


【机器学习】异常检测算法(I)
在给定的数据集,我们假设数据是正常的 ,现在需要知道新给的数据Xtest中不属于该组数据的几率p(X)。
异常检测主要用来识别欺骗,例如通过之前的数据来识别新一次的数据是否存在异常,比如根据一个用户以前的使用习惯(数据)来判断这次使用的用户是不是以前的用户。或者根据之前CPU正常运行时候的的用量数据来判断当前状态下的CPU是否正常工作。
这里我们通过密度估计来进行判断:if P(X) >ε时候,为normal(正常)<ε 的时候为异常 。
我们用x(i)来表示用户的第i个特征,模型P(x)= 我们其属于一组数据的可能性
在这里我们会用到高斯分布(二项分布),在高斯分布中,我们 对于方差通常只除以m来得到μ和σ而不是统计学中的m-1
异常检测算法:
对于给定的数据集x(1)...x(m),我们要针对每一个特征计算出μ和σ的估计值。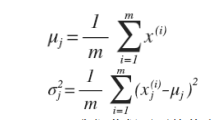
一旦我们获得了平均值和方差的估计值,给定的一个新的训练实例,根据模型计算我们就可以得出p(x)

我们选择一个 ε,将p(x)=ε作为我们的判定边界,当p(x)> ε的时候预测数据为正常数据,否则为异常数据。
异常检测算是一个非监督学习算法,这意味着我们无法根据结果变量Y 的值来告诉我们是否异常,我们可以从带标记的数据着手,选取一部分正常的数据用来训练和构建,然后用剩下的正常样本和测试样本混合构成交叉检验集和测试集。
在这里我们举一个栗子,用来更详细的描述异常检测算法。
例如:我们有 10000 台正常引擎的数据,有 20 台异常引擎的数据。 我们这样分配数
据:
6000 台正常引擎的数据作为训练集
2000 台正常引擎和 10 台异常引擎的数据作为交叉检验集
2000 台正常引擎和 10 台异常引擎的数据作为测试集
具体的评价方法如下:
1. 根据测试集数据,我们估计特征的平均值和方差并构建 p(x)函数
2. 对交叉检验集,我们尝试使用不同的 ε 值作为阀值,并预测数据是否异常,根据 F1
值或者查准率与查全率的比例来选择 ε
3. 选出 ε 后,针对测试集进行预测,计算异常检验系统的 F1 值, 或者查准率与查全
率之比
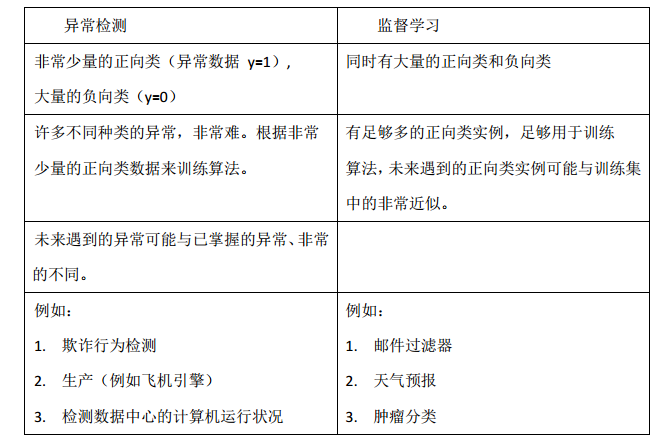
之前我们构建的异常检测系统也使用了带标记的数据,与监督学习有些相似,下面的对
比有助于选择采用监督学习还是异常检测:
两者比较:
posted on 2017-08-18 10:40 KID_XiaoYuan 阅读(953) 评论(0) 编辑 收藏 举报

