CFG 和 DFA 的交集为 CFG
起因是我队友问了我一个问题:
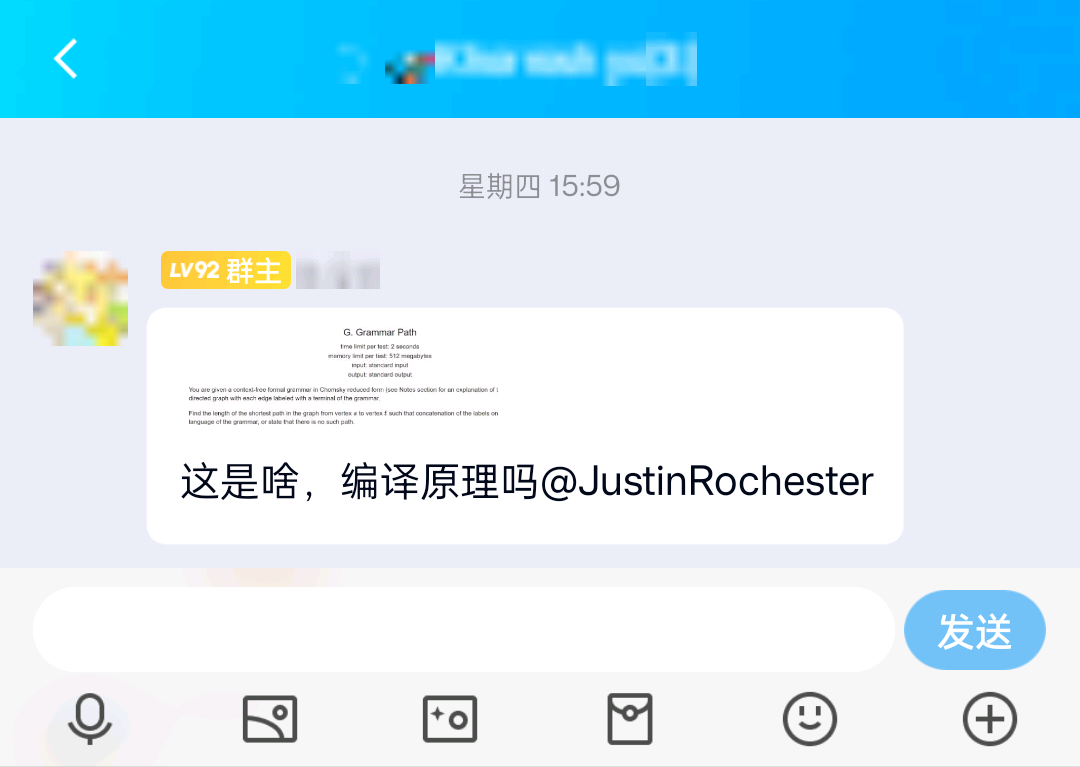
我后面看了一下那题,等价的题意是求一个 CFG 和 DFA 交集,能识别的最短串的长度。
虽然编译原理没学过,但是我在可计算理论上有学到过:有个结论是,CFG 和 DFA 的交集也是 CFG ;而 CFG 推导出的最短串可以用队列+贪心的方法求解。但并没有学过如何对于给定的 CFG 和 DFA,求出交集的 CFG。
我在国内某搜索引擎上并没有找到答案,最终在外网找到了一个比较靠谱的 文献 。所以我这篇笔记就是记录一下这个算法的流程。
定义
DFA
我们称一个确定型有穷状态自动机(Deterministic Finite Automaton, DFA)是一个五元组 \(\left<Q, \Sigma, \delta, q_0, F\right>\) ,其中五个参数依次为状态集、字符集、转移函数(\(\delta: Q\times \Sigma\to Q\))、起始状态和接收状态集。
在 DFA 的计算过程中,我们从初始状态 \(q_0\) 出发,不断读入字符 \(c\in \Sigma\) ,并通过转移函数 \(\delta(q_i, c)=q_{i+1}\) 不断更新状态。当读入完成后,若状态 \(q_e\in F\) 则接受该读入,否则拒绝该读入。
对于一个 DFA \(M\) ,我们称所有能被 \(M\) 识别的字符串为 \(M\) 的语言 \(L(M)\) ,即 \(L(M)=\{s|\delta(q_0, s)\in F\}\) 。
这里我们拓展了转移函数的意义:当字符串 \(s\) 的长度大于 \(1\) 时,我们将其划分为最后的字符 \(c\) 和前缀 \(t\) ,我们定义 \(\delta(q,s)=\delta(\delta(q, t), c)\) 。
CFG
我们称一个上下文无关文法(Context-Free Grammer, CFG)是一个四元组 \(\left<V, \Sigma, R, S\right>\) ,其中五个参数依次为变元集、终结符集、产生式规则(\(R: V\to (V\cup \Sigma)^*\))和起始变元。
其中,为了方便描述,产生式规则往往采用 A->BCdefG 的形式描述。其中产生式规则的左侧必须为变元。
在一个 CFG \(G\) 的计算过程中,我们从初始变元 \(S\) 出发,不断地选择当前串中的一个变元 \(A\) ,然后选择一个左侧为 \(A\) 的产生式规则进行替换:将 \(A\) 修改成产生式规则的右侧的串。
当我们将串推导成只含终结符的串 \(s\) 时,我们称该 CFG 接受串 \(s\) ,同理可定义语言 \(L(G)=\{s|S\Rightarrow^+ s\wedge (\forall c\in s\to c\in \Sigma)\}\) 。
其中 \(\Rightarrow\) 符号表示推导,即上述使用产生式规则的一次替换过程;而 \(\Rightarrow^+\) 符号表示若干正整数次的推导。
CNF
我们称一个 CFG 满足乔姆斯基范式(Chomsky Normal Form, CNF)指该 CFG 的产生式规则仅含有以下三种形式的产生式规则:
- 由起始变元推导出空串:\(S\to \varepsilon\)
- 由一个变元推导出两个变元:\(A\to BC\)
- 由一个变元推导出一个终结符:\(A\to a\)
很显然,对于任何一个 CFG \(G\) ,必然存在 CNF \(G'\) 使得 \(L(G')=L(G)\)
CFG 可以模拟 DFA 的计算
