
学习Python--Day5--文件操作
知识点
文件操作:读
r模式
以只读方式打开文件,文件的指针将会放在文件的开头。是文件操作最常用的模式,也是默认模式,如果一个文件不设置mode,那么默认使用r模式操作文件。
-
read()
read()将文件中的内容全部读取出来;弊端 如果文件很大就会非常的占用内存,容易导致内存奔溃. -
read(n)
read()读取的时候指定读取到什么位置
在r模式下,n按照字符读取。
-
readline()
readline()读取每次只读取一行,注意点:readline()读取出来的数据在后面都有一个\n
解决这个问题只需要在我们读取出来的文件后边加一个strip()就OK了
-
readlines()
readlines() 返回一个列表,列表里面每个元素是原文件的每一行,如果文件很大,占内存,容易崩盘。
上面这四种都不太好,因为如果文件较大,他们很容易撑爆内存,所以接下来我们看一下第五种:
-
for循环
可以通过for循环去读取,文件句柄是一个迭代器,他的特点就是每次循环只在内存中占一行的数据,非常节省内存。
f = open('../path1/弟子规',mode='r',encoding='utf-8')
for line in f:
print(line) #这种方式就是在一行一行的进行读取,它就执行了下边的功能
print(f.readline())
print(f.readline())
print(f.readline())
print(f.readline())
f.close()
注意点:读完的文件句柄一定要关闭
rb模式
rb模式:以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。记住下面讲的也是一样,带b的都是以二进制的格式操作文件,他们主要是操作非文字文件:图片,音频,视频等,并且如果你要是带有b的模式操作文件,那么不用声明编码方式。
当然rb模式也有read read(n) readline(),readlines() for循环这几种方法。
文件操作:写
第二类就是写,就是在文件中写入内容。这里也有四种文件分类主要四种模式:w,wb,w+,w+b,我们只讲w,wb。
w模式
如果文件不存在,利用w模式操作文件,那么它会先创建文件,然后写入内容.
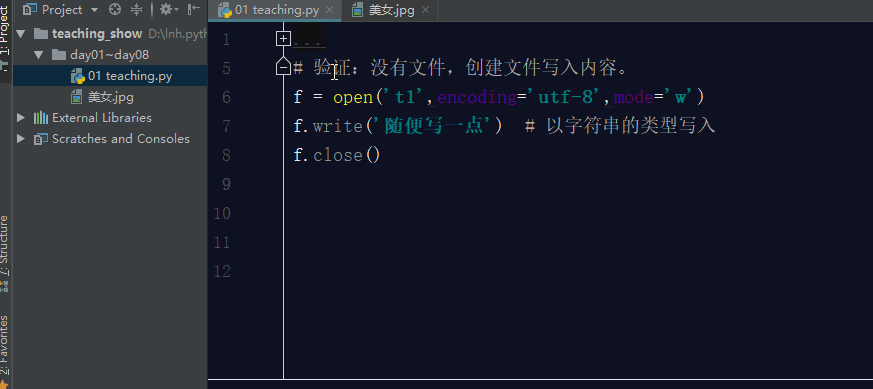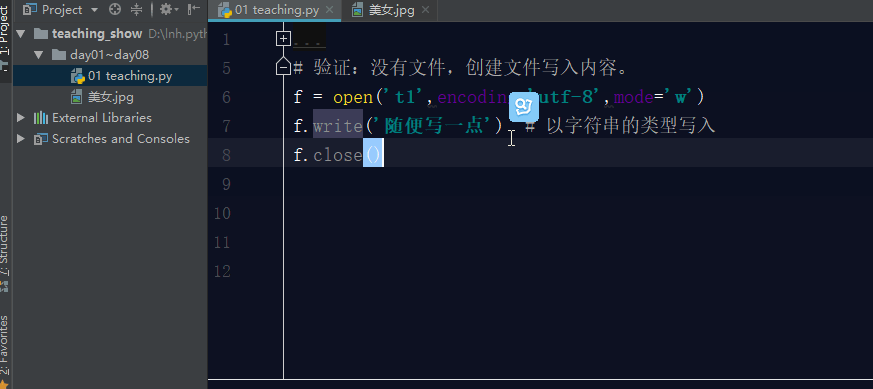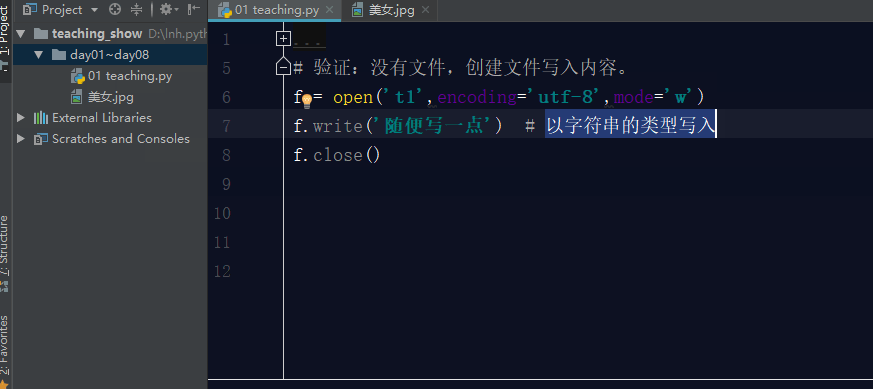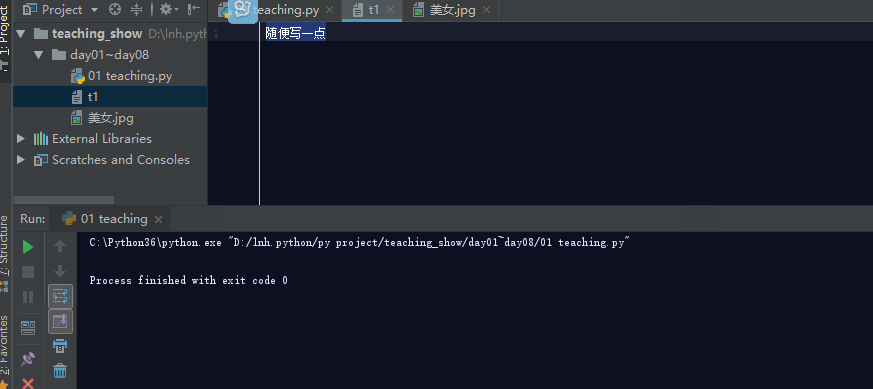
如果文件存在,利用w模式操作文件,先清空原文件内容,在写入新内容。
wb模式
wb模式:以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如:图片,音频,视频等。
举例说明:
以rb的模式将一个图片的内容以bytes类型全部读取出来,然后在以wb将全部读取出来的数据写入一个新文件,这样我就完成了类似于一个图片复制的流程。具体代码如下:

文件操作:追加
第三类就是追加,就是在文件中追加内容。这里也有四种文件分类主要四种模式:a,ab,a+,a+b,只讲a。
a模式
打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
如果文件不存在,利用a模式操作文件,那么它会先创建文件,然后写入内容。
如果文件存在,利用a模式操作文件,那么它会在文件的最后面追加内容。
文件操作的其他模式
带+号的模式。什么是带+的模式呢?+就是加一个功能。比如r模式是只读模式,在这种模式下,文件句柄只能进行类似于read的这读的操作,而不能进行write这种写的操作。所以想让这个文件句柄既可以进行读的操作,又可以进行写的操作,那么这个如何做呢?这就是接下来要说这样的模式:r+ 读写模式,w+写读模式,a+写读模式,r+b 以bytes类型的读写模式.........
