数据采集与融合第三次个人作业
写在前面
本次作业是关于多线程对于爬虫的运用以及采用 scrapy 框架来编写爬虫,先写个小插曲。之前做软工作业的时候发现 python 的多线程是个鸡肋,因为在加了 GIL 锁的 python,多线程和单线程几乎无差别,甚至多线程可能更慢。但是周三用多线程测试之后颠覆了我的观点,搜完之后就摒弃对 python 多线程的偏见~
先讲一下 IO 密集型任务和计算密集型任务:
- IO 密集型任务
- 所谓IO密集型任务,是指磁盘IO、网络IO占主要的任务,计算量很小。比如请求网页、读写文件等。
- 计算密集型任务
- 所谓计算密集型任务,是指CPU计算占主要的任务,CPU一直处于满负荷状态。比如在一个很大的列表中查找元素(当然这不合理),复杂的加减乘除等。
先说结论,多线程主要处理 IO 密集型任务,而多进程处理计算密集型任务。原因就是操作系统的知识了,多进程切换开销非常大,占用内存多,虽然不适合同步操作,但是人家算力够猛;而多线程共享进程内数据,同步简单但是算力不行。
接下来就是本实验采取的依旧是 re 和 beautifulsoup 来实现,因为还是前者用的顺手,后者对我的吸引力实在太小了,但实验一和二的Xpath版本已补充~
另外 scrapy 框架我觉得使用并不是很灵活,因为该框架的特点主要是针对大型爬虫项目,并且通过异步处理来加速这个过程。对于小型项目还是使用 beautifulsoup 和 request 的效率更高,经过周五的课之后学会了在 scrapy 中翻页,本实验已在实验三更新 scrapy 框架写法~
实验一
-
这个实验是书上的实验,只要理解代码逻辑照打一遍就行。关键看一下多线程嵌套的方式,多线程处理的是 download 函数,也就是处理的 IO 密集型任务,天生的优势啊,单线程要1.4秒,而多线程只需要0.6秒,当需要爬取的数据足够多时这个差距会被明显拉大。(周三开着流量跑的,单线程11秒出头,但是使用多线程只需要1秒多,足以看出差距)
-
结果
-
单线程代码
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36 Edg/86.0.622.38"}
url = "http://www.weather.com.cn"
import time
def image_Spider(url):
try:
image_urls = []
req = urllib.request.Request(url,headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data,["utf-8","gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data,"lxml")
images = soup.select("img")
for image in images:
try:
src = image["src"]
image_url = urllib.request.urljoin(url,src)
if image_url not in image_urls:
image_urls.append(image_url)
download(image_url)
except Exception as e:
print(e)
except Exception as ee:
print(ee)
def download(url):
global count
try:
count += 1
if (url[len(url)-4] == "."):
ext = url[len(url)-4:]
else:
ext = ""
req = urllib.request.Request(url,headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
fobj = open("./images/" + str(count) + ext,"wb")
fobj .write(data)
fobj.close()
except Exception as eee:
print(eee)
count = 0
start = time.time()
image_Spider(url)
end = time.time()
print("consuming_time : " + str(end-start))
- 多线程代码
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36 Edg/86.0.622.38"}
url = "http://www.weather.com.cn"
import time
import threading
import mmap
def image_Spider(url):
global threads
global count
try:
image_urls = []
req = urllib.request.Request(url,headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data,["utf-8","gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data,"lxml")
images = soup.select("img")
for image in images:
try:
src = image["src"]
image_url = urllib.request.urljoin(url,src)
if image_url not in image_urls:
