
个人项目——论文查重
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/homework/13229 |
| 这个作业的目标 | 个人项目——论文查重 |
一:我的github仓库地址
https://github.com/kelin-KL/kelin-KL
二:PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 180 | 250 |
| · Estimate | · 估计这个任务需要多少时间 | 200 | 340 |
| Development | 开发 | 230 | 300 |
| · Analysis | · 需求分析 (包括学习新技术) | 50 | 70 |
| · Design Spec | · 生成设计文档 | 30 | 80 |
| · Design Review | · 设计复审 | 30 | 65 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 120 | 170 |
| · Coding | · 具体编码 | 120 | 280 |
| · Code Review | · 代码复审 | 50 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 70 |
| Reporting | 报告 | 80 | 200 |
| · Test Repor | · 测试报告 | 80 | 120 |
| · Size Measurement | · 计算工作量 | 60 | 70 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 70 |
| · 合计 | 1300 | 1945 |
三:模块设计及其接口文档
基本功能及其实现方法
该代码实现了一个基于文本相似度的查重功能,专门用于比较两篇中文文本的相似度,并将相似度结果输出到指定文件中。核心的实现思路是利用文本分词和余弦相似度算法来评估文本间的相似性。
代码组成
-
init:类的构造函数。用于初始化类变量,包括保存原始文本和待查重文本的内容及其分词结果。初始化后,类的实例会拥有两个主要属性:original_text 和 compare_text,以及它们的关键词列表 original_list 和 compare_list。
-
read_file:该函数负责读取文本文件的内容。具体而言,它从指定的文件路径读取原始文本和待查重文本,并将其分别存储在 original_text 和 compare_text 中。读取完成后,文本内容会保存在类的实例变量中,供后续处理使用。
-
long_text_preprocess:此函数负责对文本进行预处理。预处理包括去除文本中的标点符号,以保证分词的准确性。随后,使用 jieba.analyse.extract_tags 方法提取每篇文本中的前20个关键词,这些关键词将存储在 original_list 和 compare_list 中,作为后续相似度计算的基础。
-
text_checking:核心的查重函数。该函数首先调用 read_file 方法读取文本文件,然后调用 long_text_preprocess 方法对文本进行预处理。接着,构建两个文本的词频向量,并计算它们之间的余弦相似度。最终,将计算得到的相似度结果输出到指定的文件中,以便于进一步分析和记录。
核心算法
-
文本预处理:去除文本中的标点符号,并使用 jieba.analyse.extract_tags 提取关键词。关键词的提取数量设置为20个,这些关键词代表了文本的主要内容。
-
构建词频向量:将提取的关键词转换为词频向量,以便于进行数学计算。词频向量是对文本中关键词出现频率的数值化表示。
-
