
Kaggle & Machine Learning
step1: KNN
识别率93%,很低,继续……


1 #include <iostream> 2 #include <string> 3 4 using namespace std; 5 6 int ans[15000]; 7 int label[42010]; 8 int matrix[42010][800]; 9 int test[26000][800]; 10 int m, n; 11 int MAXN = 784; 12 int vis[10]; 13 14 typedef struct node 15 { 16 int val, cla; 17 }node; 18 node nd[42010]; 19 20 int cmp(const void* a, const void* b) 21 { 22 return ((node*)a)->val - ((node*)b)->val; 23 } 24 25 int knn(int k, int idx) 26 { 27 printf("Dealing %d\n", idx); 28 int cnt = 0; 29 for (int i = 0; i < m; ++i) 30 { 31 cnt = 0; 32 for (int j = 0; j < MAXN; ++j) 33 { 34 if (matrix[i][j] != test[idx][j]) cnt++; 35 } 36 nd[i].val = cnt, nd[i].cla = label[i]; 37 } 38 qsort(nd, m, sizeof(node), cmp); 39 for (int i = 0; i < k; ++i) 40 vis[nd[i].cla]++; 41 int mx = 0, ret = 0; 42 for (int i = 0; i < 10; ++i) 43 { 44 if (vis[i] > mx) mx = vis[i], ret = i; 45 vis[i] = 0; 46 } 47 return ret; 48 } 49 50 int main() 51 { 52 /* 53 int i = 0; 54 FILE *fp; 55 fp = freopen("E:\\Kaggle\\Digit Recognizer\\train.csv", "r", stdin); 56 while (~scanf("%d", &label[i])) 57 { 58 for (int j = 0; j < 784; ++j) 59 { 60 scanf(",%d", &matrix[i][j]); 61 if (matrix[i][j] != 0) matrix[i][j] = 1; 62 } 63 i++; 64 } 65 printf("Hello\n"); 66 m = i; 67 fclose(fp); 68 FILE* fp1; 69 fp1 = freopen("E:\\Kaggle\\Digit Recognizer\\test1.csv", "r", stdin); 70 i = 0; 71 while (~scanf("%d", &test[i][0])) 72 { 73 for (int j = 1; j < 784; ++j) 74 { 75 scanf(",%d", &test[i][j]); 76 if (test[i][j] != 0) test[i][j] = 1; 77 } 78 i++; 79 } 80 printf("Hello\n"); 81 fclose(fp1); 82 n = i; 83 FILE *out1; 84 out1 = fopen("E:\\Kaggle\\Digit Recognizer\\ans1.txt", "w+"); 85 for (int j = 0; j < n; ++j) 86 fprintf(out1, "%d\n", knn(100, j)); 87 fclose(out1); 88 */ 89 FILE *out1; 90 out1 = freopen("E:\\Kaggle\\Digit Recognizer\\ans1.txt", "r", stdin); 91 FILE *ot; 92 ot = fopen("E:\\Kaggle\\Digit Recognizer\\ans2.txt", "w+"); 93 int i = 1; 94 int val; 95 while (~scanf("%d", &val)) 96 { 97 fprintf(ot, "%d,%d\n", i, val); 98 i++; 99 } 100 fclose(ot); 101 fclose(out1); 102 103 return 0; 104 }
step2:logistic回归
跑了一下下,电脑有点慢
1 from numpy import * 2 import matplotlib.pyplot as plt 3 import csv 4 5 def toInt(array): 6 array=mat(array) 7 m,n=shape(array) 8 newArray=zeros((m,n)) 9 for i in range(m): 10 for j in range(n): 11 newArray[i,j]=int(array[i,j]) 12 return newArray 13 14 def nomalizing(array): 15 m,n=shape(array) 16 for i in range(m): 17 for j in range(n): 18 if array[i,j]!