数据采集与融合第一次~第三次作业
第一次作业
- 作业分析
- 第一次作业是爬取大学的排名,依旧是老办法打开 F12,那么可以发现每个大学信息和排名的位置都位于 td 标签内,再寻找一下他们的父标签是 tbody ,那么思路很清晰直接调用
bs4 库配上属性值找到包含大学排名信息的 tbody 标签,调用 children 方法并且在子标签内找到 td 标签,提取相关的文本信息,第一题就大功告成~
- 第一次作业是爬取大学的排名,依旧是老办法打开 F12,那么可以发现每个大学信息和排名的位置都位于 td 标签内,再寻找一下他们的父标签是 tbody ,那么思路很清晰直接调用
- 爬取结果
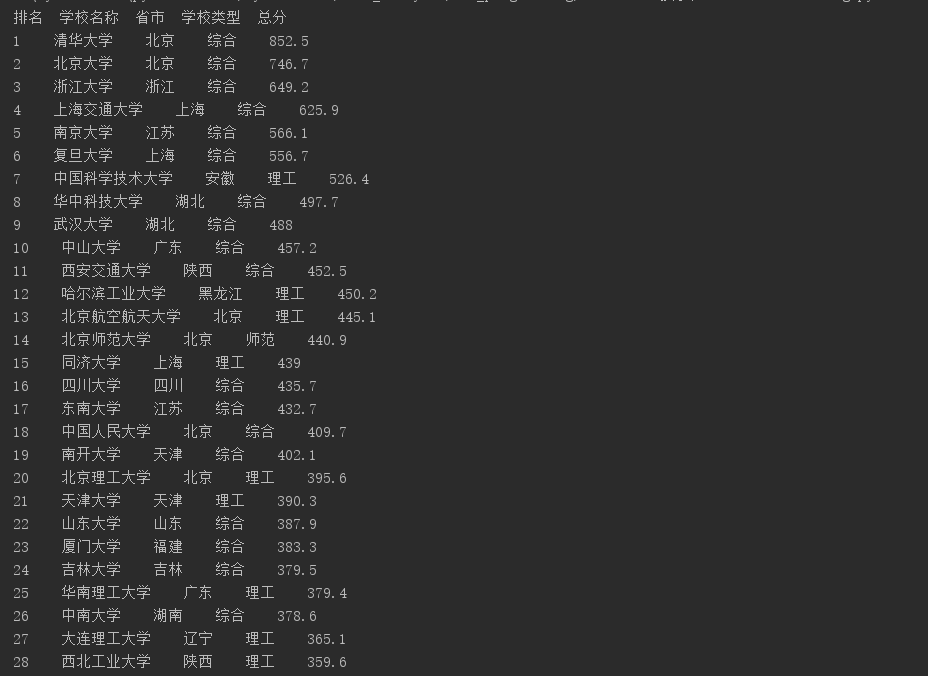
- 相关代码
import requests,bs4
bsobj = bs4.BeautifulSoup(requests.get("http://www.shanghairanking.cn/rankings/bcur/2020",headers={"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Edg/85.0.564.51"}).content.decode(),"html.parser")
print("排名 学校名称 省市 学校类型 总分")# 爬取太多次会被限制爬取,所以想要爬多次的话需要每次都更换headers
for child in bsobj.find("tbody").children:
info = child.find_all("td")
print(info[0].text.strip()+" "+info[1].text.strip()+" "+info[2].text.strip()+" "+info[3].text.strip()+" "+info[4].text.strip())
- 代码分析
- 代码十分容易理解并且精悍简短(误),虽然加上了headers伪装成浏览器,但是遇到下一个作业有着强大反爬功能的 alibaba 就连 selenium 也都束手无策(提前剧透)。
本代码的缺点是,输出排名的时候不够美观,比如没有对齐~
- 代码十分容易理解并且精悍简短(误),虽然加上了headers伪装成浏览器,但是遇到下一个作业有着强大反爬功能的 alibaba 就连 selenium 也都束手无策(提前剧透)。
第二次作业
啊哈这么快就来到第二次作业了,一开始的爬取淘宝商品页可真是个脑力体力活,先不说能不能让我的可爱 spider 到达淘宝的页面,每次都跳出登陆提示所以想爬取淘宝页面真的想 peach。
既然 bs4 已经不能简单满足我爬取淘宝商品页的欲望,那么我就自然而然的想到当初爬取网易云时用的 selenium ,也就是模仿人点击浏览器的行为去爬取淘宝,正当小爷我美滋滋的写完代码运行的时候,发现绕过登录后居然还要拖动滑块验证,运行多次发现淘宝的 JS 已经出了检测 selenium 的功能了... 毫无头绪的我只能转战欺负某东 QAQ 。
-
selenium 简介
- Selenium 是一个用于 Web 应用程序测试的工具,Selenium 直接运行在浏览器中,就像真正的用户在操作一样。由于这个性质,Selenium 也是一个强大的网络数据采集工具,
其可以让浏 览器自动加载页面,这样,使用了异步加载技术的网页,也可获取其需要的数据。
但是呢,Selenium 需要下载相应浏览器的 webdriver ,才能通过本机的浏览器访问目标页面。Selenium 和 PhantomJS 的配合使用可以完全模拟用户在浏览器上的所有操作,包括输入框内容填写、单击、截屏、下滑等各种操作。这样,对于需要登录的网站,用户可以不需要通过构造表单或提交 cookie 信息来登录网站。
- Selenium 是一个用于 Web 应用程序测试的工具,Selenium 直接运行在浏览器中,就像真正的用户在操作一样。由于这个性质,Selenium 也是一个强大的网络数据采集工具,
-
附上selenium 爬取的部分代码
class taobaospider():
def __init__(self):
self.browser = webdriver.Chrome()