计算余弦相似度:使用余弦相似度算法来计算两个词频向量的相似度。余弦相似度度量的是两个向量在多维空间中夹角的余弦值,从而衡量它们的相似性。值越接近1,表示文本越相似。
流程图如下:

四:性能分析
使用内置profile来进行性能分析
性能分析图
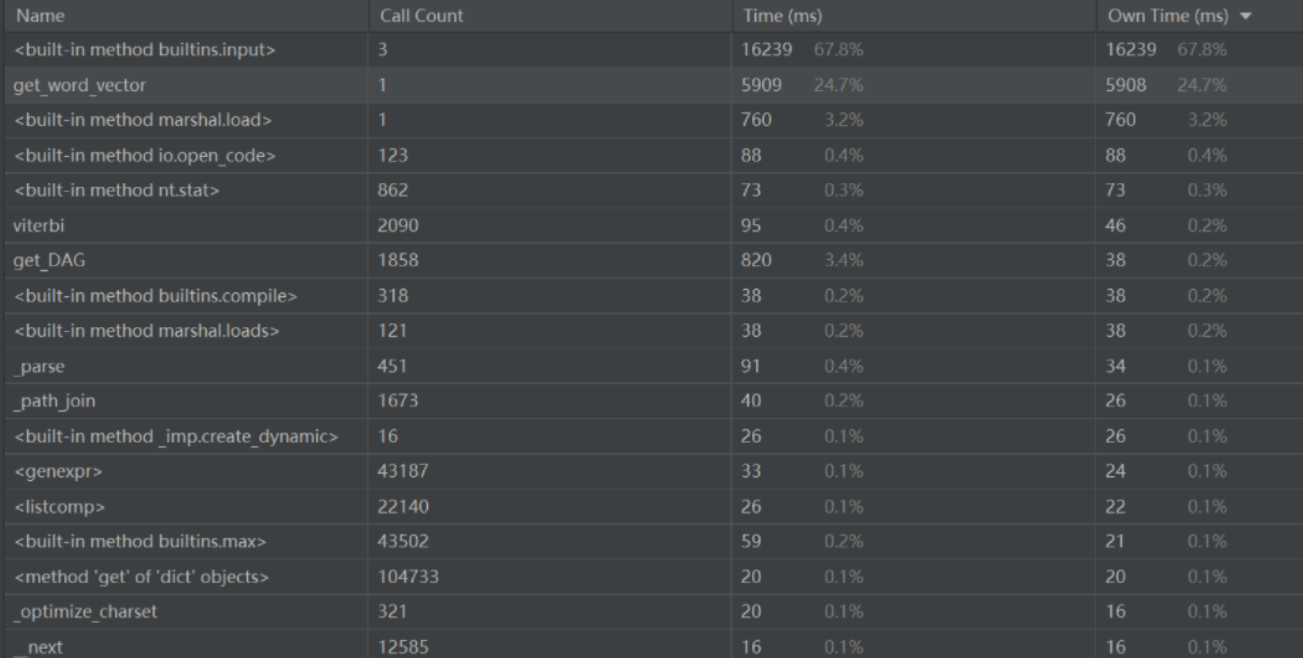
性能消耗较大部分
- 重复计算词频向量
for word in self.word_store:
original_vector.append(self.original_list.count(word))
compare_vector.append(self.compare_list.count(word))
- 频繁的 I/O 操作
with open(duplicate_data_address, "a", encoding="utf-8") as file:
file.write(f"待查文本与原文本的相似度为:{round(cos_sim, 2)}\n")
性能优化思路
- 优化词频向量计算
- 优化文件操作
优化后
#计算文本相似度
def text_checking(self):
original_vector = []
compare_vector = []
# 读取文件,检查读取是否成功
# 调用 `read_file` 方法读取原始文本和比较文本
if not self.read_file():
return False
# 根据文本长度判断选择预处理方法
# 如果原始文本或比较文本的长度超过1000字符,则视为长文本
if len(self.original_text) > 1000 or len(self.compare_text) > 1000:
self.long_text_preprocess()
else:
self.short_text_preprocess()
# 合并分词列表并去重,创建词汇表
# 使用 `set` 去除重复的词汇,`self.word_store` 存储所有不重复的词汇
self.word_store = list(set(self.original_list + self.compare_list))
# 构建词频向量
# 对每个词汇,计算它在 `original_list` 和 `compare_list` 中出现的频次
for word in self.word_store:
original_vector.append(self.original_list.count(word))
compare_vector.append(self.compare_list.count(word))
# 将词频向量转换为 numpy 数组
original_vector = numpy.array(original_vector)
compare_vector = numpy.array(compare_vector)
# 使用 scipy 库的余弦相似度函数计算相似度
# `spatial.distance.cosine` 计算两个向量之间的余弦距离,余弦相似度为 1 减去余弦距离
cos_sim = 1 - spatial.distance.cosine(original_vector, compare_vector)
# 将相似度写入文件并提示用户
# 获取用户输入的文件路径并尝试打开文件
duplicate_data_address = input("查重结果文件输出的地址:")
try:
# 使用追加模式打开文件,若文件不存在则创建
with open(duplicate_data_address, "a", encoding="utf-8") as file:
# 将相似度写入文件
file.write(f"待查文本与原文本的相似度为:{round(cos_sim, 2)}\n")
print("查重结果已输出到文件!")