count += 1
T = threading.Thread(target=download,args=(image_url,count))
T.setDaemon(False)
T.start()
threads.append(T)
image_urls.append(image_url)
except Exception as e:
print(e)
except Exception as ee:
print(ee)
def download(url,count):
try:
if (url[len(url)-4] == "."):
ext = url[len(url)-4:]
else:
ext = ""
req = urllib.request.Request(url,headers=headers)
data = urllib.request.urlopen(req,timeout=100)
data = data.read()
fobj = open("./images2/" + str(count) + ext,"wb")
fobj.write(data)
fobj.close()
except Exception as eee:
print(eee)
count = 0
threads = []
start = time.time()
image_Spider(url)
for t in threads:
t.join()
end = time.time()
print("consuming_time : " + str(end - start))
- 收获
明确了 python 多线程和多进程能够处理的任务类型,并且学会了使用 python 多线程来处理 IO 密集型任务。
实验二
这个实验要通过 scrapy 框架来复现实验一的结果,首先要明白 scrapy 框架是如何工作的,然后怎么运行 scrapy 框架编写的爬虫,代码结果同上,直接上代码以及使用方法。而且实验二爬取项非常少,根本不需要重写 item 和 pipeline 。
- 单线程代码
import scrapy
from bs4 import UnicodeDammit
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import time
class Scrapy_Weather_forecast(scrapy.Spider):
name = "xrfSpider"
def start_requests(self):
self.url = "http://www.weather.com.cn"
yield scrapy.Request(url=self.url,callback=self.parse)
def parse(self, response, **kwargs):
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36 Edg/86.0.622.38"}
start = time.time()
count = 0
self.image_Spider(self.url)
end = time.time()
print("consuming_time : " + str(end-start))
def image_Spider(self,url):
try:
image_urls = []
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
images = soup.select("img")
for image in images:
try:
src = image["src"]
image_url = urllib.request.urljoin(url, src)
if image_url not in image_urls:
image_urls.append(image_url)
self.download(image_url)
except Exception as e:
print(e)
except Exception as ee:
print(ee)
def download(self,url):
try:
self.count += 1
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
fobj = open("./images/" + str(self.count) + ext, "wb")
fobj.write(data)
fobj.close()
except Exception as eee:
print(eee)
- 多线程代码
import scrapy
from bs4 import UnicodeDammit
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import time
import threading
class Scrapy_Weather_forecast(scrapy.Spider):
name = "xrfSpider"
def start_requests(self):
self.url = "http://www.weather.com.cn"
yield scrapy.Request(url=self.url,callback=self.parse)
def parse(self, response, **kwargs):
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36 Edg/86.0.622.38"}
start = time.time()