=0: 19 array[i,j]=1 20 return array 21 22 def dealLabel(labelMat, k): 23 labelMat = mat(labelMat) 24 m, n = shape(labelMat) 25 newLabel = zeros((m, n)) 26 for i in range(m): 27 for j in range(n): 28 if labelMat[i, j] == k: 29 newLabel[i, j] = 1 30 else: 31 newLabel[i, j] = 0 32 return newLabel 33 34 def loadDataSet(): 35 dataMat = []; labelMat = [] 36 l = [] 37 with open('F:\\Kaggle\\Digit Recognize\\train1.csv') as file: 38 lines = csv.reader(file) 39 for line in lines: 40 l.append(line) 41 l = array(l) 42 labelMat = l[:, 0] 43 dataMat = l[:, 1:] 44 return nomalizing(toInt(dataMat)), toInt(labelMat) 45 46 def loadTestData(): 47 dataMat = [] 48 with open('F:\\Kaggle\\Digit Recognize\\test1.csv') as file: 49 lines = csv.reader(file) 50 for line in lines: 51 dataMat.append(line) 52 dataMat = array(dataMat) 53 return nomalizing(toInt(dataMat)) 54 55 def sigmoid(inX): 56 return 1.0/(1+exp(-inX)) 57 58 def gradAscent(dataArray, labelArray): 59 dataMat = mat(dataArray); labelMat = mat(labelArray) 60 m, n = shape(dataArray) 61 alpha = 0.001 62 maxCycles = 500 63 weights = ones((n, 1)) 64 for k in range(maxCycles): 65 h = sigmoid(dataMat*weights) 66 error = (labelMat - h) 67 weights = weights + alpha*dataMat.transpose()*error 68 return weights 69 70 def judge(testMat, weights): 71 testMat = mat(testMat); weights = mat(weights) 72 ans = sigmoid(testMat*weights) 73 m, n = shape(testMat) 74 return ans 75 76 dataMat, labelMat = loadDataSet() 77 newlabelMat = dealLabel(labelMat, 1) 78 newlabelMat = newlabelMat.transpose() 79 #print(newlabelMat) 80 weights = gradAscent(dataMat, newlabelMat) 81 print(shape(weights)) 82 testMat = loadTestData() 83 ans = judge(testMat, weights) 84 #print(ans) 85 86 m, n = shape(ans) 87 for i in range(m): 88 for j in range(n): 89 if ans[i, j] < 0.5: 90 print(0) 91 else: 92 print(1)
Titanic: Machine Learning from Disaster
step1: CART
直接建的CART树,score为0.76
1 from numpy import * 2 import csv 3 4 class Node(object): 5 def __init__(self, lt = None, rt = None, s = None, ky = -1, ps = -1): 6 self.left = lt 7 self.right = rt 8 self.data = s 9 self.key = ky 10 self.pos = ps 11 12 def toInt(matrix): 13 matrix = mat(matrix) 14 m, n = shape(matrix) 15 newMat = ones((m, n)) 16 for i in range(m): 17 for j in range(n): 18 newMat[i, j] = int(matrix[i, j]) 19 return newMat 20 21 def loadTrainSet(f): 22 dataMat = []; labelMat = [] 23 l = [] 24 with open(f) as file: 25 lines = csv.reader(file) 26 for line in lines: 27 l.append(line) 28 l.remove(l[0]) 29 l = array(l) 30 labelMat = l[:, 1] 31 dataMat = l[:, 2:] 32 labelMat = mat(labelMat) 33 dataMat = mat(dataMat) 34 return dataMat, toInt(labelMat) 35 36 def loadTestSet(f): 37 dataMat = []; 38 l = [] 39 with open(f) as file: 40 lines = csv.reader(file) 41 for line in lines: 42 l.append(line) 43 l.remove(l[0]) 44 l = array(l) 45 dataMat = l[:, 1:] 46 dataMat = mat(dataMat) 47 return dataMat 48 49 def calGINI(dataMat, labelMat, k): 50 # print(dataMat) 51 # print(labelMat) 52 dataMat = mat(dataMat) 