C++面向对象基础--内存分区模型
C++程序在执行时,将内存大方向划分为4个区域:
代码区:存放函数体的二进制代码,由操作系统进行管理的
全局区:存放全局变量和静态变量以及常量
栈区:由编译器自动分配释放, 存放函数的参数值,局部变量等
堆区:由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收
内存四区意义:不同区域存放的数据,赋予不同的生命周期, 给我们更大的灵活编程空间
1.程序运行前
在程序编译后,生成了exe可执行程序,未执行该程序前分为两个区域
代码区:
(1)存放 CPU 执行的机器指令
(2)代码区是共享的,共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可
(3)代码区是只读的,使其只读的原因是防止程序意外地修改了它的指令
全局区:
(1)全局变量和静态变量存放在此.
(2)全局区还包含了常量区, 字符串常量和其他常量也存放在此.
(3)该区域的数据在程序结束后由操作系统释放
代码示例:
运行结果:
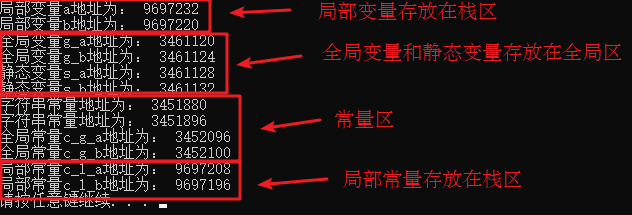
总结:
C++中在程序运行前分为全局区和代码区
代码区特点是共享和只读
全局区中存放全局变量、静态变量、常量
常量区中存放 const修饰的全局常量 和 字符串常量
2.程序运行后
栈区:
由编译器自动分配释放, 存放函数的参数值,局部变量等
注意事项:不要返回局部变量的地址,栈区开辟的数据由编译器自动释放
代码示例:
堆区:
由程序员分配释放,若程序员不释放,程序结束时由操作系统回收
在C++中主要利用new在堆区开辟内存
代码示例:
总结:
堆区数据由程序员管理开辟和释放
堆区数据利用new关键字进行开辟内存(C语言中用malloc() 函数,在C++中尽量不要使用)
补充:也有的资料显示一共有5个区:
(1)栈区(stack):由编译器自动分配释放,在不需要的时候自动清除。用于存放函数的参数、局部变量等。操作方式类似数据结构中的栈(后进先出)。
(2)堆区(heap):一般由程序员分配释放,若程序员分配后不释放,程序结束后可能由OS(操作系统)回收。不同于数据结构中的堆,分配方式有些类似链表。
(3)全局区(静态区):全局变量和静态变量存储在这里。程序结束后由系统释放。在以前的C语言中,全局变量又细分为初始化的(DATA段)和未初始化到(BSS段),在C++里已经没有这个区分了,它们共同占用同一块内存区。
(4)常量存储区:常量字符串就存放在这里。一般不允许修改。程序结束后由系统释放。
(5)代码区:存放函数体的二进制代码。
__EOF__

本文链接:https://www.cnblogs.com/KaguraSakura/p/13338807.html
关于博主:hello~好久不见,喜欢的话点个赞吧
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现