数据采集与融合第四次个人作业
写在前面
由于电脑内存不太够所以用之前下载好的 SQL SERVER 而不用 MYSQL ,如果使用 MYSQL 需要安装的第三方库是 pymysql,而 SQL SERVER 则是 pymssql,二者使用方法大同小异,现在进入正题。
作业一
-
就先理解一哈源代码,发现还是熟悉的创造 Field ,编写 pipeline 来处理爬取到的数据以及这次新加的使用数据库来存储(很想学emmmm...刚好做后端需要用到)。上一次使用的是 sqlite,但是并没有存到本地的数据库。对于当当这种不把页面进行动态加载的良心商家来说,就可以使用书中提供的方法来实现翻页,否则就要在密密麻麻的 JS 文件中寻找翻页时加载过来的 JS 文件了(不然就得用用 selenium)。
-
先上结果~
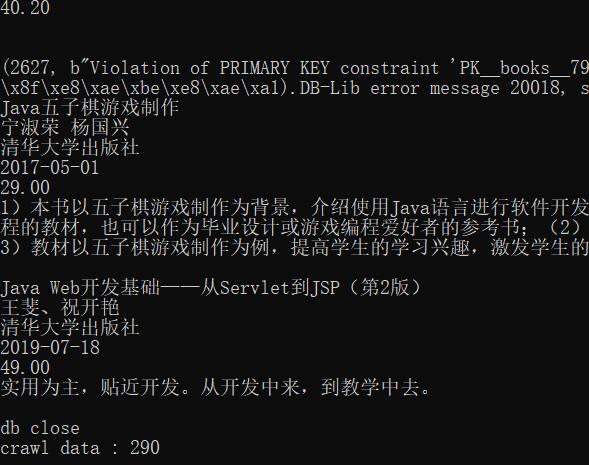
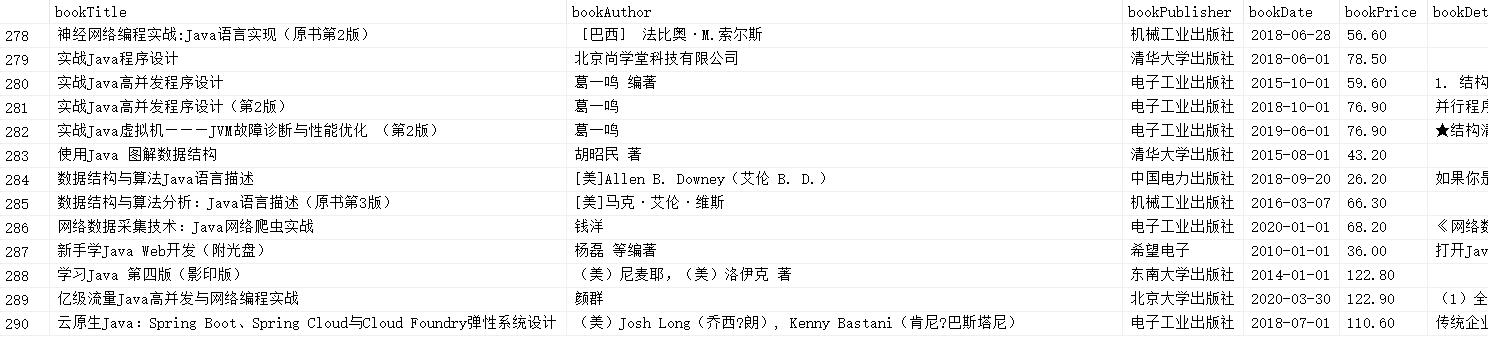
-
爬取说明
为了我以后还能愉快的使用自己的 IP 在当当网买书,我只爬取了5页,一共290条数据,看起来好像还不错! -
源代码
items:
import scrapy
class BookdemoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
author = scrapy.Field()
date = scrapy.Field()
publisher = scrapy.Field()
detail = scrapy.Field()
price = scrapy.Field()
pass
pipeline:
import pymssql
class BookdemoPipeline:
def open_spider(self,spider):
try:
# connect my SQL SERVER but need to open TCP/IP interface (with cmd)
self.conn = pymssql.connect(host="localhost", user="sa", password="******", database="xrfdb")
self.cursor = self.conn.cursor()
self.cursor.execute("delete from books")
self.opened = True
# num of data
self.count = 0
except Exception as e:
print(e)
self.opened = False
def close_spider(self,spider):
if self.opened:
self.conn.commit()
self.conn.close()
self.opened = False
print("db close")
print("crawl data : " + str(self.count))
def process_item(self, item, spider):
try:
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
print()
if self.opened:
self.cursor.execute("insert into books(bookTitle,bookAuthor,bookPublisher,bookDate,bookPrice,bookDetail) values(%s,%s,%s,%s,%s,%s)"
,(item["title"],item["author"],item["publisher"],item["date"],item["price"],item["detail"]))
self.count += 1
except Exception as e:
print(e)
return item
main:
import scrapy
import sys,os
sys.path.append(os.path.dirname(os.path.dirname(__file__)))
from items import BookdemoItem
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
class MySpider(scrapy.Spider):
name = "xrfspider"
teminal = 5
cnt = 1
def start_requests(self):
url = "http://search.dangdang.com/?key=java&act=input"
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response, **kwargs):
try:
dammit = UnicodeDammit(response.body,["utf-8","gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")
for li in lis:
title = li.xpath("./a[position()=1]/@title").extract_first()
price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date = li.xpath("./p[@class='search_book_author']/span[position()=last()-1]/text()").extract_first()
publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
item = BookdemoItem()
item["title"] = title.strip() if title else ""
item["price"] = price.strip()[1:] if price else ""
item["author"] = author.strip() if author else ""
item["date"] = date.strip()[1:] if date else ""
item["publisher"] = publisher.strip() if publisher else ""
item["detail"] = detail.strip() if detail else ""
yield item
link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next']/a/@href").extract_first()
if link and self.cnt != self.teminal:
self.cnt += 1
url = response.urljoin(link)
yield scrapy.Request(url=url,callback=self.parse)
except Exception as e:
print(e)
作业二
-
作业二和作业一的操作是一样滴,只不过作业二翻页变成了万恶的 JS 动态加载,除了 selenium 只能在人海中找那个对的 JS 了...还有就是,这个股票的属性是真的多,SQL 语句好长 QAQ...
-
爬取结果
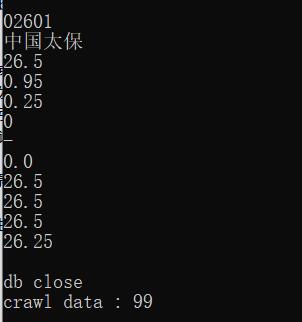
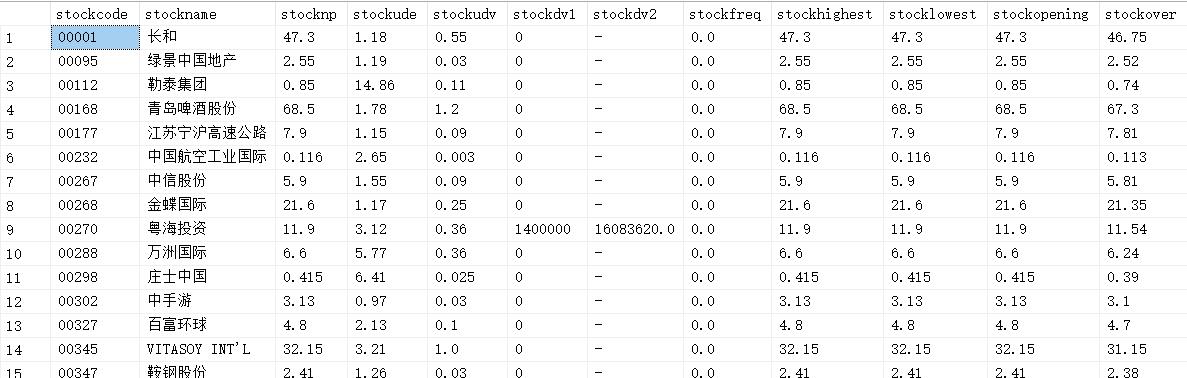
突然发现这个数据是周三早上爬的那时候貌似没有开盘,成交量和成交额都看不到,补一个收盘后的爬取结果
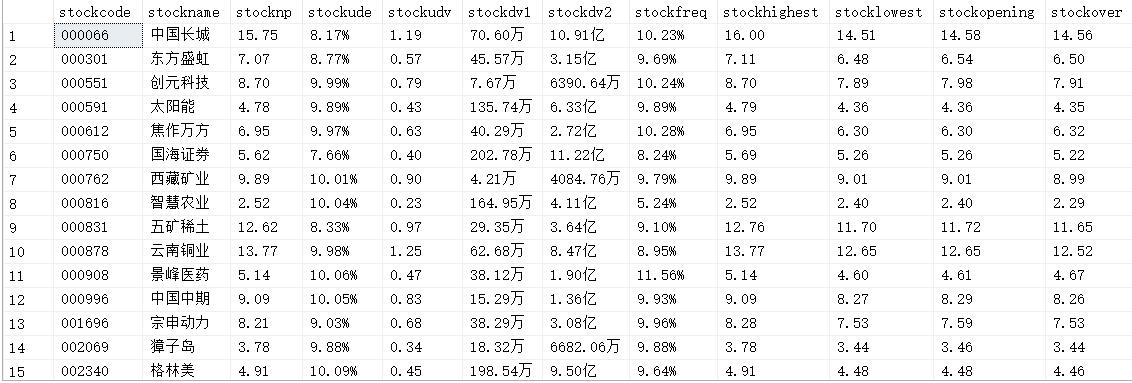
-
爬取说明
还是一样的,为了我以后能愉快的炒股?(这个网站应该不记仇吧但是我也不炒股吧)只爬取了5页,总共爬取了99条数据,还是熟悉的那个结果。 -
源代码
items:
import scrapy
class StockDemoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
code = scrapy.Field()
name = scrapy.Field()
newest_price = scrapy.Field()
up_down_extent = scrapy.Field()
up_down_value = scrapy.Field()
deal_volume = scrapy.Field()
deal_value = scrapy.Field()
freq = scrapy.Field()
highest = scrapy.Field()
lowest = scrapy.Field()
opening = scrapy.Field()
over = scrapy.Field()
pass
pipeline:
from itemadapter import ItemAdapter
import pymssql
class StockDemoPipeline:
def open_spider(self,spider):
try:
self.conn = pymssql.connect(host="localhost", user="sa", password="******", database="xrfdb")
self.cursor = self.conn.cursor()
self.cursor.execute("delete from stocks")
self.opened = True
self.count = 0
except Exception as e:
print(e)
def close_spider(self,spider):
if self.opened:
self.conn.commit()
self.conn.close()