53 labelMat = mat(labelMat) 54 m, n = shape(dataMat) 55 dct = {} 56 for i in range(m): 57 if dataMat[i, k] in dct: 58 dct[dataMat[i, k]] += 1 59 else: 60 dct[dataMat[i, k]] = int(1) 61 ginidict = {} 62 mingini = float(1000000000); minele = '' 63 for (p, v) in dct.items(): 64 cnt0 = float(0); cnt1 = float(0) 65 cn0 = float(0); cn1 = float(0) 66 for j in range(m): 67 if dataMat[j, k] == p: 68 if labelMat[j, 0] == 0: 69 cnt0 += 1.0 70 else: 71 cnt1 += 1.0 72 else: 73 if labelMat[j, 0] == 0: 74 cn0 += 1.0 75 else: 76 cn1 += 1.0 77 g1 = 0; g2 = 0 78 if cnt0+cnt1 != 0: 79 g1 = float(v)/m*(2*cnt0/(cnt0+cnt1)*cnt1/(cnt0+cnt1)) 80 if cn0+cn1 != 0: 81 g2 = float(m-v)/m*(2*cn0/(cn0+cn1)*cn1/(cn0+cn1)) 82 gini = g1+g2 83 ginidict[p] = gini 84 return ginidict 85 86 def CART(dataMat, labelMat): 87 dataMat = mat(dataMat); labelMat = mat(labelMat) 88 if (shape(labelMat)[1]) != 1: 89 labelMat = transpose(labelMat) 90 ansidx = -1; mingini = 1000000000; minele = '' 91 m, n = shape(dataMat) 92 for i in range(n): 93 retgini = calGINI(dataMat, labelMat, i) 94 for (p, v) in retgini.items(): 95 if v < mingini: 96 mingini = v 97 ansidx = i 98 minele = p 99 node = Node() 100 node.data = minele 101 node.pos = ansidx 102 dataLeft = []; dataRight = []; 103 labelLeft = []; labelRight = []; 104 for i in range(m): 105 temp = [] 106 for j in range(n): 107 if j != ansidx: 108 temp.append(dataMat[i, j]) 109 if dataMat[i, ansidx] == minele: 110 dataLeft.append(temp) 111 labelLeft.append(labelMat[i, 0]) 112 else: 113 dataRight.append(temp) 114 labelRight.append(labelMat[i, 0]) 115 return dataLeft, labelLeft, dataRight, labelRight, node 116 117 def work(data, label): 118 data = mat(data); label = mat(label) 119 datal, labell, datar, labelr, nd = CART(data, label) 120 root = nd 121 cnt0 = 0 122 datal = mat(datal) 123 labell = mat(labell) 124 if shape(labell)[1] != 1: 125 labell = transpose(labell) 126 datar = mat(datar) 127 labelr = mat(labelr) 128 if shape(labelr)[1] != 1: 129 labelr = transpose(labelr) 130 for i in range(shape(labell)[0]): 131 if labell[i, 0] == 0: 132 cnt0 += 1.0 133 if shape(datal)[1] != 0 and cnt0/float(shape(labell)[0]) > 0.1 and cnt0/float(shape(labell)[0]) < 0.9: 134 if shape(labell)[0] == 0: 135 print('zzz') 136 print(shape(labell)) 137 print(shape(datal)) 138 root.left = work(datal, labell) 139 elif shape(labell)[0] == 0: 140 ndl = Node() 141 ndl.key = 0 142 root.left = ndl 143 else: 144 ndl = Node() 145 if cnt0/float(shape(labell)[0]) <= 0.1: 146 ndl.key = 1 147 else: 148 ndl.key = 0 149 root.left = ndl 150 cnt0 = 0 151 for i in range(shape(labelr)[0]): 152 if labelr[i] == 0: 153 cnt0 += 1.0 154 if shape(datar)[1] != 0 and (cnt0/float(shape(labelr)[0]) > 0.1 and cnt0/float(shape(labelr)[0]) < 0.9): 