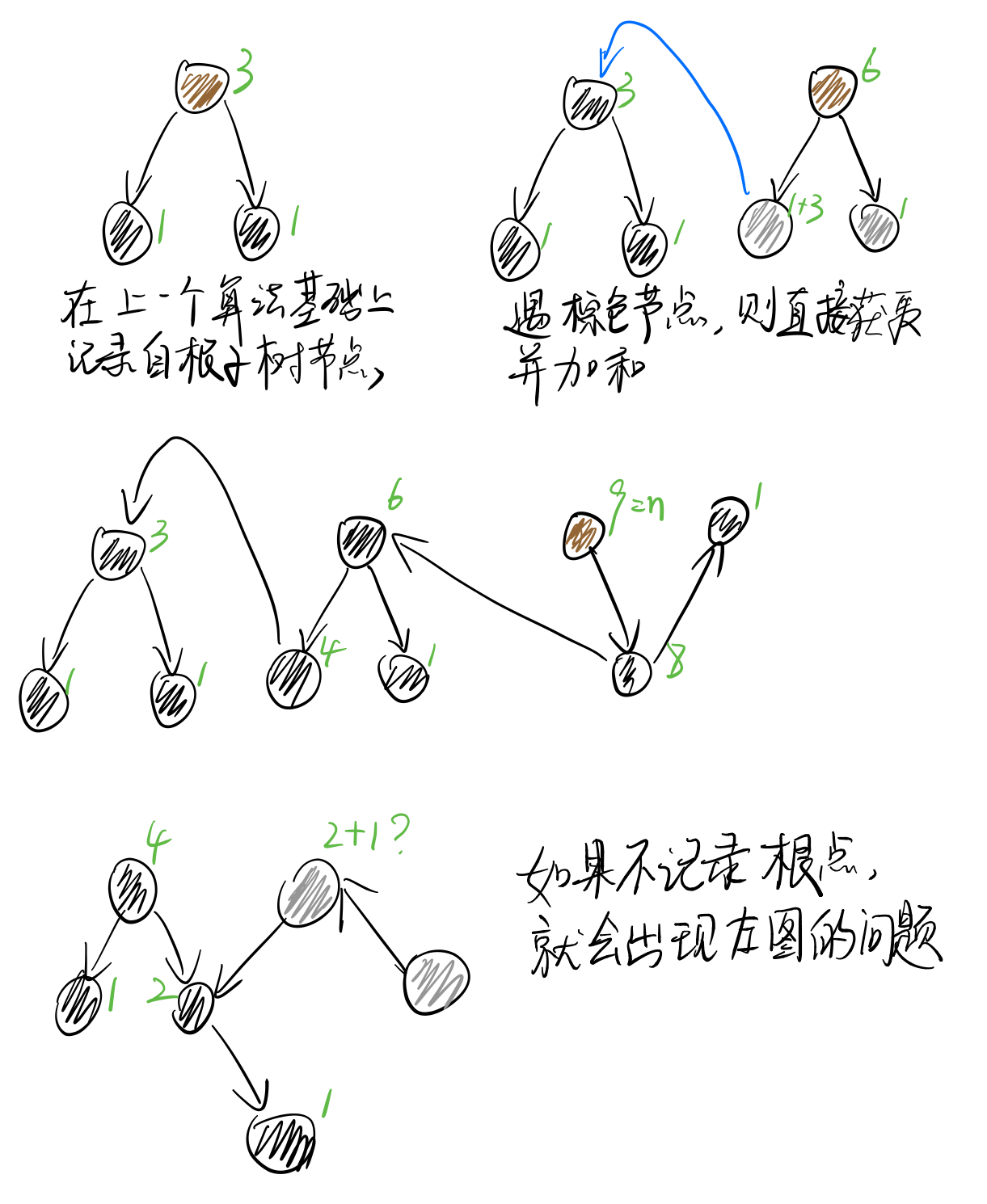
- 我自己的做法有点绕:在dfs过程中,记录一个点以自己为根的子树包含的节点数。如果v的这个数为n,说明v满足条件。
对于我自己的做法,要对dfs做出如下更改:
#preorder proc ans = 1 #backtrace proc for vw ans += wAns
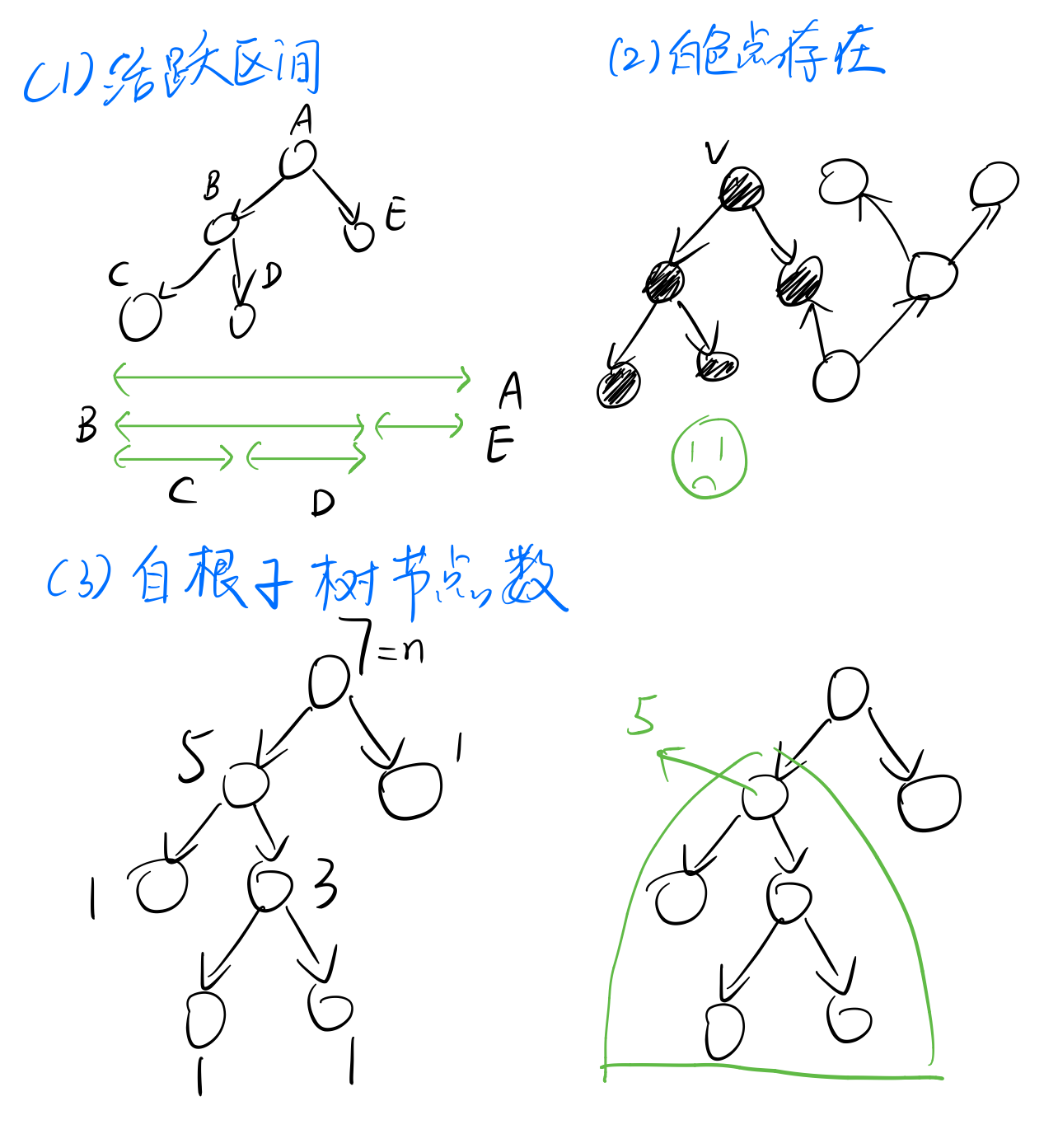