self.opened = False
print("db close")
print("crawl data : " + str(self.count))
def process_item(self, item, spider):
print(item["code"])
print(item["name"])
print(item["newest_price"])
print(item["up_down_extent"])
print(item["up_down_value"])
print(item["deal_volume"])
print(item["deal_value"])
print(item["freq"])
print(item["highest"])
print(item["lowest"])
print(item["opening"])
print(item["over"])
print()
if self.opened:
self.cursor.execute("insert into stocks (stockcode,stockname,stocknp,stockude,stockudv,stockdv1,stockdv2,stockfreq,stockhighest,stocklowest,stockopening,stockover) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(item["code"],item["name"],item["newest_price"],item["up_down_extent"],item["up_down_value"],item["deal_volume"],item["deal_value"],item["freq"],item["highest"],
item["lowest"],item["opening"],item["over"]))
self.count += 1
return item
main:
import requests
import re
import scrapy
import sys,os
sys.path.append(os.path.dirname(os.path.dirname(__file__)))
from items import StockDemoItem
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63"}
class Scrapy_Stock(scrapy.Spider):
name = "xrfSpider"
s = 1
e = 5
def start_requests(self):
url = "http://31.push2.eastmoney.com/api/qt/clist/get?cb=jQuery11240033772650735816256_1601427948453&pn={:,d}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:128+t:3,m:128+t:4,m:128+t:1,m:128+t:2&\
fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f19,f20,f21,f23,f24,f25,f26,f22,f33,f11,f62,f128,f136,f115,f152&_=1601427948454".format(1)
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response):
try:
html = response.text
# print(html)
res = re.findall(re.compile("\[(.+)\]"),html)[0]
res = res.split("},") # split by } , but need to fix
for idx,info in enumerate(res):
if idx != 19:# reach 19 dont add }
info = info + "}" # make a complete dict
info = eval(info) # construct a dict
item = StockDemoItem()
item["code"] = info["f12"]
item["name"] = info["f14"]
item["newest_price"] = info["f2"]
item["up_down_extent"] = info["f3"]
item["up_down_value"] = info["f4"]
item["deal_volume"] = info["f5"]
item["deal_value"] = info["f6"]
item["freq"] = info["f7"]