我们常说 DFA 的描述能力是 CFG 描述能力的一个子集。即对于所有 DFA 语言构成的集合 \(S_1\) 和所有 CFG 语言构成的集合 \(S_2\) 必然有 \(S_1\subset S_2\) 。
经典的证明方法
一个比较经典的证明方法是,我们可以通过广义非确定型有穷状态自动机(Generalized Nondeterministic Finite Automaton, GNFA)将一个 DFA 转化成等价的正则语言 \(R\) 。
而我们众所周知:
- 空语言为正则语言。
- \(c\) 为正则语言(\(c\in \Sigma\))。
- \(\varepsilon\) 为正则语言。
- 若 \(R_1, R_2\) 为正则语言,则 \(R_1R_2\) 为正则语言。
- 若 \(R_1, R_2\) 为正则语言,则 \(R_1\cup R_2\) 为正则语言
- 若 \(R\) 为正则语言,则 \((R)\) 为正则语言。
- 若 \(R\) 为正则语言,则 \(R^*\) 为正则语言。
于是我们可以对于该正则语言 \(R\) 构造对应的 CFG:
- 若 \(L(R)=\varnothing\) 则产生式规则集合为 \(\varnothing\) 。
- 若 \(L(R)=\{c\}, c\in \Sigma\) 则产生式规则集合为 \(\{S\to c\}\) 。
- 若 \(L(R)=\{\varepsilon\}\) 则产生式规则集合为 \(\{S\to \varepsilon\}\) 。
- 若 \(R=R_1R_2\) 则分别构造 \(S_1, S_2\) 能表示 \(R_1, R_2\) ,然后添加产生式 \(S\to S_1 S_2\) 。
- 若 \(R=R_1\cup R_2\) 则分别构造 \(S_1, S_2\) 能表示 \(R_1, R_2\) ,然后添加产生式 \(S\to S_1\) 和 \(S\to S_2\)。
- 若 \(R=(R_1)\) 则构造 \(S_1\) 表示 \(R_1\) ,然后添加产生式 \(S\to S_1\) 。
- 若 \(R=R_1^*\) 则构造 \(S_1\) 表示 \(R_1\) ,然后添加产生式 \(S\to S_1S\) 和 \(S\to \varepsilon\) 。
很显然,两者描述的是同一种语言。
比较特别的证明方法
但在那篇文献的思想里,其实我们有一种不通过正则语言中转的方法直接证明两者的能力关系:
当 DFA \(M=\left<Q, \Sigma, \delta, q_0, F\right>\) 的接受状态集 \(F\) 是大小为 \(1\) 的集合 \(\{f\}\) 时,我们按如下方法构造一个 CFG \(G=\left<V, \Sigma, R, S\right>\) :
首先,DFA 的字符集和 CFG 的终结符集是同一个集合,而变元集 \(V\) 我们定义为 \(Q\times Q\cup \{S\}\) ,起始变元为 \(S\) ,产生式规则定义如下:
- \(\forall x, y, z\in Q\) ,向 \(R\) 中添加规则 \(\left<x,y\right>\to \left<x,z\right> \left<z,y\right>\) 。
- \(\forall x\in Q, c\in \Sigma\) ,向 \(R\) 中添加规则 \(\left<x, \delta(x, c)\right>\to c\) 。
- \(\forall x\in Q\) ,向 \(R\) 中添加规则 \(\left<x,x\right>\to \varepsilon\) 。
