


【机器学习】逻辑回归
逻辑回归问题举例:
垃圾邮件分类问题:如何根据邮件的特性判断他是否是垃圾邮件?
这是一个二元逻辑回归问题,分类结果有两类,1:是垃圾邮件,这是一个负向类,用0来表示。2:不是垃圾邮件,这是一个正向类,用1来表示。
线性的回归模型我们只能预测连续的值,然而这种二分类问题,它的值通常是离散的,要预测这样的值,我们可以假设假设函数h(θ)>0.5时,输出结果是1,小于0.5时,输出结果为0.
但是,样例中容易存在特例,如图:
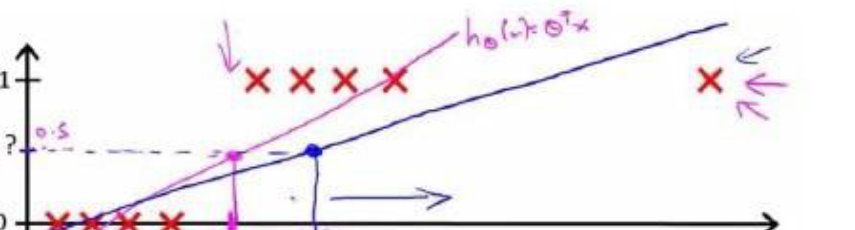
这时候再用0.5作为阈值就不再合适了,此时,我们引入逻辑回归模型:
逻辑回归模型:

其中X代表特征向量,
g代表逻辑函数,通常逻辑函数是一个S形曲线。
公式为
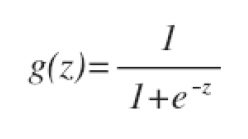
其图像为:
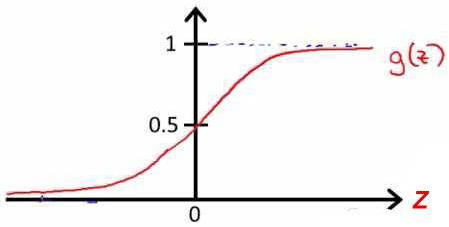
带入得到h
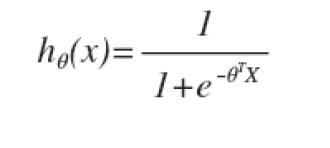
h的作用是,对于给定的输入x,给出的参数θ,得出输出变量 = 1的所有可能性,即
例如,对给定的x,我们算出的h就是有h的几率y为正向类。
边界判定
在如上图所示的分类问题中,我们可以假设假设模型, ,并且参数θ是向量[-3,1,1],则当x1+x2≥3时,模型预测y = 1,此时我们通过直线讲两类分开,这个直线便是我们的模型分界线,讲预测为1的区域和预测为0的区域分开。那么对更复杂的图像,如图,我们该找出怎样的模型才能分开呢?
,并且参数θ是向量[-3,1,1],则当x1+x2≥3时,模型预测y = 1,此时我们通过直线讲两类分开,这个直线便是我们的模型分界线,讲预测为1的区域和预测为0的区域分开。那么对更复杂的图像,如图,我们该找出怎样的模型才能分开呢?

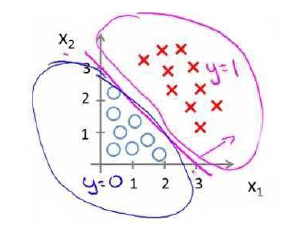
可以看出,需要一个曲线才能分开,因此我们可以假设特征方程是一个高次的,假设函数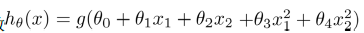 的参数是[-1 0 0 1 1],则我们得到的判定边界恰好是一个半径为1的圆形,刚好可以把他们分开。
的参数是[-1 0 0 1 1],则我们得到的判定边界恰好是一个半径为1的圆形,刚好可以把他们分开。
实际上,在面对更为复杂的情况时候,我们需要更复杂的模型函数来判定边界。
代价函数:
对于线下回归模型,我们定义的代价函数是所有模型误差的平方和。理论上来说,我们可以对逻辑回归模型沿用这个定义,但是问题在于,当我们们把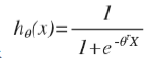 带入到这样的代价函数中的时候,得到的是一个非凸函数。这也就是说,我们的代价函数有许多局部最小值,这将影响梯度下降算法的局部最小值。
带入到这样的代价函数中的时候,得到的是一个非凸函数。这也就是说,我们的代价函数有许多局部最小值,这将影响梯度下降算法的局部最小值。
因此,我们重新定义逻辑回归的代价函数为
其中

这样构建的特点是当实际的y = 1且h也是1时候误差为0,当y =1 ,但h不是1时候误差随着h的变小而变大,当y = 0时,h也是0时候代价为0,当 y = 0但是h不为 0 时候误差随着h变大而变大。
将构建的函数带入化简得到J(θ)

我们所需要求的是θ的最小值,算法如下:
逻辑回归算法
to make a prediction given new x:
out put h(θ)x

![]()
repeat
{
θj := ![]()
}
预测误差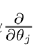 =
= ![]() ,带入得
,带入得
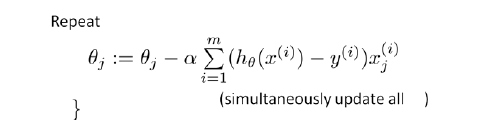
这里虽然也是梯度下降算法,但是与线性回归的梯度下降算法不同,不过在运行算法之前,我们同样需要对特征向量进行特征缩放,来是的算法有效的运行。
算法用octave语言表述如下:
function [jVal,gradient] = costFunction(theta)
jVal = [...code to compute J(theta)...];
gradient = [...code to compute derivative of J(theta)...];
end
options = optimset('GradObj','on''Maxlter','100');
initialTheta = zeros(2,1);
[optTheta,functionVal,exitFlag] = fminunc(@costFunction,initalTheta,options);
讨论多分类逻辑回归
逻辑回归分类器h(θ)(i)(x) = P(y = i|x;θ)(i ∈N+)
注:以上所以内容的θ均为向量,θ = [θ0,θ1,θ2 ,..., θn] T
posted on 2017-07-28 10:55 KID_XiaoYuan 阅读(376) 评论(0) 编辑 收藏 举报