155 root.right = work(datar, labelr) 156 elif shape(labelr)[0] == 0: 157 ndl = Node() 158 ndl.key = 0 159 root.right = ndl 160 else: 161 ndl = Node() 162 if cnt0/float(shape(labelr)[0]) <= 0.1: 163 ndl.key = 1 164 else: 165 ndl.key = 0 166 root.right = ndl 167 return root 168 169 def classify(root, dataMat): 170 dataMat = mat(dataMat) 171 m, n = shape(dataMat) 172 ans = [] 173 for i in range(m): 174 tmp = [] 175 troot = root 176 for j in range(n): 177 tmp.append(dataMat[i, j]) 178 while (True): 179 if tmp[int(troot.pos)] != troot.data: 180 troot = troot.right 181 else: 182 troot = troot.left 183 if troot.key != -1 or troot.pos == -1: 184 ans.append(troot.key) 185 break 186 tmp.remove(tmp[troot.pos]) 187 return ans 188 189 traindir = 'C:\\Users\\think\\Desktop\\train.csv' 190 testdir = 'C:\\Users\\think\\Desktop\\test.csv' 191 data, label = loadTrainSet(traindir) 192 data = mat(data) 193 label = mat(label) 194 m, n = shape(data) 195 print(shape(data)) 196 root = work(data, label) 197 print('!!!!!!') 198 print(root.data) 199 print(root.pos) 200 print(root.left.key) 201 print(root.right.key) 202 testdata = loadTestSet(testdir) 203 ans = classify(root, testdata) 204 print(ans) 205 j = 892 206 f = open('C:\\Users\\think\\Desktop\\ans.csv', 'w+') 207 for i in range(len(ans)): 208 f.write('%s,%s\n' % (str(j), str(ans[i]))) 209 j += 1
处理过程中需要在x中添加一列元素,并且将这一列元素的初始值设为1,然后利用梯度下降进行计算,计算出thata值,然后利用matplotlib画出来,效果也还可以。
1 from numpy import * 2 import matplotlib.pyplot as plt 3 import csv 4 5 def str2double(lst): 6 lst = mat(lst) 7 m, n = shape(lst) 8 print(m, n) 9 l = list() 10 for i in range(m): 11 for j in range(n): 12 l.append(double(lst[i, j])) 13 return l 14 15 def getData(path): 16 with open(path) as file: 17 lines = csv.reader(file) 18 l = [] 19 for line in lines: 20 l.append(line) 21 rt = str2double(l) 22 return rt 23 24 def sigmod(inX): 25 return 1.0/(1+exp(-inX)) 26 27 def gradAscent(data1, data2): 28 xMat = matrix(data1); yMat = matrix(data2) 29 m, n = shape(xMat) 30 alpha = 0.07 31 maxCycles = 50 32 weights = ones((n, 1)) 33 for k in range(maxCycles): 34 h = xMat*weights 35 error = yMat - h 36 weights = weights + alpha*xMat.transpose()*error 37 print(weights) 38 return weights 39 40 def grad(data1, data2): 41 xMat = matrix(data1); yMat = matrix(data2) 42 theta = zeros(shape(xMat[0, :])) 43 theta = theta.transpose() 44 print('shape theta') 45 print(shape(theta)) 46 maxCycles = 1500 47 alpha = 0.07 48 for k in range(maxCycles): 49 tmp = xMat 50 gd = (1/m) * xMat.transpose() * ((xMat * theta) - yMat) 51 theta = theta - alpha*gd 52 return theta 53 54 path1 = 'C:\\Users\\lg\\Desktop\\DL\\ex2x1.csv' 55 path2 = 'C:\\Users\\lg\\Desktop\\DL\\ex2y1.csv' 56 x = getData(path1) 57 y = getData(path2) 