
第四周:卷积神经网络 part3
Part Ⅰ 代码练习
1 HybridSN 高光谱分类网络。
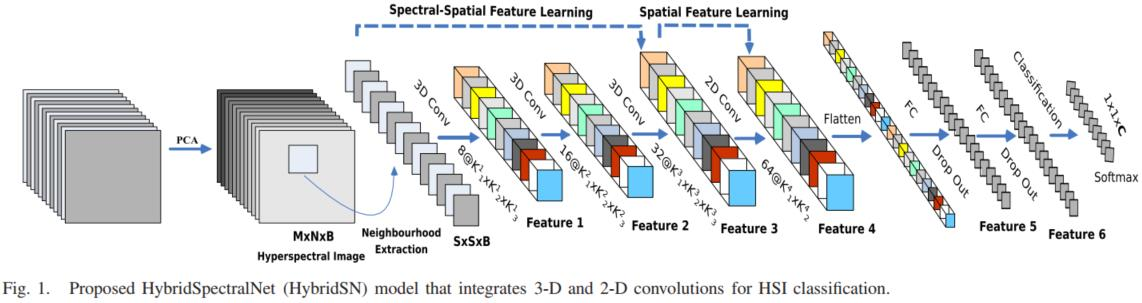
三维卷积部分:
- conv1:(1, 30, 25, 25), 8个 7x3x3 的卷积核 ==>(8, 24, 23, 23)
- conv2:(8, 24, 23, 23), 16个 5x3x3 的卷积核 ==>(16, 20, 21, 21)
- conv3:(16, 20, 21, 21),32个 3x3x3 的卷积核 ==>(32, 18, 19, 19)
接下来要进行二维卷积,因此把前面的 32*18 reshape 一下,得到 (576, 19, 19)
二维卷积:(576, 19, 19) 64个 3x3 的卷积核,得到 (64, 17, 17)
接下来是一个 flatten 操作,变为 18496 维的向量,
接下来依次为256,128节点的全连接层,都使用比例为0.4的 Dropout,
最后输出为 16 个节点,是最终的分类类别数。
下面是 HybridSN 类的代码:
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN,self).__init__()
self.conv3d1=nn.Conv3d(1,8,kernel_size=(7,3,3),stride=1,padding=0)
self.bn1=nn.BatchNorm3d(8)
self.conv3d2=nn.Conv3d(8,16,kernel_size=(5,3,3),stride=1,padding=0)
self.bn2=nn.BatchNorm3d(16)
self.conv3d3=nn.Conv3d(16,32,kernel_size=(3,3,3),stride=1,padding=0)
self.bn3=nn.BatchNorm3d(32)
self.conv2d1=nn.Conv2d(576,64,kernel_size=(3,3),stride=1,padding=0)
self.bn4=nn.BatchNorm2d(64)
self.fc1=nn.Linear(18496,256)
self.fc2=nn.Linear(256,128)
self.fc3=nn.Linear(128,16)
self.dropout=nn.Dropout(0.4)
def forward(self,x):
out=F.relu(self.bn1(self.conv3d1(x)))
out=F.relu(self.bn2(self.conv3d2(out)))
out=F.relu(self.bn3(self.conv3d3(out)))
out = F.relu(self.bn4(self.conv2d1(out.reshape(out.shape[0],-1,19,19))))
out = out.reshape(out.shape[0],-1)
out = F.relu(self.dropout(self.fc1(out)))
out = F.relu(self.dropout(self.fc2(out)))
out = self.fc3(out)
return out
2 SENet 实现
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN,self).__init__()
self.conv3d1=nn.Conv3d(1,8,kernel_size=(7,3,3),stride=1,padding=0)
self.bn1=nn.BatchNorm3d(8)
self.conv3d2=nn.Conv3d(8,16,kernel_size=(5,3,3),stride=1,padding=0)
self.bn2=nn.BatchNorm3d(16)
self.conv3d3=nn.Conv3d(16,32,kernel_size=(3,3,3),stride=1,padding=0)