except IOError:
# 捕捉文件打开或写入失败的异常
print("查重结果文件创建失败,请检查路径并重试。")
return True
五:单元测试模块
单元测试将利用 PyCharm 提供的 unittest 框架进行。测试通过继承 unittest.TestCase 类来创建测试类,并在其中定义测试函数。运行测试时,将执行测试 Python 文件,从而对主程序进行测试。
在测试项目的输入模块时,将使用 unittest 框架中的 patch 类来模拟用户输入,以此实现对输入模块的测试。测试过程包括模拟用户操作以及对 main.py 中 DuplicateChecking 类的每个方法进行单独测试。通过使用框架中的 assertEqual() 函数,验证类及其方法的行为是否符合预期
import unittest
import random
from main import DuplicateChecking
from unittest.mock import patch # 用于模拟输入
# 记录测试文本地址
original_text = [r'C:\Users\86150\Desktop\查重测试样例\orig.txt',
r'C:\Users\86150\Desktop\查重测试样例\原文1.txt',
r'C:\Users\86150\Desktop\查重测试样例\原文2.txt',
r'C:\Users\86150\Desktop\查重测试样例\原文3.txt',
r'C:\Users\86150\Desktop\查重测试样例\原文4.txt']
test_text = [r'C:\Users\86150\Desktop\查重测试样例\orig_0.8_add.txt',
r'C:\Users\86150\Desktop\查重测试样例\orig_0.8_del.txt',
r'C:\Users\86150\Desktop\查重测试样例\orig_0.8_dis_1.txt',
r'C:\Users\86150\Desktop\查重测试样例\orig_0.8_dis_10.txt',
r'C:\Users\86150\Desktop\查重测试样例\orig_0.8_dis_15.txt',
r'C:\Users\86150\Desktop\查重测试样例\抄袭1.txt',
r'C:\Users\86150\Desktop\查重测试样例\抄袭2.txt',
r'C:\Users\86150\Desktop\查重测试样例\抄袭3.txt',
r'C:\Users\86150\Desktop\查重测试样例\抄袭4.txt']
class MyTestCase(unittest.TestCase):
@patch('builtins.input')
def test_IO(self, mock_input):
"""
测试输入和文件读取功能的正确性。
使用 mock_input 来模拟用户输入。
- 第一个测试用例模拟正确的输入,检查 `read_file` 方法是否返回 True。
- 第二个测试用例模拟错误的输入,检查 `read_file` 方法是否返回 False。
"""
result = DuplicateChecking() # 实例化 DuplicateChecking 类对象
mock_input.side_effect = [original_text[0], test_text[random.randint(0, 4)]] # 模拟正确的用户输入
self.assertEqual(result.read_file(), True) # 断言 read_file 方法返回 True 表示文件读取成功
# 模拟错误的用户输入
mock_input.side_effect = [original_text[random.randint(1, 4)], test_text[random.randint(5, 8)]]
self.assertEqual(result.read_file(), False) # 断言 read_file 方法返回 False 表示文件读取失败
@patch('builtins.input')
def test_long_text_preprocess(self, mock_input):
"""
测试长文本预处理功能。
使用 mock_input 来模拟用户输入。
- 模拟正确的输入,检查 `long_text_preprocess` 方法是否返回 True。
"""
result = DuplicateChecking() # 实例化 DuplicateChecking 类对象
mock_input.side_effect = [original_text[0], test_text[random.randint(0, 4)]] # 模拟正确的用户输入
result.read_file() # 先读取文件
self.assertEqual(result.long_text_preprocess(), True) # 断言 long_text_preprocess 方法返回 True 表示预处理成功
def test_short_text_preprocess(self):
"""
测试短文本预处理功能。
- 设置短文本数据,检查 `short_text_preprocess` 方法是否返回 True。
"""
result = DuplicateChecking() # 实例化 DuplicateChecking 类对象