url = "http://www.weather.com.cn"
global threads
threads = []
count = 0
self.image_Spider(url,headers,count)
for t in threads:
t.join()
end = time.time()
print("consuming_time : " + str(end-start))
def image_Spider(self,url,headers,count):
try:
image_urls = []
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
images = soup.select("img")
for image in images:
try:
src = image["src"]
image_url = urllib.request.urljoin(url, src)
if image_url not in image_urls:
count += 1
T = threading.Thread(target=self.download, args=(image_url, count,headers))
T.setDaemon(False)
T.start()
threads.append(T)
image_urls.append(image_url)
except Exception as e:
print(e)
except Exception as ee:
print(ee)
def download(self,url, count,headers):
try:
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("./images2/" + str(count) + ext, "wb")
fobj.write(data)
fobj.close()
except Exception as eee:
print(eee)
- 实验二补充使用 Xpath 获得图片路径并下载的代码
selector = Selector(text=data)
selector.xpath("//img")
urls = s.xpath("//img/@src").extract()
for u in urls:
if u not in image_urls:
image_urls.append(u)
self.download(u)
-
运行方法
现在当前目录文件夹下打开 cmd 用 scrapy startproject [projectname] 创建一个 scrapy 项目,然后直接进到这个项目的spider文件夹,在此处编写代码,之后通过 cmd 使用 scrapy runspider [pythonfilename] 运行。 -
收获
学会使用 scrapy 框架来编写爬虫,并且了解如何运行 scrapy 框架。
实验三
实验采用 scrapy 框架复现股票信息爬取,思路和上一次一样,但是这次尝试了一下之前没有试过的 prettytable,发现这东西用起来真香...(上一次实验为了得到规范化的数据我采用了pandas 导出 csv 格式文件来输出结果)
- 结果
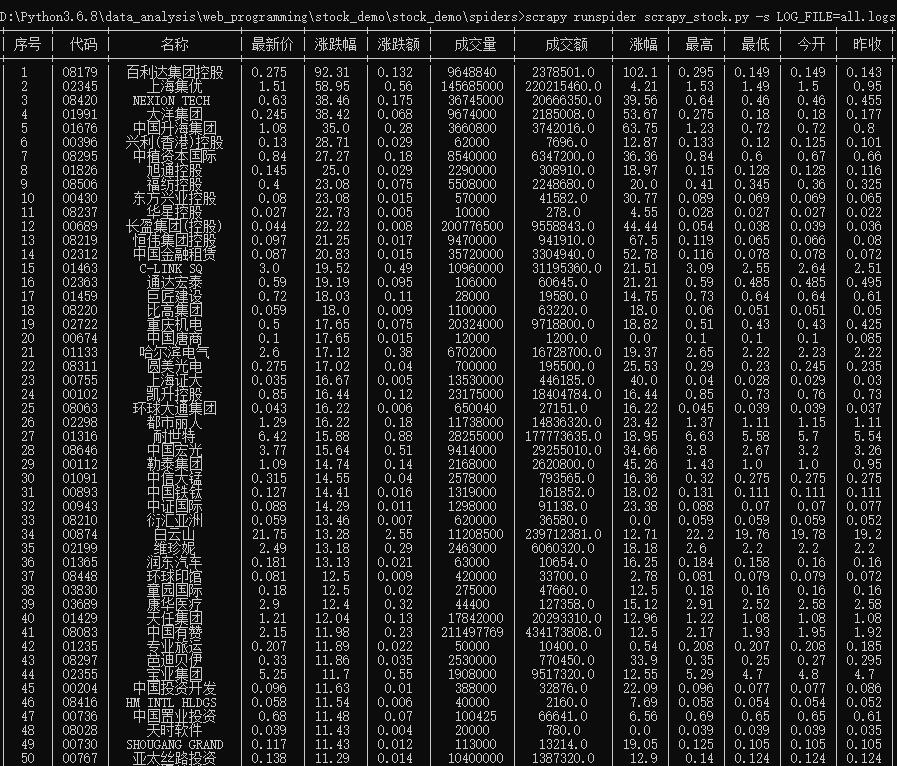
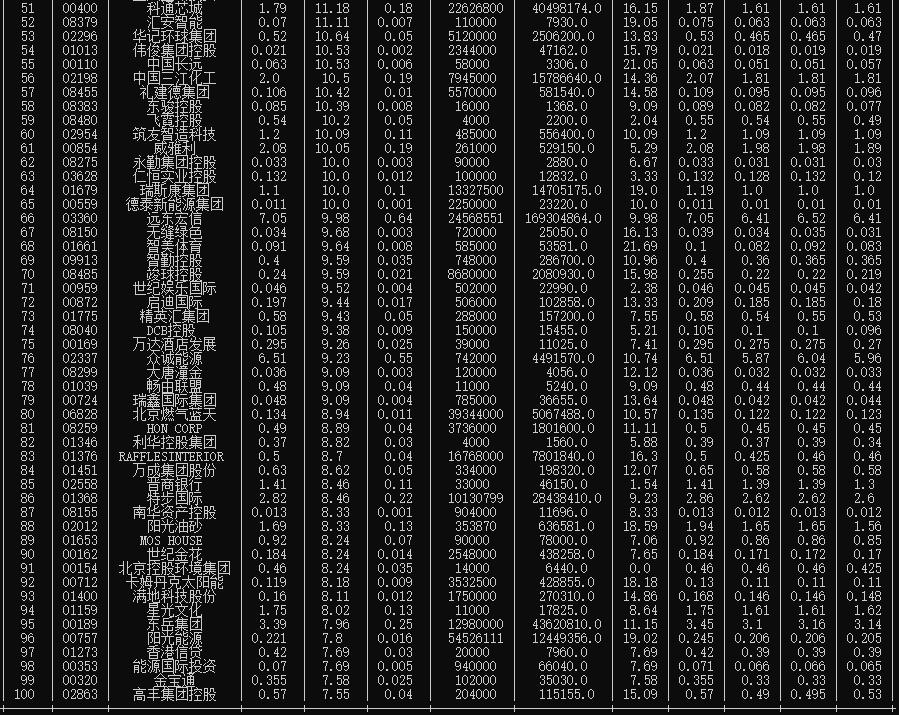
- items
import scrapy
class StockDemoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
idx = scrapy.Field()
code = scrapy.Field()
name = scrapy.Field()
newest_price = scrapy.Field()
up_down_extent = scrapy.Field()
up_down_value = scrapy.Field()
deal_volume = scrapy.Field()
deal_value = scrapy.Field()
freq = scrapy.Field()
highest = scrapy.Field()
lowest = scrapy.Field()
opening = scrapy.Field()
over = scrapy.Field()
pass
- pipeline
class StockDemoPipeline:
pt = PrettyTable()
pt.field_names = ["序号", "代码", "名称", "最新价", "涨跌幅", "涨跌额", "成交量", "成交额", "涨幅", "最高", "最低", "今开", "昨收"]
def process_item(self, item, spider):
self.pt.add_row([item["idx"], item["code"], item["name"], item["newest_price"], item["up_down_extent"],
item["up_down_value"], item["deal_volume"], item["deal_value"], item["freq"], item["highest"],
item["lowest"], item["opening"], item["over"]])
if (item["idx"] == 100):
print(self.pt)
return item
- spider
import requests
import re
