

数据采集与融合技术实验课程作业二
数据采集与融合技术实验课程作业二
目录
作业内容
作业①:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
作业②:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
作业③:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中。
作业①:
主要代码
# 定义获取天气数据的函数
def get_weather_data(city_code):
url = f'http://www.weather.com.cn/weather/{city_code}.shtml'
response = requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
weather_data = []
forecast = soup.find('ul', class_='t clearfix')
for li in forecast.find_all('li'):
date = li.find('h1').text
weather = li.find('p', class_='wea').text
temperature = li.find('p', class_='tem').text.strip()
wind = li.find('p', class_='win').find('span')['title']
weather_data.append((date, weather, temperature, wind))
return weather_data
代码运行结果

运行查看DB文件脚本查看天气数据
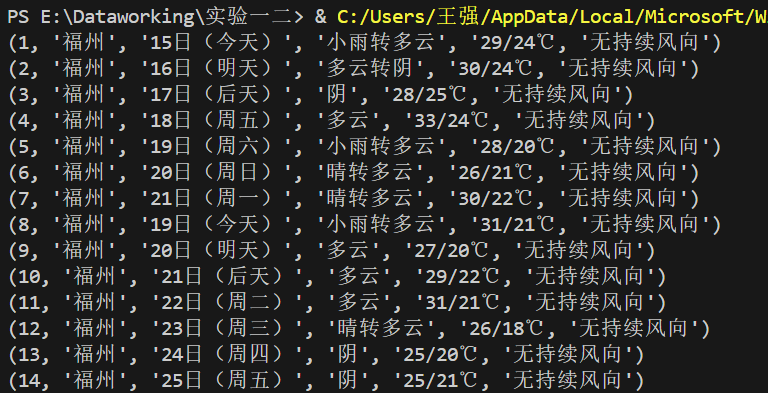
作业心得
- 数据抓取与解析
在这次作业中,我使用了 requests 库来发送 HTTP 请求,并使用 BeautifulSoup 库来解析 HTML 内容。通过解析网页中的天气预报数据,我能够提取出每一天的日期、天气情况、温度和风力信息。 - 数据存储
为了保存抓取到的天气数据,使用了 sqlite3 库来创建和操作 SQLite 数据库。通过建表然后保存所需要的信息。
作业②:
主要代码
# 获取网页内容
def get_html(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36'
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status() # 确保请求成功
return response.text
except requests.RequestException as e:
print(f"Error fetching data from {url}: {e}")
return ""
# 解析JSON内容,提取股票信息
def parse_page(json_data):
stock_data = []
data = json.loads(json_data)
if 'data' in data and 'diff' in data['data']:
for item in data['data']['diff']:
stock_name = item['f14']
stock_price = item['f2']
stock_change = item['f3']
stock_data.append((stock_name, stock_price, stock_change))
return stock_data
代码运行结果

