
Context-Aware Multi-View Summarization Network for Image-Text Matching
1 引入

对于上面展示的这一张图,从多种角度来说,可以有多种描述:关注细节的view1、关注地点的view2、忽略所有实体而表达抽象的view3。
所以,对于一张图,我们如何与相应的文本描述对应起来呢?
how to align an image to multiple textual descriptions with semantic diversity?
目前的所面对的困难:
- Multi-view description
There are a thousand Hamlets in a thousand people’s eyes - The heterogeneous gap
图像文本匹配需要同时全面理解复杂的视觉语义和各种文本信息。 但是,视觉和文本模态的不一致分布所导致的异质差距将极大地阻碍其实现。
所以,本文提出了一个context-aware multiview summarization network,从多个视图、总结上下文增强、的视觉区域信息
2 CAMERA模型
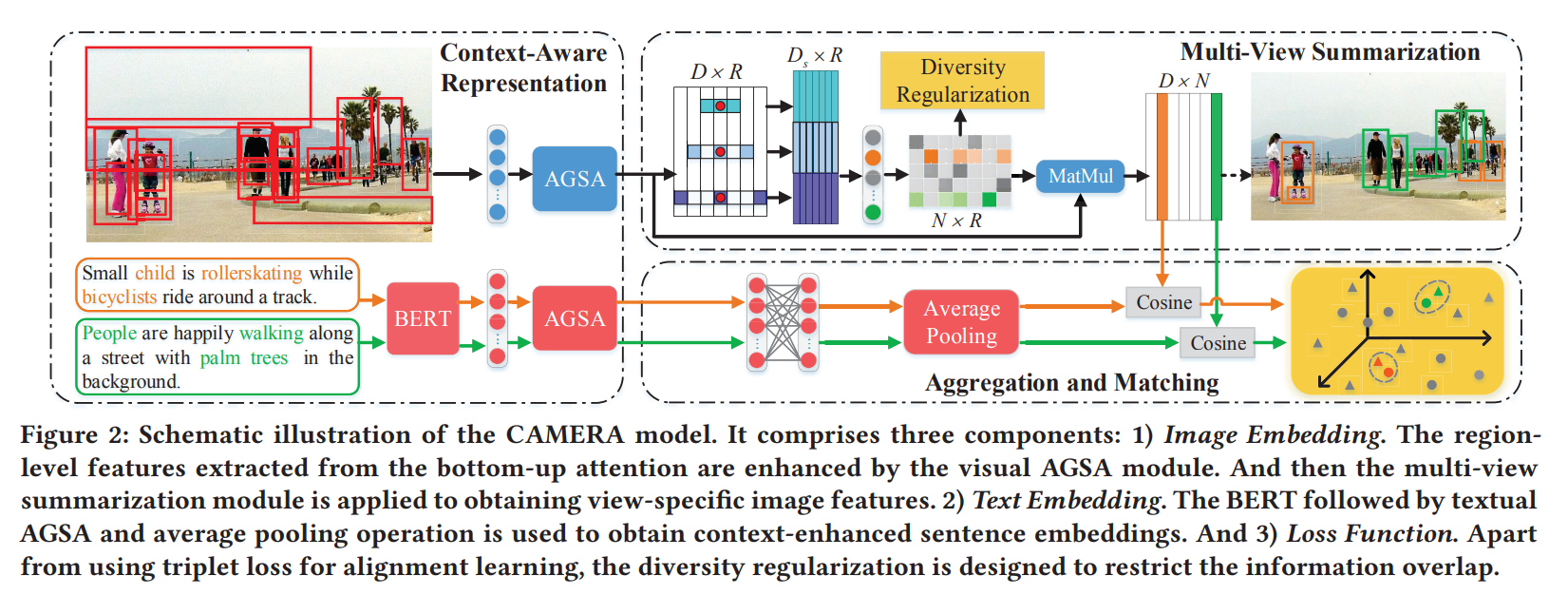
这个模型包含三个部分:the image embedding branch、the text embedding branch、the loss function。接下来我们逐一介绍。
2.1 Adaptive Gating Self-Attention(AGSA)
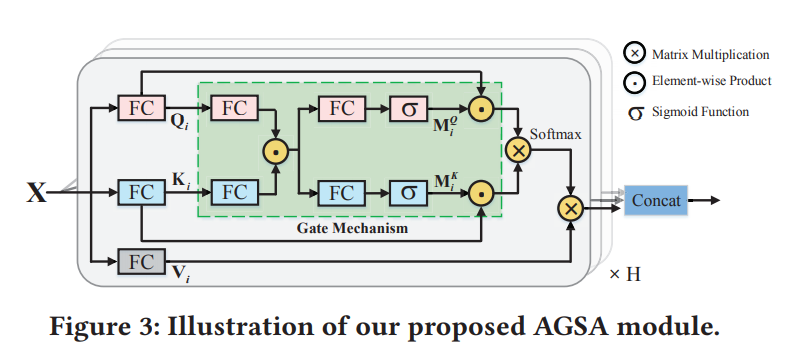
AGSA使我们能够获得输入信息的上下文增强表示,使我们能够加强对有利的信息的应用,忽略对我们来说无效的信息。
2.1.1 Gate Mechanism
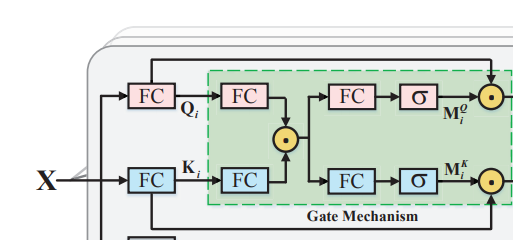
- fc1--对输入X进行处理
![]()
Q--query K--key V--value - fc2+内积