result.original_text = "original" # 设置原始文本
result.compare_text = "compare" # 设置比较文本
self.assertEqual(result.short_text_preprocess(), True) # 断言 short_text_preprocess 方法返回 True 表示预处理成功
@patch('builtins.input')
def test_text_checking(self, mock_input):
"""
测试文本相似度检查功能。
使用 mock_input 来模拟用户输入。
- 第一个测试用例模拟正确的输入,检查 `text_checking` 方法是否返回 True。
- 第二个测试用例模拟错误的输入,检查 `text_checking` 方法是否返回 False。
"""
result = DuplicateChecking() # 实例化 DuplicateChecking 类对象
mock_input.side_effect = [original_text[0], test_text[random.randint(0, 4)],
r'C:\Users\86150\Desktop\查重测试样例\结果记录.txt'] # 模拟正确的用户输入,包括文件路径
self.assertEqual(result.text_checking(), True) # 断言 text_checking 方法返回 True 表示检查成功
# 模拟错误的用户输入
mock_input.side_effect = [original_text[random.randint(1, 4)], test_text[random.randint(5, 8)],
r'C:\Users\86150\Desktop\查重测试样例\结果记录.txt']
self.assertEqual(result.text_checking(), False) # 断言 text_checking 方法返回 False 表示检查失败
if __name__ == '__main__':
unittest.main() # 运行所有测试用例
六:异常处理
- 读取文件异常
# 读取原始文本文件
try:
with open(original_text_address, "r", encoding="utf-8") as file1:
self.original_list = file1.readlines()
# 将读取的行拼接成单个字符串存储
self.original_text = self.original_text.join(self.original_list)
except FileNotFoundError:
# 如果文件未找到,提示用户并重置文件路径
print("未找到原始文本文件 " + original_text_address + " 请重试")
original_text_address = ""
# 读取抄袭文本文件
try:
with open(copy_text_address, "r", encoding="utf-8") as file2:
self.compare_list = file2.readlines()
self.compare_text = self.compare_text.join(self.compare_list)
except FileNotFoundError:
# 如果文件未找到,提示用户并重置文件路径
print("未找到抄袭文件 " + copy_text_address + " 请重试")
copy_text_address = ""
# 如果文件不存在,重置文本内容并返回 False
if original_text_address == "" or copy_text_address == "":
self.original_text = ""
self.compare_text = ""
self.compare_list = []
self.original_list = []
return False
return True
- 输出文件异常
try:
# 使用追加模式打开文件,若文件不存在则创建
with open(duplicate_data_address, "a", encoding="utf-8") as file:
# 将相似度写入文件
file.write(f"待查文本与原文本的相似度为:{round(cos_sim, 2)}\n")
print("查重结果已输出到文件!")
except IOError:
# 捕捉文件打开或写入失败的异常
print("查重结果文件创建失败,请检查路径并重试。")
return True
七:心得体会
通过本项目的实践,我不仅加深了对文本处理和相似度计算等基础技术的理解,还在单元测试和性能优化方面积累了宝贵的经验。在文本处理方面,我学会了如何高效地进行数据预处理和分析,掌握了各种相似度计算方法的实际应用。在单元测试方面,通过使用 unittest 框架及其相关工具,我提高了对代码质量的把控能力,确保了程序的稳定性和可靠性。在性能优化方面,我探索了提升代码执行效率的方法,如改进算法和减少不必要的计算。这些经验不仅增强了我解决实际问题的能力,还为未来参与更复杂的项目打下了坚实的基础,使我能够更自信地应对各种技术挑战。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号