- 向 \(R\) 中添加规则 \(S\to \left<q_0, f\right>\) 。
这看起来很奇怪,但实际上它描述的语言也和 \(M\) 等价。一个比较好的理解方法是:变元 \(\left<u,v\right>\) 描述的是状态 \(u\) 读入一些字符串后会转移到 \(v\) 状态,而该变元能推导出所有满足这条件的字符串。
而对于多接受状态的 DFA \(M\) ,一个方法是将其拆解为多个单接收状态的 DFA,分别产生上述的 \(S_1, S_2, S_3, \cdots\) 后,再通过引入 \(S\to S_1, S\to S_2, S\to S_3, \cdots\) 进行合并。
另一个更为简便的方法是,直接修改最后一个规则为:\(\forall f\in F\) ,向 \(R\) 中添加规则 \(S\to \left<q_0, f\right>\) 。
CFG 和 DFA 的交集为 CFG
经过这个比较特别的证明方法后,这一步的理解会变得更为简单。我们同样是考虑一个 DFA \(M=\left<Q, \Sigma, \delta, q_0, F\right>\) 和一个 CFG \(G_0=\left<V_0, \Sigma, R_0, S_0\right>\) 。这里,我们直接假设 \(G_0\) 的一个 CNF,若不满足,可以进行转化。
同样的,当 DFA 的接受状态集 \(F\) 是大小为 \(1\) 的集合 \(\{f\}\) 时,我们按如下方法构造一个 CFG \(G=\left<V, \Sigma, R, S\right>\) :
首先,\(M\) 的字符集和 \(G, G_0\) 的终结符集仍是同一个集合,而变元集 \(V\) 我们定义为 \(Q\times V_0\times Q\cup \{S\}\) ,起始变元为 \(S\) ,产生式规则定义如下:
- 对于 \(G_0\) 的一个产生式规则 \(A\to BC\) ,我们对 \(\forall x, y, z\in Q\) ,向 \(R\) 中添加规则 \(\left<x,A,y\right>\to \left<x,B,z\right> \left<z,C,y\right>\) 。
- 对于 \(G_0\) 的一个产生式规则 \(A\to c,c\in \Sigma\) ,我们对 \(\forall x\in Q\) ,向 \(R\) 中添加规则 \(\left<x, A, \delta(x, c)\right>\to c\) 。
- 若 \(G_0\) 存在产生式规则 \(S_0\to \varepsilon\) 且 \(q_0\in F\) ,则向 \(R\) 中添加规则 \(\left<q_0, S_0, q_0\right>\to \varepsilon\) 。
- 向 \(R\) 中添加规则 \(S\to \left<q_0, S_0, f\right>\) 。
参考上述的理解方法,变元 \(\left<u,A,v\right>\) 描述的其实是从状态 \(u\) 出发,读入了一些能规约成 \(A\) 变元的字符串,转移到 \(v\) 状态,这个变元能推导出所有满足该条件的字符串。
从该理解角度,证明的正确性十分显然。
最后,对于多接收状态的 DFA,可以像上文方法直接进行拆解后,通过引入新产生式进行合并;也可以类似上述方法,直接修改最后一个规则为:\(\forall f\in F\) ,向 \(R\) 中添加规则 \(S\to \left<q_0, S_0, f\right>\) 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号