![]()
- fc3+sigmoid
![]()
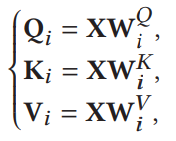

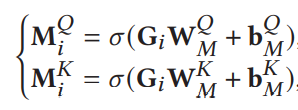
2.1.2 softmax
softmax生成一个概率,作为相应的权重,与相应的value相乘。

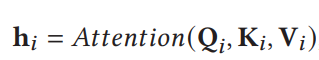
2.1.3 Multi-Head Self-Attention
为了进一步增强区分性表示,包含𝐻个并行自注意力机制的多头自注意力被设计为捕获来自不同子空间的上下文信息。
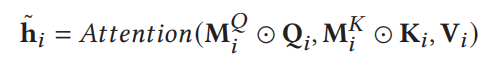
最后将H个结果叠加在一起,得到最终结果。
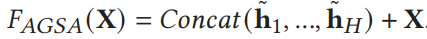
2.2 Image Embedding
2.2.1 Bottom-up Feature Extraction
- 对于给定的图像,首先选出置信度最高的前R(R=36)个ROI
- 采用平均池化,获得第i个区域的特征
![]() 和位置信息
和位置信息![]()
- 全连接层加强特征表示
![]()
- 为位置信息进行归一化处理,消除尺寸的影响
![]()
- 全连接层加强位置信息表示
![]()
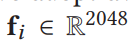 和位置信息
和位置信息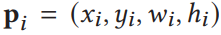
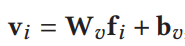
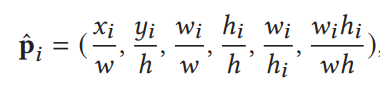
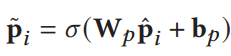
2.2.2 Context-aware Region Representation
- 引入AGSA模块捕获上下文信息
![]()
- 最终得到context-enhanced region feature matrix.