在这里只讲一种就是r+,其他的大同小异,自己可以练练就行了。
#1. 打开文件的模式有(默认为文本模式):
r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】
w,只写模式【不可读;不存在则创建;存在则清空内容】
a, 只追加写模式【不可读;不存在则创建;存在则只追加内容】
#2. 对于非文本文件,我们只能使用b模式,"b"表示以字节的方式操作(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jgp格式、视频文件的avi格式)
rb
wb
ab
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
#3,‘+’模式(就是增加了一个功能)
r+, 读写【可读,可写】
w+,写读【可写,可读】
a+, 写读【可写,可读】
#4,以bytes类型操作的读写,写读,写读模式
r+b, 读写【可读,可写】
w+b,写读【可写,可读】
a+b, 写读【可写,可读】
r+模式
r+: 打开一个文件用于读写。文件指针默认将会放在文件的开头。

注意:如果你在读写模式下,先写后读,那么文件就会出问题,因为默认光标是在文件的最开始,你要是先写,则写入的内容会讲原内容覆盖掉,直到覆盖到你写完的内容,然后在后面开始读取。
文件操作的其他功能
read(n)
1. 文件打开方式为文本模式时,代表读取n个字符
2. 文件打开方式为b模式时,代表读取n个字节
seek()
seek(n)光标移动到n位置,注意: 移动单位是byte,所有如果是utf-8的中文部分要是3的倍数
通常我们使用seek都是移动到开头或者结尾
移动到开头:seek(0)
移动到结尾:seek(0,2) seek的第二个参数表示的是从哪个位置进行偏移,默认是0,表示开头,1表示当前位置,2表示结尾
f = open("小娃娃", mode="r+", encoding="utf-8")
f.seek(0) # 光标移动到开头
content = f.read() # 读取内容, 此时光标移动到结尾
print(content)
f.seek(0) # 再次将光标移动到开头
f.seek(0, 2) # 将光标移动到结尾
content2 = f.read() # 读取内容. 什么都没有
print(content2)
f.seek(0) # 移动到开头
f.write("张国荣") # 写入信息. 此时光标在9 中文3 * 3个 = 9
f.flush()
f.close() [](javascript:void(0);)
tell()
使用tell()可以帮我们获取当前光标在什么位置
f = open("小娃娃", mode="r+", encoding="utf-8")
f.seek(0) # 光标移动到开头
content = f.read() # 读取内容, 此时光标移动到结尾
print(content)
f.seek(0) # 再次将光标移动到开头
f.seek(0, 2) # 将光标移动到结尾
content2 = f.read() # 读取内容. 什么都没有
print(content2)
f.seek(0) # 移动到开头
f.write("张国荣") # 写入信息. 此时光标在9 中⽂文3 * 3个 = 9
print(f.tell()) # 光标位置9
f.flush()
f.close()
readable(),writeable()
f = open('Test',encoding='utf-8',mode='r')
print(f.readable()) # True
print(f.writable()) # False
content = f.read()
f.close()
打开文件的另一种方式
打开文件都是通过open去打开一个文件,其实Python也提供了另一种方式:with open() as .... 的形式,那么这种形式有什么好处呢?