# 最大化窗口
self.browser.maximize_window()
self.browser.implicitly_wait(5)
self.domain = 'http://www.taobao.com'
self.action_chains = ActionChains(self.browser)
def login(self, username, password):
while True:
self.browser.get(self.domain)
time.sleep(1)
self.browser.find_element_by_xpath('//*[@id="J_SiteNavLogin"]/div[1]/div[1]/a[1]').click()
self.browser.find_element_by_xpath('//*[@id="fm-login-id"]').send_keys(username)#输入用户名
self.browser.find_element_by_xpath('//*[@id="fm-login-password"]').send_keys(password)#输入密码
time.sleep(1)
好的进入正题,先给出爬取某东书包商品页的结果~

- 相关代码
def get_Html_And_Parse():
# get html content
try:
html = requests.get(url,headers = headers)
html.encoding = html.apparent_encoding
html = html.text
except:
print("get url wrong")
# process of parsing
message = []
try:
soup = bs4.BeautifulSoup(html,"html.parser")
info_list = soup.find_all("li",{"data-sku":re.compile("\d+")})# 所有的商品信息都在满足该条件的li标签中
print(len(info_list))
for ms in info_list:
price = ms.find("div",{"class":"p-price"})
name = ms.find("div",{"class":"p-name p-name-type-2"}).find("em")
message.append([name.text.strip() + " " + price.text.strip()])
except:
print("something wrong")
for info in message:
print(info)
get_Html_And_Parse()
- 代码说明
- 爬取网站:京东;此代码只选择爬取第一页,因为翻页的话 HTML 源代码没有给出 hyperlink 而是通用调用 JS 来监控鼠标或者键盘从而跳转到下一页
但是之后发现翻到第二页在网页的 url 中有 page 字段如果,所以要爬取多页需要建立循环传入不同的 page ,只需要把从第二页开始的带 page 的 url 传入并修改即可。
问题:爬取整个页面的 li 标签发现只有30个商品,但总共有60个,就算提取母标签再来取出商品也是只有 30 个。如果想要爬取全部信息的话需要循环调用
get_Html_And_Parse 函数,解析 JS ,翻页的按钮在 a 标签中,只要判断 a 标签的 class 为 pn-next disabled 即跳转到了最后一页。
还有一个问题就是,对商品的处理不够细致,打印出来的信息存在换行符。
- 爬取网站:京东;此代码只选择爬取第一页,因为翻页的话 HTML 源代码没有给出 hyperlink 而是通用调用 JS 来监控鼠标或者键盘从而跳转到下一页
第三次作业
- 作业分析
- 第三次作业算是比较简单的作业,因为作业要求仅仅只是爬取给定页面的图像页面,那么思路非常清晰而且简单,只要用正则找到图片的超链接然后存储下来再进行访问即可。