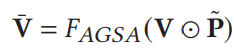
2.2.3 Multi-view Summarization
2.3 Text Embedding
- 利用BERT提取文本特征
![]()
- 全连接层增强特征表示
![]()
- 利用ASGA模块增强上下文信息特征表示
![]()
- multi-layer perceptron (MLP) followed by a residual connection
![]()
![]()
- 平均池化整合word特征信息变成sentence特征信息
![]()
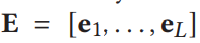
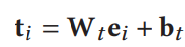
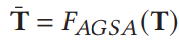
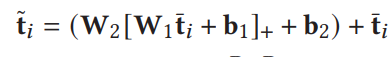
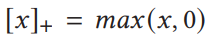
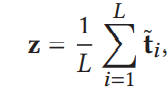
2.4 Loss Function
- Bidirectional Triplet Ranking Loss
![]()
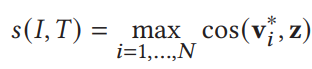
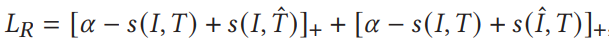
- Diversity Regularization
![]()
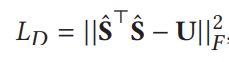
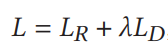
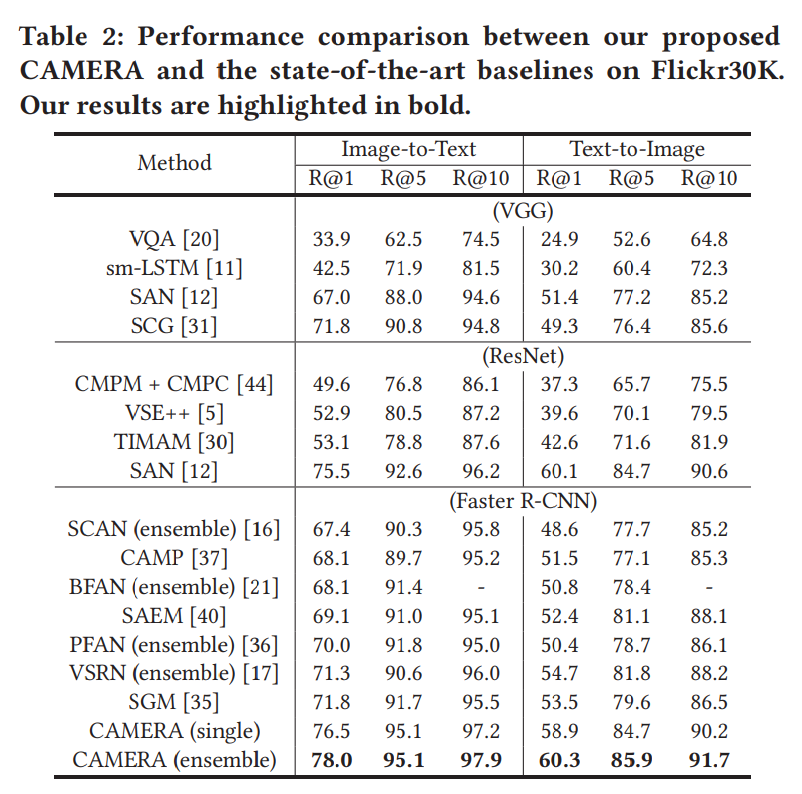
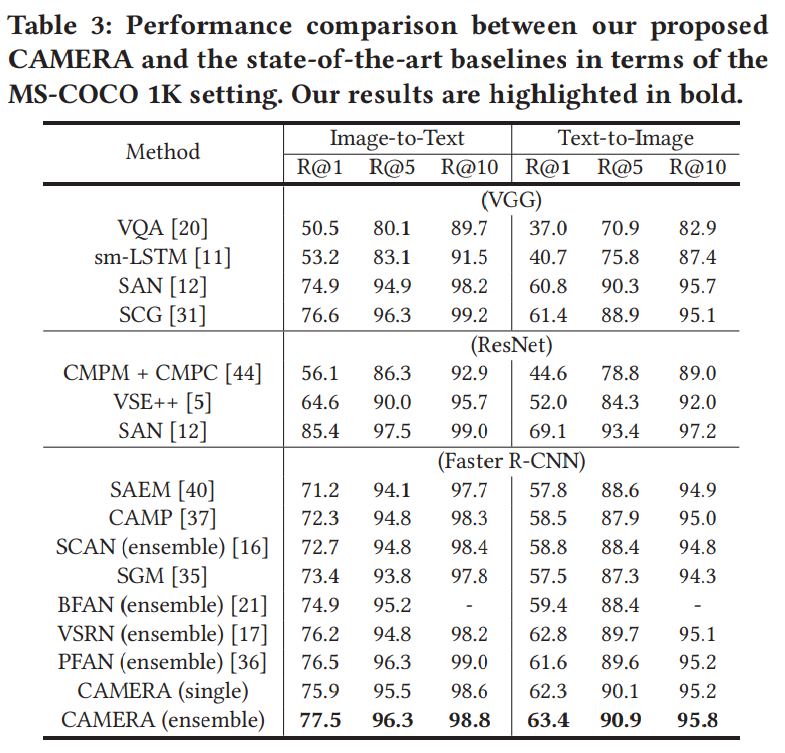
3 实验


 浙公网安备 33010602011771号
浙公网安备 33010602011771号