self.bn3=nn.BatchNorm3d(32)
self.conv2d1=nn.Conv2d(576,64,kernel_size=(3,3),stride=1,padding=0)
self.bn4=nn.BatchNorm2d(64)
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d((1,1)),
nn.Conv2d(64,64//16,kernel_size=1),
nn.ReLU(),
nn.Conv2d(64//16,64,kernel_size=1),
nn.Sigmoid()
)
self.fc1=nn.Linear(18496,256)
self.fc2=nn.Linear(256,128)
self.fc3=nn.Linear(128,16)
self.dropout=nn.Dropout(0.4)
def forward(self,x):
out=F.relu(self.bn1(self.conv3d1(x)))
out=F.relu(self.bn2(self.conv3d2(out)))
out=F.relu(self.bn3(self.conv3d3(out)))
out=F.relu(self.bn4(self.conv2d1(out.reshape(out.shape[0],-1,19,19))))
w=self.se(out)
out=out*w
out = out.reshape(out.shape[0],-1)
out = F.relu(self.dropout(self.fc1(out)))
out = F.relu(self.dropout(self.fc2(out)))
out = self.fc3(out)
return out
Part Ⅱ 视频学习
1 《图像语义分割前沿进展》
1.1 Res2Net
1.1.1 背景
目前现有的特征提取方法大多都是用分层方式表示多尺度特征。分层方式即要么对每一层使用多个尺度的卷积核进行提特征(如SPPNet),要么就是对每一层提取特征进行融合(如FPN)。
本文提出的Res2Net在原有的残差单元结构中又增加了小的残差块,增加了每一层的感受野大小。Res2Net也可以嵌入到不同的特征提取网络中,如ResNet, ResNeXt, DLA等等。
1.1.2 Res2Net网络模型
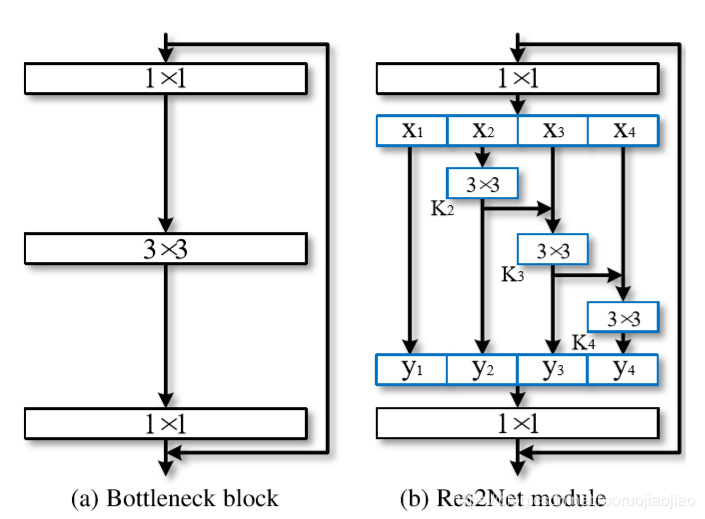
上图左边是最基本的卷积模块。右图是针对中间的3x3卷积进行的改进。
首先对经过1x1输出后的特征图按通道数均分为s(图中s=4)块,每一部分是xi,i ∈ {1,2,...,s}。
每一个xi都会具有相应的3x3卷积,由Ki()表示。我们用yi表示Ki()的输出。
特征子集xi与Ki-1()的输出相加,然后送入Ki()。为了在增加s的同时减少参数,我们省略了x1的3×3卷积,这样也可以看做是对特征的重复利用。
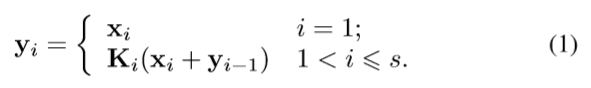
(代表卷积操作)
y1 = x1;
y2 = x2(3x3)= K2;
y3 =(x3 + x2(3x3))(3x3) = (K2 + x3)(3x3)= K3 ;
y4 =(x4 +(x3 + x2(3x3))(3x3))(3x3) = (K3 + x4)*(3x3)= K4
如此一来,我们将得到不同数量以及不同感受野大小的输出。 比如y2得到3x3的感受野,那么y3就得到5x5的感受野,y4同样会得到更大尺寸如7x7的感受野。
最后将这四个输出进行融合并经过一个1x1的卷积。这种先拆分后融合的策略能够使卷积可以更高效的处理特征。
在本文中,我们将s设置为比例尺寸的控制参数,也就是可以将输入通道数平均等分为多个特征通道。s越大表明多尺度能力越强,此外一些额外的计算开销也可以忽略。
1.2 Strip Pooling
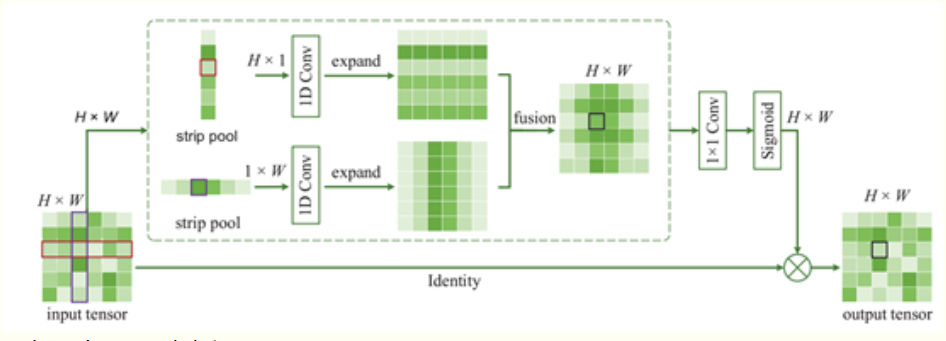
- 如下图所示,使用Hx1和1xW尺寸的条状池化核进行操作,对池化核内的元素值求平均,并以该值作为池化输出值。