item["highest"] = info['f15']
item["lowest"] = info['f16']
item["opening"] = info['f17']
item["over"] = info['f18']
yield item
if (self.s != self.e):
self.s += 1
new_url = "http://31.push2.eastmoney.com/api/qt/clist/get?cb=jQuery11240033772650735816256_1601427948453&pn={:,d}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:128+t:3,m:128+t:4,m:128+t:1,m:128+t:2&\
fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f19,f20,f21,f23,f24,f25,f26,f22,f33,f11,f62,f128,f136,f115,f152&_=1601427948454".format(
self.s)
yield scrapy.Request(url = new_url,callback=self.parse)
except Exception as e:
print(e)
-
以上是没有采用 xpath 的版本,既然如此那我们就玩玩 selenium ,selenium 的操作也是非常简单,但是翻到第二页的时候他居然给我报了个找不到元素的错误,不知道翻到第二页网页遇到了什么鬼...所以只爬了一页嗷。由于 selenium 不太适合继续用 scrapy 继续操作,那我就另起炉灶~
好的这是一次更新,今天听完课以后突然想到我的 time.sleep() 加错地方辽55555555,难怪翻到第二页以后突然提示我元素找不到,应该是前天脑细胞不够没有想到应该让他在翻页以后停一小会儿。所以改掉以后就发现能跑了能翻页了hiahiahia~ -
运行结果
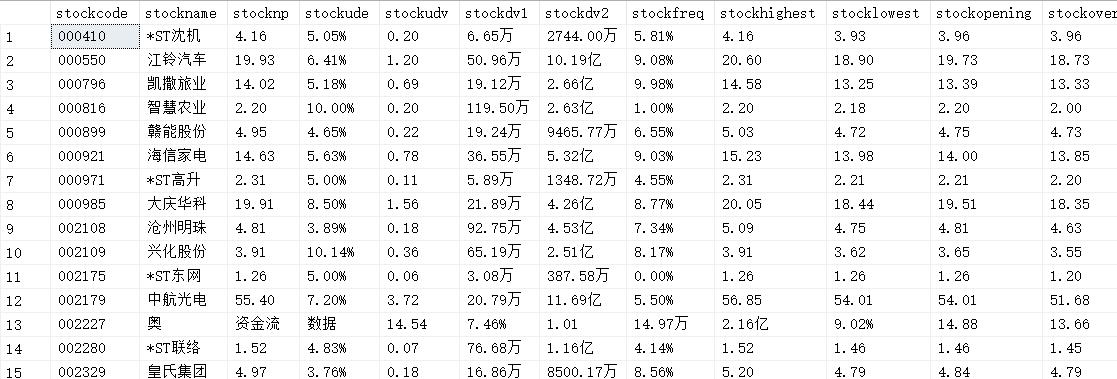
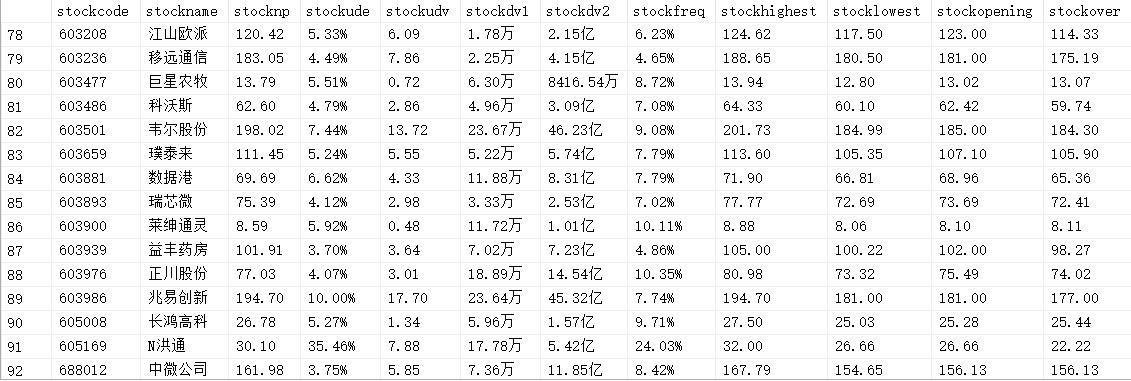
- main
import selenium
from selenium import webdriver
import pymssql
import time
conn = pymssql.connect(host="localhost", user="sa", password="******", database="xrfdb")
cursor = conn.cursor()
cursor.execute("delete from stocks")
driver = webdriver.Edge("C:\Program Files (x86)\Microsoft\Edge\Application\msedgedriver.exe")
def get_data():
driver.get("http://quote.eastmoney.com/center/gridlist.html#hs_a_board")
try:
for cnt in range(5):
tr_list = driver.find_elements_by_xpath("//div[@class='listview full']/table[@class='table_wrapper-table']/tbody/tr")
for tr in tr_list:
tr_val = tr.text.split(" ")
code = tr_val[1]
name = tr_val[2]
newest_price = tr_val[6]
up_down_extent = tr_val[7]
up_down_value = tr_val[8]
deal_volume = tr_val[9]
deal_value = tr_val[10]
freq = tr_val[11]
highest = tr_val[12]
lowest = tr_val[13]
opening = tr_val[14]
over = tr_val[15]
cursor.execute(
"insert into stocks (stockcode,stockname,stocknp,stockude,stockudv,stockdv1,stockdv2,stockfreq,stockhighest,stocklowest,stockopening,stockover) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(code, name, newest_price, up_down_extent, up_down_value, deal_volume, deal_value, freq, highest, lowest,
opening, over))