# 1,利用with上下文管理这种方式,它会自动关闭文件句柄。
with open('t1',encoding='utf-8') as f1:
f1.read()
# 2,一个with 语句可以操作多个文件,产生多个文件句柄。
with open('t1',encoding='utf-8') as f1,\
open('Test', encoding='utf-8', mode = 'w') as f2:
f1.read()
f2.write('a_tong')
这里要注意一个问题,虽然使用with语句方式打开文件,不用你手动关闭文件句柄,比较省事儿,但是依靠其自动关闭文件句柄,是有一段时间的,这个时间不固定,所以这里就会产生问题,如果你在with语句中通过r模式打开t1文件,那么你在下面又以a模式打开t1文件,此时有可能你第二次打开t1文件时,第一次的文件句柄还没有关闭掉,可能就会出现错误,他的解决方式只能在你第二次打开此文件前,手动关闭上一个文件句柄。
文件的修改
文件的数据是存放于硬盘上的,因而只存在覆盖、不存在修改这么一说,我们平时看到的修改文件,都是模拟出来的效果,具体的说有两种实现方式:
方式一:将硬盘存放的该文件的内容全部加载到内存,在内存中是可以修改的,修改完毕后,再由内存覆盖到硬盘(word,vim,nodpad++等编辑器)
import os # 调用系统模块
with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f:
data=read_f.read() #全部读入内存,如果文件很大,会很卡
data=data.replace('alex','SB') #在内存中完成修改
write_f.write(data) #一次性写入新文件
os.remove('a.txt') #删除原文件
os.rename('.a.txt.swap','a.txt') #将新建的文件重命名为原文件
方式二:将硬盘存放的该文件的内容一行一行地读入内存,修改完毕就写入新文件,最后用新文件覆盖源文件
import os
with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f:
for line in read_f:
line=line.replace('alex','SB')
write_f.write(line)
os.remove('a.txt')
os.rename('.a.txt.swap','a.txt')
初识函数
函数的优势:
1,减少代码的重复性。
2,使代码可读性更好。
函数的结构与调用
函数的结构
首先咱们先看一下函数的结构:
def 函数名():
函数体
def 关键词开头,空格之后接函数名称和圆括号(),最后还有一个":"。
def 是固定的,不能变,他就是定义函数的关键字。
空格 为了将def关键字和函数名分开,必须空(四声),当然你可以空2格、3格或者你想空多少都行,但正常人还是空1格。
函数名:函数名只能包含字符串、下划线和数字且不能以数字开头。虽然函数名可以随便起,但我们给函数起名字还是要尽量简短,并且要具有可描述性
括号:是必须加的,先别问为啥要有括号,总之加上括号就对了(下面就会讲到)!
函数的调用
使用函数名加小括号就可以调用了 写法:函数名() 这个时候函数的函数体会被执行
只有解释器读到函数名() 时,才会执行此函数,如果没有这条指令,函数里面即使有10万行代码也是不执行的。
而且是这个指令你写几次,函数里面的代码就运行几次,就好比你在部队,我喊你名字,喊几次,你就得 到 几次,这就是指令。
怎么来描述和获得呢? 这就涉及到函数的返回值。
函数的返回值
一个函数就是封装一个功能,这个功能一般都会有一个最终结果的,比如你写一个登录函数,最终登录成功与否是不是需要返回你一个结果?还有咱们是不是都用过len这个函数,他是获取一个对象的元素的总个数,最终肯定会返回一个元素个数这样的结果:
s1 = 'abfdas'
print(len(s1)) # 6
那么这个返回值如何设置呢?这就得用到python中的一个关键字:return
函数中遇到return,此函数结束。
不在继续执行那么函数的返回值,既然叫做返回值,他就是返回一些数据,那么返回给谁呢?