import scrapy
import sys,os
sys.path.append(os.path.dirname(os.path.dirname(__file__)))
from items import StockDemoItem
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63"}
class Scrapy_Stock(scrapy.Spider):
name = "xrfSpider"
s = 1
e = 5
def start_requests(self):
url = "http://31.push2.eastmoney.com/api/qt/clist/get?cb=jQuery11240033772650735816256_1601427948453&pn={:,d}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:128+t:3,m:128+t:4,m:128+t:1,m:128+t:2&\
fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f19,f20,f21,f23,f24,f25,f26,f22,f33,f11,f62,f128,f136,f115,f152&_=1601427948454".format(1)
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response):
# print("序号 代码 名称 最新价 涨跌幅 涨跌额 成交量(股) 成交额(港元) 涨幅 最高 最低 今开 昨收")
try:
html = response.text
# print(html)
res = re.findall(re.compile("\[(.+)\]"),html)[0]
res = res.split("},") # split by } , but need to fix
for idx,info in enumerate(res):
if idx != 19:# reach 19 dont add }
info = info + "}" # make a complete dict
info = eval(info) # construct a dict
item = StockDemoItem()
item["idx"] = idx + 1 + 20 * (self.s - 1)
item["code"] = info["f12"]
item["name"] = info["f14"]
item["newest_price"] = info["f2"]
item["up_down_extent"] = info["f3"]
item["up_down_value"] = info["f4"]
item["deal_volume"] = info["f5"]
item["deal_value"] = info["f6"]
item["freq"] = info["f7"]
item["highest"] = info['f15']
item["lowest"] = info['f16']
item["opening"] = info['f17']
item["over"] = info['f18']
yield item
if (self.s != self.e):
self.s += 1
new_url = "http://31.push2.eastmoney.com/api/qt/clist/get?cb=jQuery11240033772650735816256_1601427948453&pn={:,d}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:128+t:3,m:128+t:4,m:128+t:1,m:128+t:2&\
fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f19,f20,f21,f23,f24,f25,f26,f22,f33,f11,f62,f128,f136,f115,f152&_=1601427948454".format(
self.s)
yield scrapy.Request(url = new_url,callback=self.parse)
except Exception as e:
print(e)
- 翻页的实现(周五课上完后更新)
if (self.s != self.e):
self.s += 1
new_url = "http://31.push2.eastmoney.com/api/qt/clist/get?cb=jQuery11240033772650735816256_1601427948453&pn={:,d}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:128+t:3,m:128+t:4,m:128+t:1,m:128+t:2&\
fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f19,f20,f21,f23,f24,f25,f26,f22,f33,f11,f62,f128,f136,f115,f152&_=1601427948454".format(
self.s)
yield scrapy.Request(url = new_url,callback=self.parse)
- 收获
和上一个实验一样的,但是学会了 prettytable 的用法~