- Hx1和1xW池化核处理后,使用1D Conv对两个输出feature map分别沿着左右和上下进行扩容,如下图所示,扩容后两个feature map尺寸相同,进行fusion(element-wise上的add)。
- 采用element-wise multiplication的方式对原始数据和sigmoid处理后的结果进行处理,至此,strip pooling完成,输出结果。
1.3 Learning Dynamic Routing for Semantic Segmentation
1.3.1 背景
这篇文章提出的方法主要是想解决在语义分割任务中目标大小不一的问题;在语义分割中,分割的目标可能是小到一只鸟,也可能大到是充斥整个画面的大巴车或者背景;而一般的方法都是使用单一的静态网络模型进行分割,可能缺少对于真实世界中不同大小的目标的调节能力。
本文提出的方法是一种动态路径的方法,依据数据的不同规划不同的路径,也就是具体的网络结构会随着输入而变化
1.3.2 工作机制

图中给出了不同尺度的动态路径规划;红色线标注的是他们的不同:
* 大尺度的图可能会忽略一些低层的特征;
* 而小尺度的目标可能会同时依靠低层特征与高层特征;
* 对于混合尺度的输入则会有连接模式。
1.3.3 原理
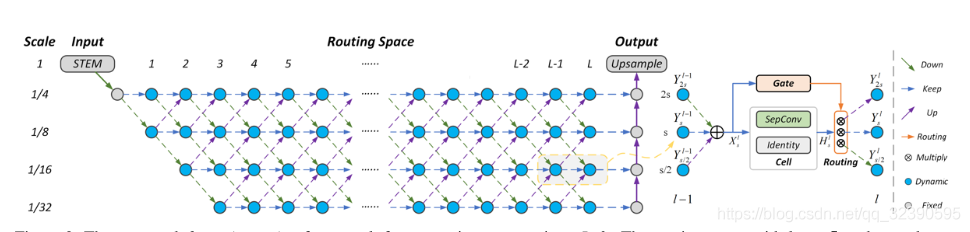
图中一共有L个layer,可以看到对于每个layer最多有四种scale的feature map,最小的1/32scale。首先input进行一个固定的三层的STEM把分辨率降至1/4。为了实现各层之间的全连接,会有上采样、下采样、保持scale的三种操作;右边是cell-level的展示,被聚合的特征经过Gate与Cell结构进行特征转换。
- Stem Block:包含三个网络层(SepConv3x3),负责1/4降采样;
- Routing Space:
* 包含L个网络层,每层包含若干个cell,支持skip connection与multi-path routes;
* 相邻cell之间,降采样率或上采样率=2;
* 相比于输入,降采样率最高可达32,因此每个layer的cell数最多为4;
* 每个cell的输出,存在三条尺度变换路径:up-sampling(conv1x1+bilinear interpolation)、down-sampling(conv1x1 with stride=2)、keeping resolution
* 在cell内部,会执行特征变换/聚合(feature aggregation)、与尺度变换路径选择操作;
1.4 Spatial Pyramid Based Graph Reasoning for Semantic Segmentation(to be continue)
将每个pixel视为node,利用CNN提取 node的feature vector,然后用spatial pyramid的GCN做信息交换和分类,提出了新的相似矩阵和拉普拉斯矩阵
1.5 BlendMask Top-Down Meets Bottom-up for Instance Segmentation
BlendMask是一阶段的密集实例分割方法,结合了Top-down和Bottom-up的方法的思路。它通过在anchor-free检测模型FCOS的基础上增加了Bottom Module提取low-level的细节特征,并在instance-level上预测一个attention;借鉴FCIS和YOLACT的融合方法,作者提出了Blender模块来更好地融合这两种特征。
1.5.1 背景
本文主要讨论的是密集实例分割( Dense instance segmentation),密集实例分割也同样有top-down和bottom-up两类方法。
- top-down:自上而下的密集实例分割的开山鼻祖是DeepMask,它通过滑动窗口的方法,在每个空间区域上都预测一个mask proposal。这个方法存在以下三个缺点:mask与特征的联系(局部一致性)丢失了,如DeepMask中使用全连接网络去提取mask;特征的提取表示是冗余的, 如DeepMask对每个前景特征都会去提取一次mask;下采样(使用步长大于1的卷积)导致的位置信息丢失。