运行查看DB文件脚本查看股票数据
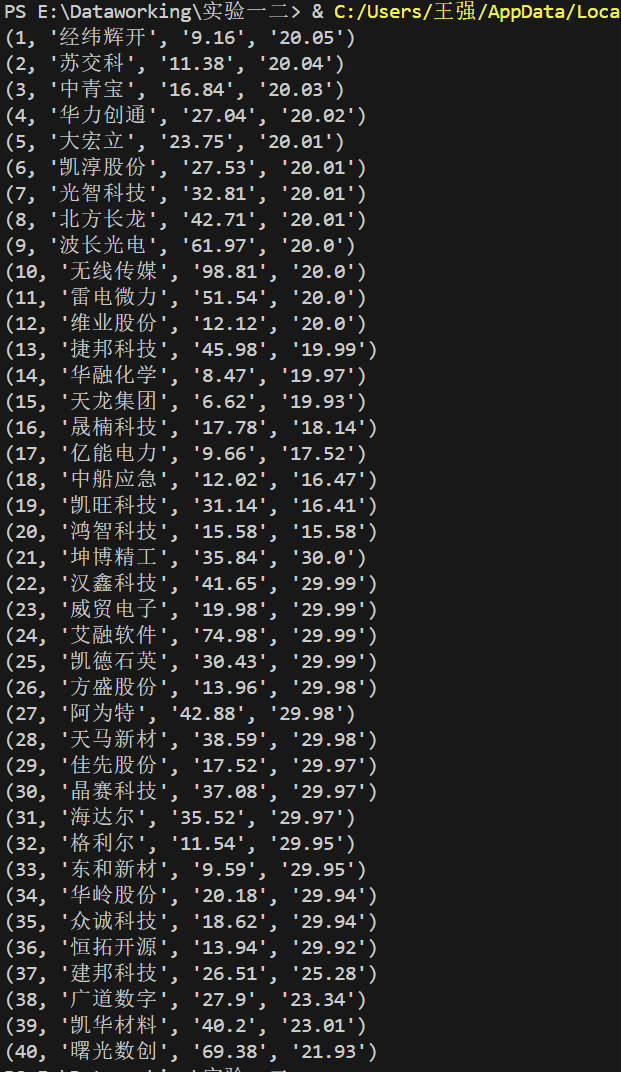
作业心得
- F12调试分析
通过网页调试分析抓取需要的信息部分,提取其URL信息,我通过F12调试分析后抓取了包含股票信息的URL信息。 - 数据抓取与解析
在这次作业中,我使用了 requests 库来发送 HTTP 请求,并使用 BeautifulSoup 库来解析 HTML 内容。 - 数据存储
为了保存抓取到的股票数据,使用了 sqlite3 库来创建和操作 SQLite 数据库。通过建表然后保存所需要的信息。
作业③:
主要代码
# 定义获取院校数据
def get_university_data():
url = 'https://www.shanghairanking.cn/rankings/bcur/2021'
response = requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
university_data = []
# 查找包含院校信息的表格
table = soup.find('table')
for row in table.find_all('tr')[1:]:
cols = row.find_all('td')
if len(cols) > 1:
rank = cols[0].text.strip()
name = cols[1].text.strip()
province = cols[2].text.strip()
total_score = cols[3].text.strip()
university_data.append((rank, name, province, total_score))
return university_data
F12调试过程
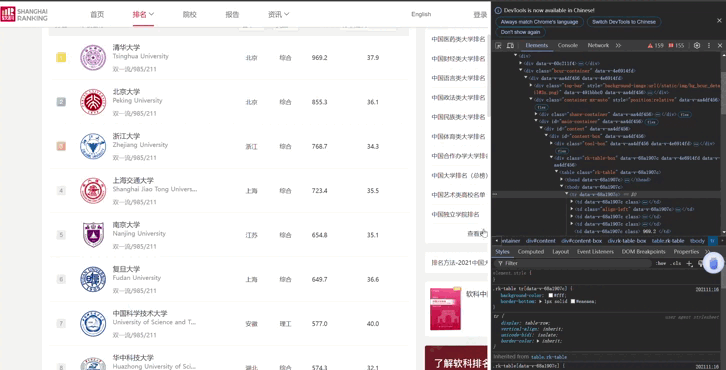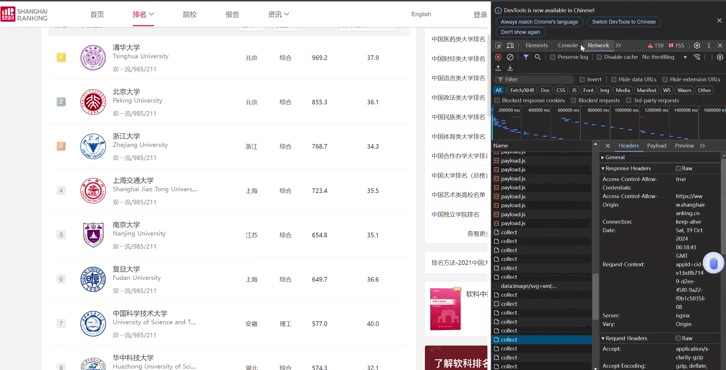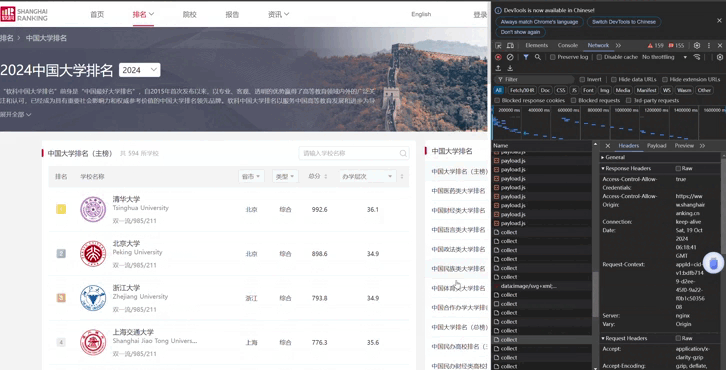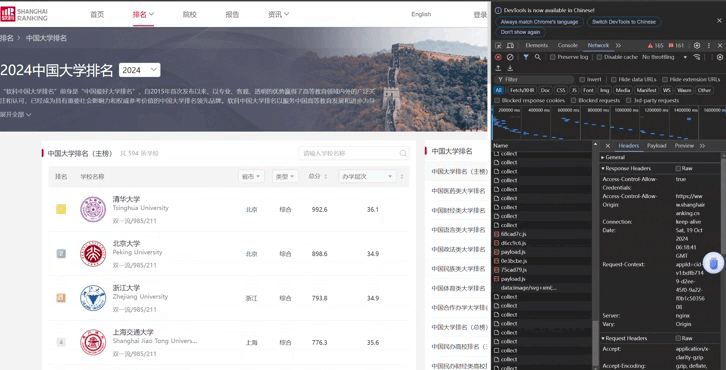
代码运行结果