而对于第二题,关键在于,在dfs结束后,最后一个dfs树的根是否可达所有的点。至于为什么可以仔细想想,大概可以往反证法的方向考虑。
所以基于这个思想,可以在dfs过程中记录这个最后的根,并在dfs结束后对这个根运用(1)的算法。

仔细考虑会发现,如果这样的点存在,那么如果在dfs过程中,在寻找到根时把根接入,那么最终只会剩下一个dfs树。
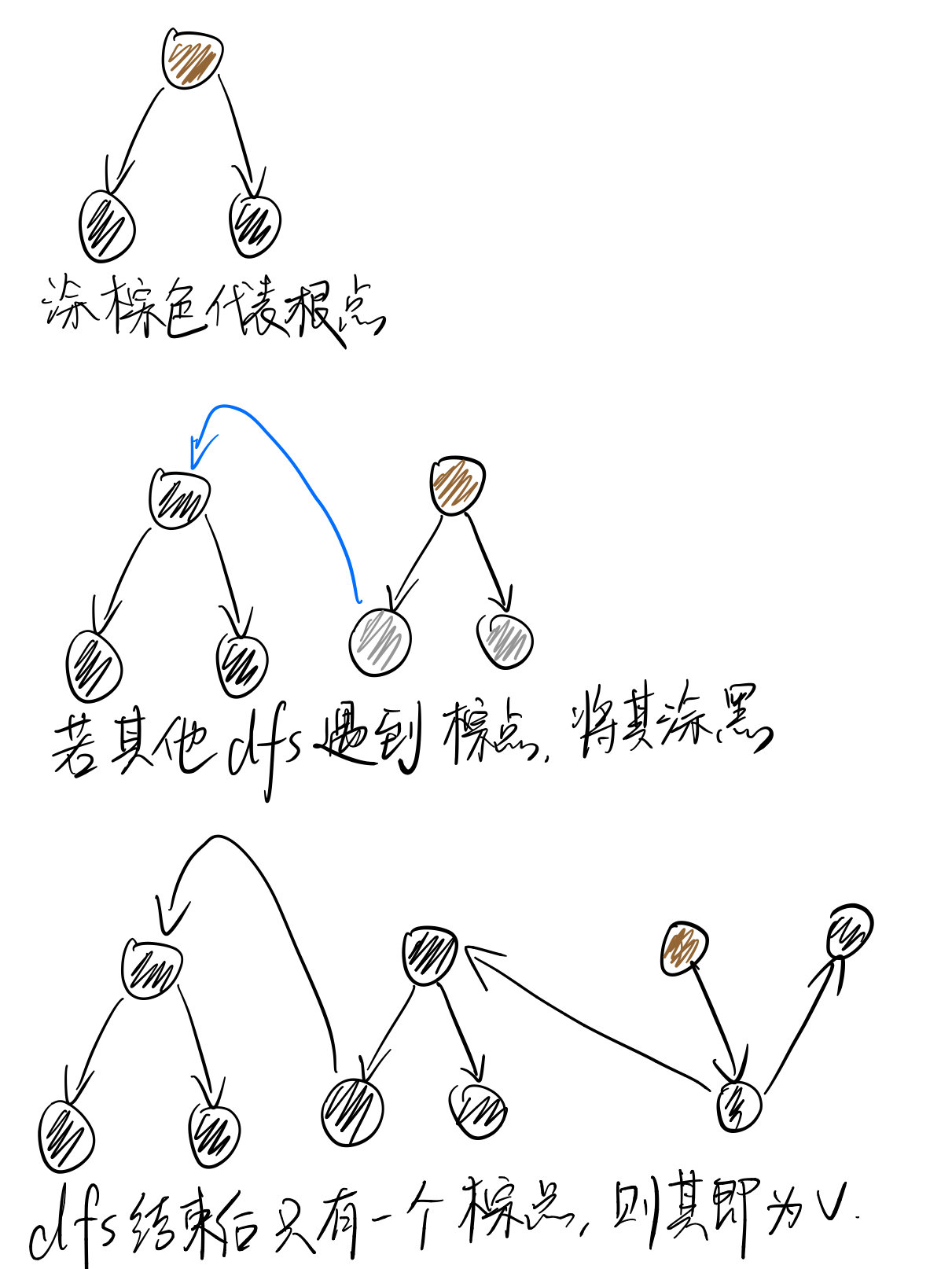
这个时候既可以用记录自根子树节点数的方法,也可以用单纯记录根的方法。殊途同归。