跟我们之前使用的len一样,函数的返回值返回给了 函数名() 这个整体,也就是这个执行者。
return 会给函数的执行者返回值。
当然,也可以返回多个值。
如果返回多个值,是以元组的形式返回的。
总结一下:
1.遇到return,函数结束,return下面的(函数内)的代码不会执行。
2.return 会给函数的执行者返回值。
-
如果return后面什么都不写,或者函数中没有return,则返回的结果是None
-
如果return后面写了一个值,返回给调用者这个值
-
如果return后面写了多个结果,,返回给调用者一个tuple(元组),调用者可以直接使用元组的解构获取多个变量。
def date():
return 'KK','丶', 'A_Tong'
g1,g2,g3 = date()
print(g1, g2, g3) # KK 丶 A_Tong
函数的参数
我们上面研究了,函数的结构,函数的执行,以及函数的返回值。对函数有一个初步的了解,那么接下来就是一个非常重要的知识点,函数的参数。函数是以功能为导向的,上面我们写的函数里面的代码都是写死的,也就是说,这个函数里面的更改起来很麻烦,试想一下,我们使用探探,陌陌等软件,可不可以进行筛选,比如选择性别,年龄等,导出结果? 再拿我们之前学过的len 这个len是不是可以获取字符串的总个数?是不是可以获取列表的总个数?你更改了len函数内部的代码了?没有吧?你看下面的例子:
s1 = 'sfdas'
l1 = [1, 3, 7]
print(len(s1)) # 5
print(len(l1)) # 3
那么我们写的函数也是可以将一些数据传到函数里面的,然后让里面的代码利用上这个数据产生我们想要的结果,在返回。
函数的参数可以从两个角度划分:
1.形参
- 写在函数声明的位置的变量叫形参,形式上的一个完整.表示这个函数需要xxx
2.实参
- 在函数调用的时候给函数传递的值.加实参,实际执行的时候给函数传递的信息.表示给函数xxx
函数的传参就是函数将实际参数交给形式参数的过程.
实参角度
1, 位置参数
位置参数就是从左至右,实参与形参一一对应。
练习
编写函数,给函数传递两个参数a,b a,b相加 返回a参数和b参数相加的和
def f(a,b):
c = a+b
return c
num_sum = f(5,8)
print(num_sum)
结果: 13
编写函数,给函数传递两个参数a,b 比较a,b的大小 返回a,b中最大的那个数
def f(a,b):
if a>b:
return a
else:
return b
num_sum = f(5,8)
print(num_sum)
结果:8
比较大小的这个写法有点麻烦,我们在这里学一个三元运算符
def f(a,b):
c = a if a > b else b #当a>b就把a赋值给c,否则就把b赋值给c
return c
msg = f(5,7)
print(msg)
结果:
7
2, 关键字参数
位置参数好不好呢? 如果是少量的参数还算OK, 没有问题. 但是如果函数在定义的时候参数非常多怎么办? 程序员必须记住, 我有哪些参数, 而且还有记住每个参数的位置, 否则函数就不能正常调用了. 那则么办呢? python提出了一种叫做关键字参数. 我们不需要记住每个参数的位置. 只要记住每个参数的名字就可以了
3, 混合参数
可以把上面两种参数混合着使用. 也就是说在调用函数的时候即可以给出位置参数, 也可以指定关键字参数.
综上: 在实参的⾓角度来看参数分为三种:
1. 位置参数
2. 关键字参数
3. 混合参数, 位置参数必须在关键字参数前面
形参角度
1, 位置参数
位置参数其实与实参角度的位置参数是一样的,就是按照位置从左至右,一一对应
2, 默认值参数
在函数声明的时候, 就可以给出函数参数的默认值. 默认值参数一般是这个参数使用率较高,才会设置默认值参数,可以看看open函数的源码,mode=‘r’就是默认值参数. 比如, 我们录入咱们班学生的基本信息. 通过调查发现. 我们班大部分学生都是男生. 这个时 候就可以给出⼀一个sex='男'的默认值.
def stu_info(name, age, sex='男'):
print("录入学生信息")
print(name, age, sex)
print("录入完毕")
stu_info("A_Tong", 20)
注意:必须先声明在位置参数,才能声明关键字参数
综上:在形参的角度来看
- 位置参数
- 默认认值参数(大多数传进来的参数都是一样的, 一般用默认参数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号