- bottom-up:自下而上的密集实例分割方法的一般套路是,通过生成per-pixel的embedding特征,再使用聚类和图论等后处理方法对其进行分组归类。这种方法虽然保持了更好的低层特征(细节信息和位置信息),但也存在以下缺点:对密集分割的质量要求很高,会导致非最优的分割、泛化能力较差,无法应对类别多的复杂场景、后处理方法繁琐。
- 混合方法:本文想要结合 top-down和bottom-up两种思路,利用top-down方法生成的instance-level的高维信息(如bbox),对bottom-up方法生成的 per-pixel prediction进行融合。因此,本文基于FCOS提出简洁的算法网络BlendMask。融合的方法借鉴FCIS(裁剪)和YOLACT(权重加法)的思想,提出一种Blender模块,能够更好地融合包含instance-level的全局性信息和提供细节和位置信息的低层特征。
1.5.2 总体思路
BlendMask的整体架构如下图所示,包含一个detector module和BlendMask module。文中的detector module直接用的FCOS,BlendMask模块则由三部分组成:bottom module用来对底层特征进行处理,生成的score map称为Base;top layer串接在检测器的box head上,生成Base对应的top level attention;最后是blender来对Base和attention进行融合。

1.5.3 BlendMask(to be continue)
- Bottom Module
- Top Layer
- Blender
1.6 IMRAM Iterative Matching With Recurrent Attention Memory for Cross-Modal Image-Text Retrieval
IMRAM方法总体上分为三步:1)分别提取图像和文本的原始特征;2)用RAM模块探索二者之间细粒度上的对齐关系;3)相似性度量以及损失函数迭代优化。
1.6.1 得到跨模态特征表示
-
对于图像
- 用一个经过预训练的CNN网络来提取特征。给一张图像I,CNN识别出几个包含语义信息的区域r,并提取出每一个区域对应的特征f,最后把特征变成维度一致的向量v
![]() W和b都是要学习的参数。
W和b都是要学习的参数。
-
对于文本
为了得到图像和文本之间细粒度的对应关系,文章采用双向GRU作为编码器对文本进行编码,得到单词级别的特征。- 每一个单词w用一个邻接嵌入向量e表示:
![]()
- 然后用双向GRU对语义信息进行提取:
![]()
- 最后的文本特征用t表示:
![]()
- 每一个单词w用一个邻接嵌入向量e表示:
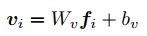 W和b都是要学习的参数。
W和b都是要学习的参数。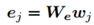
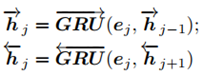
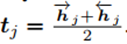
1.6.2 用RAM(recurrent attention memory)进行对齐
一共用到了3个RAM模块,每一个RAM都包含一个CAU和一个MDU。
- CAU(cross-modal attention unit)
对于query集X和response集Y,CAU的作用是计算每一个x和y之间的相似度,并得到基于x的alignment feature。 - MDU(memory distillation unit)
完整框架中一共用了三次RAM,目的是为了对文本和图像进行多次对齐。为了在下一次对齐过程中得到更好的结果,那么就需要在每一次对齐之后再反过来对query features X进行优化。