然而要注意,用自根子树节点数方法时,其实也需要记录根,而不能仅仅靠黑色节点。否则会出现问题。
6. 一个二进制数N有n位,可以进行以下操作:
1. Addition(x, y),将x+y的结果保存在x中。
2. Shift(x, d),将x左移或右移一位,方向取决于d,1为左移,-1为右移。
现在用以上操作设计两个算法:
1. 用O(n)次Addition和Shift求出N2。
2. 用O(n2)次Addition和Shift求出⌈√N⌉。
第一题还是很好做的。如果自己模拟一下乘法,就能知道怎么写这个算法。
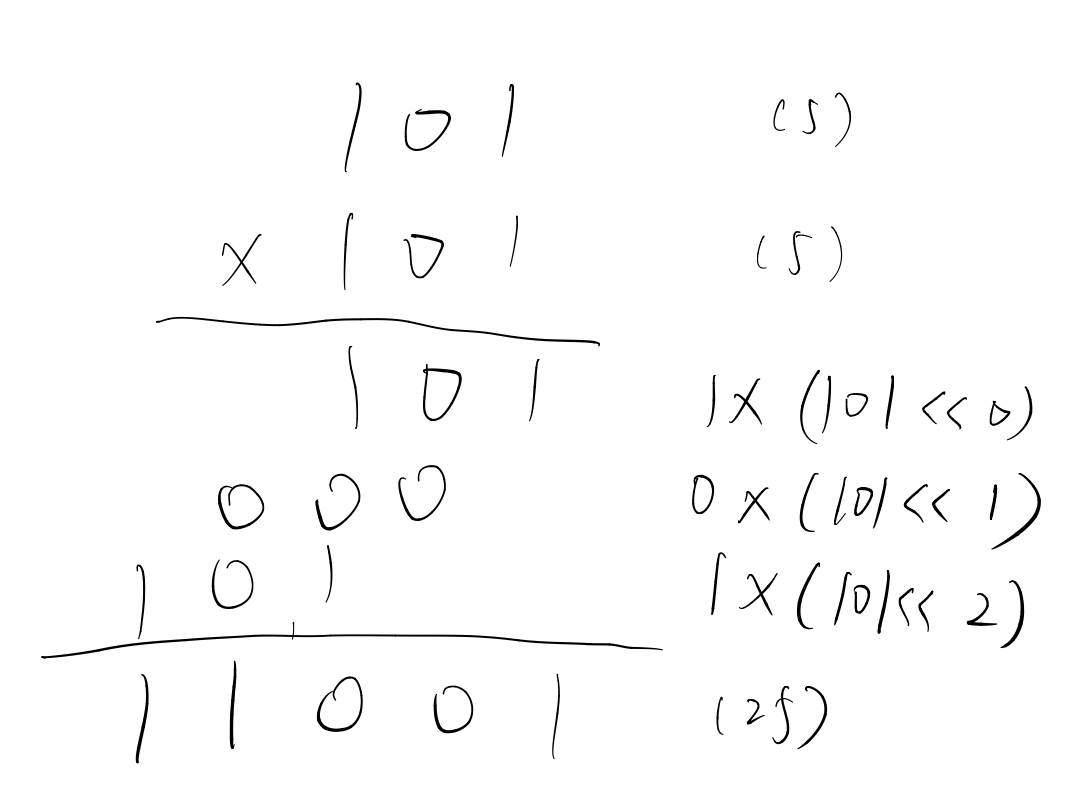
def Pow(x): f = x ans = 0 for i = 1 to n: if x[i] == 1: Addition(ans, f) Shift(f, 1) return ans
在第一题的基础上,第二题其实也不难做了。考虑一下,如果是普通的十进制数,可以用二分搜索的方式——找到一个Pow(k) == N的数就行了。同样的,在这里也可以用二分搜索。但是要注意的是,不能混淆了N和n——n是位数,N的最大大小其实是2n。