# go to next pageeeeeee!
driver.find_elements_by_xpath("//a[@class='next paginate_button']")[-1].click()
# f**king bug
time.sleep(5)
except Exception as e:
print(e)
get_data()
conn.commit()
conn.close()
作业三
-
这个作业也是比较简单的作业,网页静态加载,看到 HTML 然后直接用 xpath 提取即可~
-
爬取结果
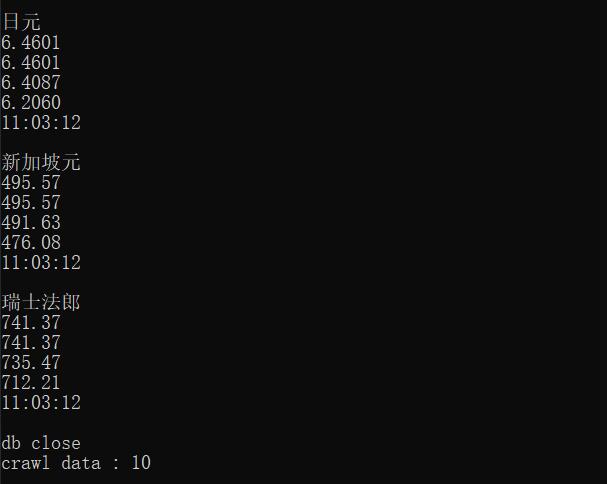
- 源代码
items:
import scrapy
class CurrencydemoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
currencyname = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
currenttime = scrapy.Field()
pass
pipeline:
from itemadapter import ItemAdapter
import pymssql
class CurrencydemoPipeline:
def open_spider(self, spider):
try:
# connect my SQL SERVER but need to open TCP/IP interface (with cmd)
self.conn = pymssql.connect(host="localhost", user="sa", password="******", database="xrfdb")
self.cursor = self.conn.cursor()
self.cursor.execute("delete from currency")
self.opened = True
# num of data
self.count = 0
except Exception as e:
print(e)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.conn.commit()
self.conn.close()
self.opened = False
print("db close")
print("crawl data : " + str(self.count))
def process_item(self, item, spider):
try:
print(item["currencyname"])
print(item["TSP"])
print(item["CSP"])
print(item["TBP"])
print(item["CBP"])
print(item["currenttime"])
print()
if self.opened:
self.cursor.execute("insert into currency (currencyname,tsp,csp,tbp,cbp,currenttime) VALUES (%s,%s,%s,%s,%s,%s)",
(item["currencyname"],item["TSP"],item["CSP"],item["TBP"],item["CBP"],item["currenttime"]))
self.count += 1
except Exception as e:
print(e)
return item
main:
import scrapy
import sys,os
sys.path.append(os.path.dirname(os.path.dirname(__file__)))
from items import CurrencydemoItem
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
class MySpider(scrapy.Spider):
name = "xrfspider"
def start_requests(self):
url = "http://fx.cmbchina.com/hq/"
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response, **kwargs):
try:
dammit = UnicodeDammit(response.body,["utf-8","gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
table = selector.xpath("//div[@id='realRateInfo']/table[@class='data']/tr")
for idx,tr in enumerate(table):
# table head will skip it
if (idx == 0):
continue
# get name,tsp,csp,tbp,cbp,time sequentially
name = tr.xpath("./td[@class='fontbold']/text()").extract_first()
time = tr.xpath("./td[@align='center']/text()").extract()[2]
v_list = tr.xpath("./td[@class='numberright']/text()").extract()
item = CurrencydemoItem()
item["currencyname"] = name.strip()
item["TSP"] = v_list[0].strip()
item["CSP"] = v_list[1].strip()
item["TBP"] = v_list[2].strip()
item["CBP"] = v_list[3].strip()
item["currenttime"] = time.strip()
yield item
except Exception as e:
print(e)
作业心得(汇总)
这次作业还是挺简单的,主要学到了爬取数据之后将数据存放到本地的数据库中,以及巩固了 scrapy 框架和 xpath 的用法,算是对我软件工程的后端工作做了点基础工作(xixixi)。然后等待 HTML 元素的加载还是很重要的555。如果以后在服务器上爬,面对 linux 系统,可以尝试使用 Hbase 来存储数据,期待ing...
