


【机器学习】从分类问题区别机器学习类型 与 初步介绍无监督学习算法 PAC
如果要对硬币进行分类,我们对硬币根据不同的尺寸重量来告诉机器它是多少面值的硬币 这种对应的机器学习即使监督学习,那么如果我们不告诉机器这是多少面额的硬币,只有尺寸和重量,这时候让机器进行分类,希望机器对不同种类的硬币分类,这种机器学习方式就是无监督学习。可以从下图看出,监督学习,根据颜色(面值)可以得出不同种类,而无监督学习也可根据所样例在的不同区域对样例进行分类。
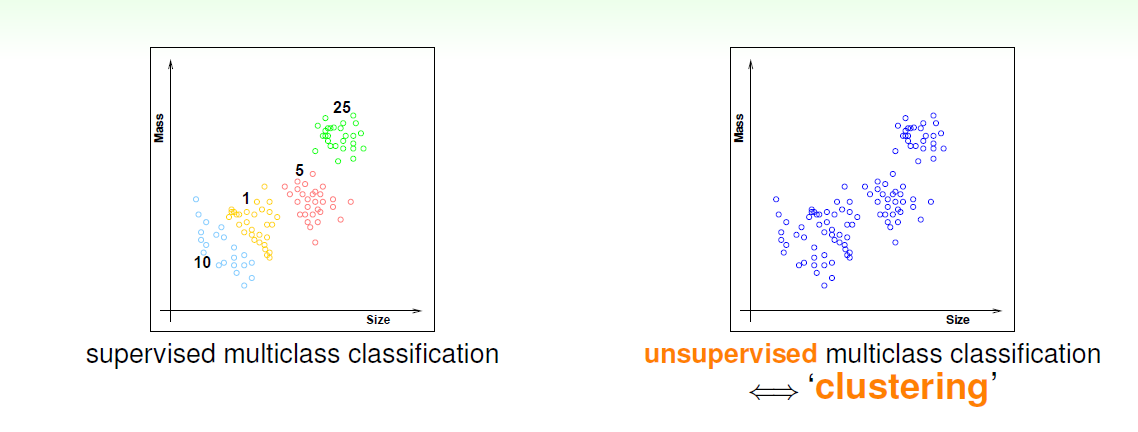
根据聚类分组clustering: {xn} -> cluster(x)
根据密度分组density estimation{Xn}->density(x)
根据离群值分组outlier detection{Xn}-> unusual(x)
是否告诉机器硬币的面额,可以分类为监督学习,半监督学习,无监督学习(告知硬币面额的用彩色标出,未告知的用蓝色标出)
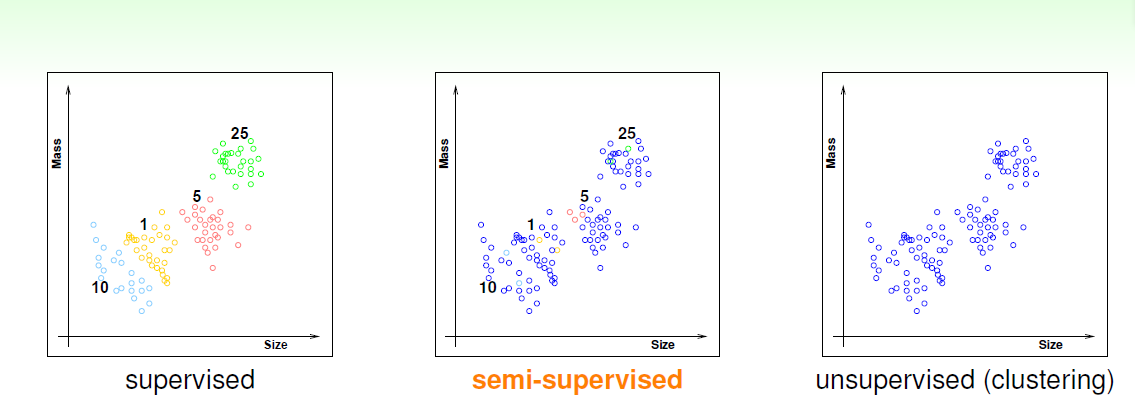
总结一下学习模式的区别