运行查看DB文件脚本查看股票数据
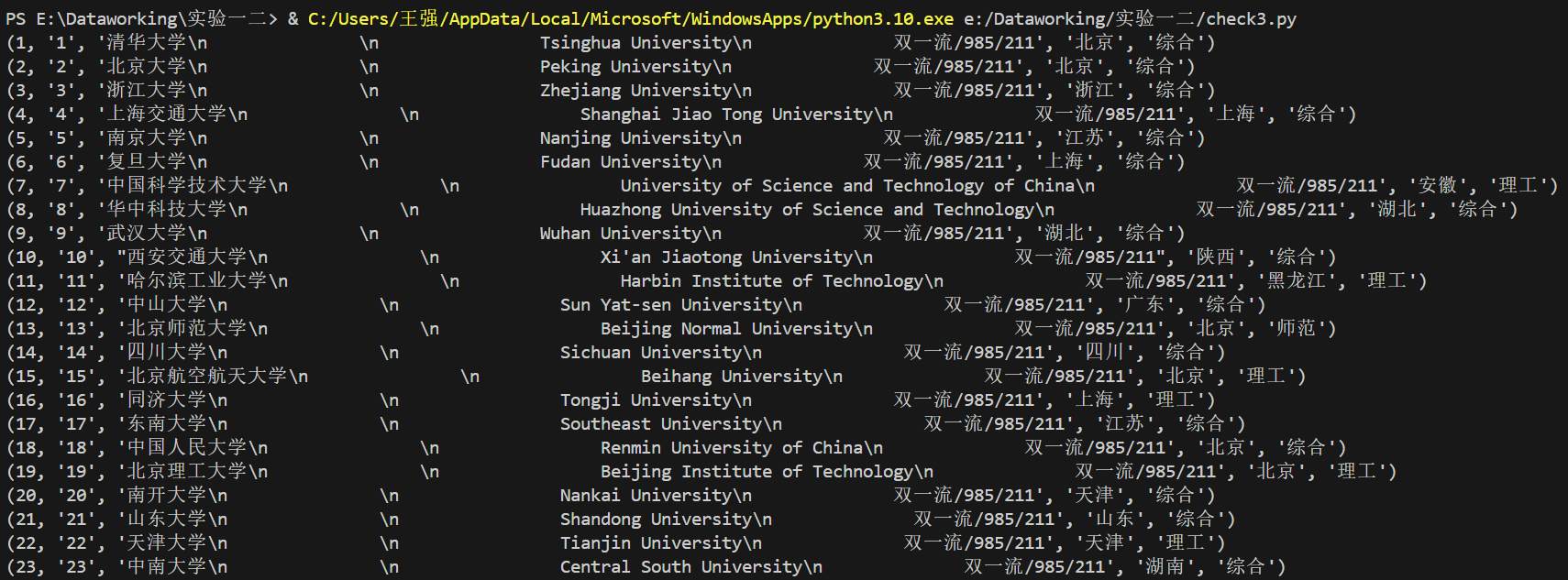
作业心得
- F12调试分析
通过网页调试分析抓取需要的信息部分,提取其URL信息,我通过F12调试分析后抓取了包含大学信息的URL信息。 - 数据抓取与解析
在这次作业中,我使用了 requests 库来发送 HTTP 请求,并使用 BeautifulSoup 库来解析 HTML 内容。 - 数据存储
为了保存抓取到的股票数据,使用了 sqlite3 库来创建和操作 SQLite 数据库。通过建表然后保存所需要的信息。

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步