1.6.3 迭代匹配和损失函数优化
设置迭代次数为k,那么每一步中,一张图像I和一个文本S的匹配分数定义为:
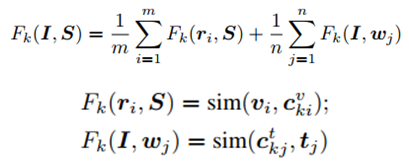
其中sim函数表示相似性度量函数,和前面用过的一样。
最后,I和S的匹配分数为:
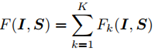
参考自https://blog.csdn.net/weixin_44390691/article/details/105177911
1.7 Cross-modality Person re-identification with Shared-Specific Feature
1.7.1 引言
cm-ReID的挑战在于模态间的差异。目前大家的方法往往更加关注于学习公共的特征表示,利用一个相同的特征空间嵌入不同的模态。然而,只关注公共特征,势必造成整体的信息损失,从而影响性能。于此文之中,作者为解决上述局限,提出了一个cross modality shared-specific feature transfer algorithm(也唤作cm-SSFT),以来发掘两模态间共有特征和独有特征间的潜在信息,用来提升整体性能。
1.7.2 网络框架
输入图像首先被输入到two-stream特征提取器中,以获得共享的和特定的特征。然后使用shared-specific transfer network (SSTN)模型来确定模态内和模态间的相似性。然后在不同的模态间传播共享和特定特征,以弥补缺乏的特定信息并增强共享特征。在特征提取器上增加了两个项目对抗重建块(project adversarial and reconstruction blocks)和一个模式适应模块(modality- adaptation module),以获得区别性、互补性的共享特征和特定特征。
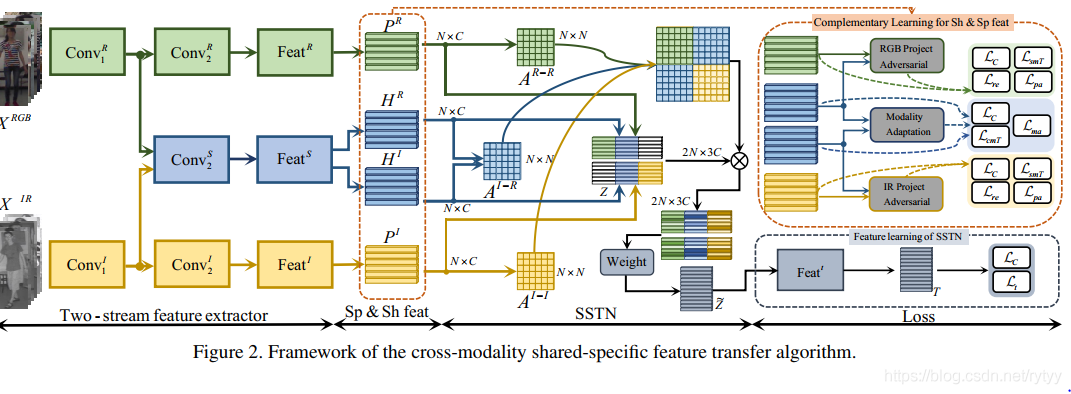
参考自https://blog.csdn.net/rytyy/article/details/105318745
1.8 Universal Weighting Metirc Learning for Cross-Modal Matching
1.9 Cross-Domain Corresponence Learning for Exemplar-Based Image Translation
1.9.1 概要
本文研究的问题是基于语义图像和风格参考图像的图像转换问题。
本文提出的模型先将输入语义图像和输入参考风格图像分别通过编码器进行领域对齐,并使用特征计算两者每个像素点之间的相似度,并根据该相似度得到变形的参考图像,再将其使用positional normalization和spatially-variant denormalizaiton(类似于AdaIN)的方法,在从固定噪声生成最终图像的过程中将该风格注入图像。
损失函数由伪参考图像对损失、领域对齐损失、语义约束损失、风格约束损失、相似度矩阵正则化和生成对抗损失组成。
1.9.2 模型结构

先将输入语义图像和输入参考风格图像分别通过编码器进行领域对齐,并使用该计算两者每个像素点之间的相似度,并根据该相似度得到变形的参考图像,再将其使用类似于AdaIN的方法,在从固定噪声生成最终图像的过程中将该风格注入图像。
参考https://blog.csdn.net/huitailangyz/article/details/105884294
2 《语义分割中的自注意力机制和低秩重建》
参考自https://zhuanlan.zhihu.com/p/77834369
2.1 语义分割
在一幅图像中,给每个像素打个标签。

2.2 自注意力机制
注意力机制模仿了生物观察行为的内部过程,即一种将内部经验和外部感觉对齐从而增加部分区域的观察精细度的机制。
而自注意力机制是注意力机制的改进,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号