所以先用正则来匹配图片的后缀,只要成功就 append 进 list。但是呢,你会发现 HTML 中图片是没有超链接的,果不其然,打开 networks 模块你会发现所有的图片都是
通过JS加载过来的。好家伙,我以为这又是一场高端局,点开其中一个文件,心里突然笑嘻嘻了,请求的 url 恰好是图片的链接,也就是网页名+图片名,那么解决思路呼之欲出,
只需要在图片前缀加上网站名即可。
- 第三次作业算是比较简单的作业,因为作业要求仅仅只是爬取给定页面的图像页面,那么思路非常清晰而且简单,只要用正则找到图片的超链接然后存储下来再进行访问即可。
- 爬取结果

- 相关代码
import bs4,requests,re
import os
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Edg/85.0.564.51"}
url = "http://xcb.fzu.edu.cn/"
def get_Html_And_parsing(url):
all_img = []
try:
#获取并且解析页面
html = requests.get(url,headers=headers)
html = html.content.decode()
soup = bs4.BeautifulSoup(html,"html.parser")
img_list = soup.find_all("img",{"src":re.compile("(.+)\.(png|jpg)")})
for img in img_list:
img_name = img.attrs["src"]
if str(img_name).startswith("http"):
continue
complete_img_url = url[:len(url)-1]+img_name
all_img.append(complete_img_url)
except:
print("get url wrong")
return all_img
def write_Into_FileFolder(img_list):
# 把读取到的链接中的文件写到本地
for img_url in img_list:
img_content = requests.get(img_url,headers = headers).content
with open("jpg_filefolder/"+img_url[-8:-4]+".jpg","wb") as f:
# 取url的倒数第八到第四的字符串当文件名
f.write(img_content)
if __name__ == "__main__":
if not os.path.exists("jpg_filefolder"):
os.mkdir("jpg_filefolder")
img_list = get_Html_And_parsing(url)
write_Into_FileFolder(img_list)
- 作业拓展与优化
- 我们可以想想,现在作业的要求只是爬取一个页面,但是如果要爬取一个网站的所有页面下的图片呢?
- 思路:
先创建一个集合来保存爬取到的 url ,目的是为了进行去重,接下来通过 dfs 来遍历到站点内的所有网页再提取图片。但是这样还是有一个很大的问题,
首先难以解决服务器的问题,你的内存资源是否够用以及能否存下如此多的信息? 第二个问题就是你的速度问题,如果站点网页太多,那么可能深搜的
时间复杂度就太高了,所以集合的目的就是为了防止重复访问相同的站点。第三个问题就是如果只用你个人的 IP 爬取,如果爬取太多被检测到会被封 IP,
所以你需要一个够大的 IP 代理池。 - 优化:
其实可以创建一个多进程爬虫来加速你的爬取页面处理数据的速度,因为python的多线程是假的多线程,被加了GIL锁,所以开了和没开一样~
多进程爬取的步骤和把大象放进冰箱的步骤一样:
1.先创建一个进程池
2.把要处理的东西丢给进程池中的进程
3.关闭进程池
具体代码下次实现Hhhhh...
总结
前三次作业主要是考察对 beautifulsoup 和 re 库的运用,也就是搜索+查找。这也是一个较为普遍的应用,接下来希望进一步拓展爬虫技能,继续熟悉 selenium 和
学习 scrapy,造出更猛更安全的爬虫 hhhhh