第二个例子:罐子取弹珠问题

现在假设一个罐子里有n个弹珠,分别是绿色与橙色,那么如何得出取绿色(橙色)的概率,现在设真实概率橙色为μ,而我们目前假设从中取出一部分弹珠,得出的橙色概率为v,那么我要做的就是让v和μ尽可能的接近,
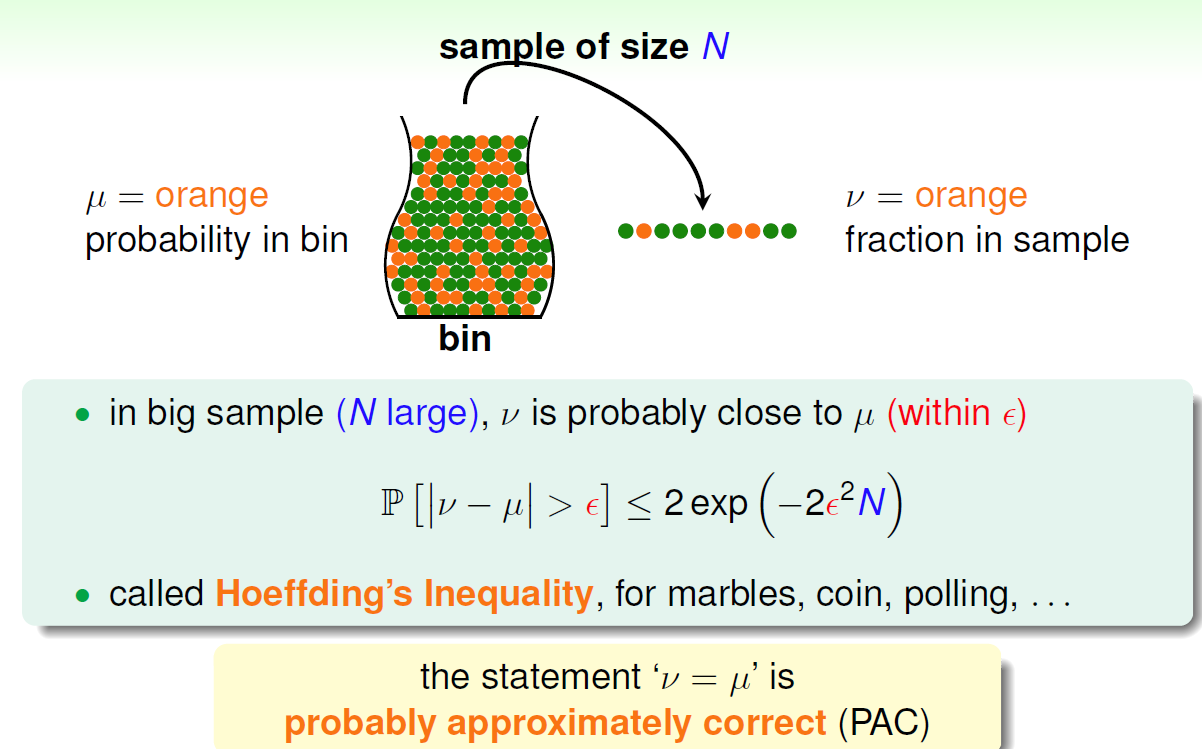
这里引出新的算法 PAC:可能近似正确(probably approximately correct,PAC)学习模型
学习器在学习目标函数时考虑可能假设的集合H。
在观察了一系列训练数据后,学习器需要从假设集合H中得到最终的假设g,这是对未知的符合D分布的理想模型f的估计。
最后,我们通过精心挑选出来的假设g对X中新的数据的性能来评估训练器。
学习过程如下图所示:
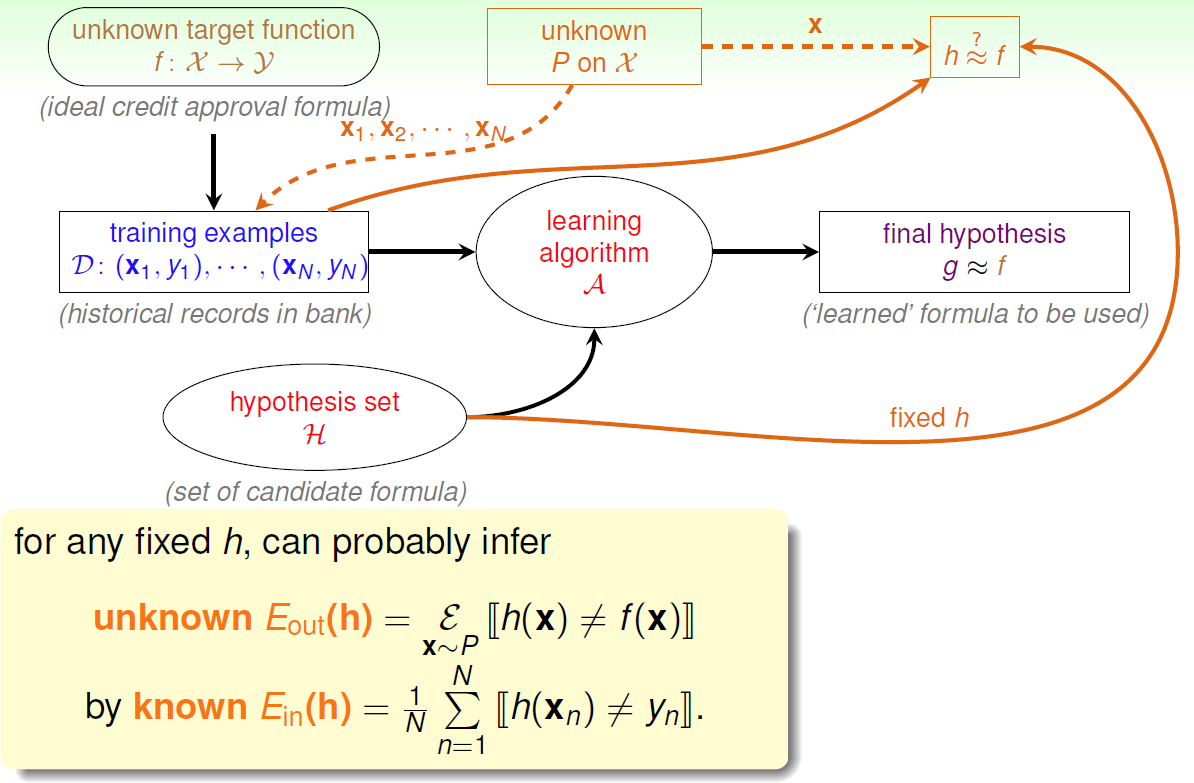
Eout用来描述h和f在整个罐子里一不一样,相当于μ,表示外部样本错误率,
Ein用来描述在资料上h和f的相似度,相当于v,表示资料样本错误率
f和P都是未知的
通过Ein推论出的Eout就是算法的目的,当Ein足够小的时候,Eout也是很小的 则h与f很接近(当资料继续从P产生)



以上是PAC 的算法思想……
posted on 2017-07-20 10:44 KID_XiaoYuan 阅读(614) 评论(0) 编辑 收藏 举报