58 m = len(y) 59 xx = ones((m, 2)) 60 yy = ones((m, 1)) 61 for i in range(m): 62 yy[i, 0] = y[i] 63 for i in range(m): 64 xx[i, 1] = x[i] 65 print('xx shape') 66 print(shape(xx)) 67 print('yy shape') 68 print(shape(yy)) 69 70 theta = grad(xx, yy) 71 #weights = gradAscent(xx, yy) 72 73 plt.ylabel('Height in meters') 74 plt.xlabel('Age in years') 75 plt.plot(x, y, 'o') 76 plt.plot(xx[:,1], theta[1,0]*xx[:,1]+theta[0, 0]) 77 plt.show()
下面是画出来的图

题目中所用的测试数据点击这里可以进行下载。
Exercise: Multivariate Linear Regression
处理过程要注意X的标准处理
1 from numpy import * 2 import matplotlib.pyplot as plt 3 import csv 4 5 def str2double(lst): 6 lst = mat(lst) 7 m, n = shape(lst) 8 mt = ones((m, n)) 9 for i in range(m): 10 for j in range(n): 11 mt[i, j] = double(lst[i, j]) 12 return mt 13 14 def getData(path): 15 l = [] 16 with open(path) as file: 17 lines = csv.reader(file) 18 for line in lines: 19 l.append(line) 20 ret = str2double(l) 21 return ret 22 23 24 def grad(data1, data2): 25 plt.figure() 26 alpha =list([0.01, 0.03, 0.1, 0.3, 1]) 27 color = list(['b', 'c', 'g', 'k', 'm']) 28 maxCycle = 50 29 for t in range(len(alpha)): 30 print(t) 31 xMat = matrix(data1); yMat = matrix(data2) 32 theta = zeros((shape(xMat)[1], 1)) 33 Jtheta = zeros((maxCycle, 1)) 34 xlabel = [i for i in range(maxCycle)] 35 m = shape(yMat)[0] 36 for i in range(maxCycle): 37 tmp = xMat 38 Jtheta[i, 0] = (1/m)*(xMat*theta-yMat).transpose()*(xMat*theta-yMat) 39 gd = (1/m) * xMat.transpose() * ((xMat * theta) - yMat) 40 theta = theta - alpha[t]*gd 41 print(Jtheta) 42 plt.plot(xlabel, Jtheta, color[t]) 43 plt.show() 44 45 path1 = 'C:\\Users\\lg\\Desktop\\DL\\ex3x.csv' 46 path2 = 'C:\\Users\\lg\\Desktop\\DL\\ex3y.csv' 47 48 x = getData(path1) 49 y = getData(path2) 50 51 xx = ones((shape(x)[0], shape(x)[1]+1)) 52 for i in range(shape(x)[0]): 53 for j in range(shape(x)[1]): 54 xx[i, j+1] = x[i, j] 55 mean_xx = mean(xx, axis=0) 56 var_xx = var(xx, axis=0) 57 xx[:, 1] = (xx[:,1]-mean_xx[1])/var_xx[1] # 标准化处理 58 xx[:, 2] = (xx[:,2]-mean_xx[2])/var_xx[2] # 标准化处理 59 grad(xx, y)

题目中所用的数据点击这里进行下载
Exercise: Logistic Regression and Newton's Method
这里使用的是Newton's method,下面是一个关于牛顿法的简介
1、求解方程。
并不是所有的方程都有求根公式,或者求根公式很复杂,导致求解困难。利用牛顿法,可以迭代求解。
原理是利用泰勒公式,在x0处展开,且展开到一阶,即f(x) = f(x0)+(x-x0)f'(x0)
求解方程f(x)=0,即f(x0)+(x-x0)*f'(x0)=0,求解x = x1=x0-f(x0)/f'(x0),因为这是利用泰勒公式的一阶展开,f(x) = f(x0)+(x-x0)f'(x0)处并不是完全相等,而是近似相等,这里求得的x1并不能让f(x)=0,只能说f(x1)的值比f(x0)更接近f(x)=0,于是乎,迭代求解的想法就很自然了,可以进而推出x(n+1)=x(n)-f(x(n))/f'(x(n)),通过迭代,这个式子必然在f(x*)=0的时候收敛。整个过程如下图:

2、牛顿法用于最优化
在最优化的问题中,线性最优化至少可以使用单纯行法求解,但对于非线性优化问题,牛顿法提供了一种求解的办法。假设任务是优化一个目标函数f,求函 数f的极大极小问题,可以转化为求解函数f的导数f'=0的问题,这样求可以把优化问题看成方程求解问题(f'=0)。剩下的问题就和第一部分提到的牛顿 法求解很相似了。
这次为了求解f'=0的根,把f(x)的泰勒展开,展开到2阶形式:

这个式子是成立的,当且仅当 Δx 无线趋近于0。此时上式等价与:

求解:

得出迭代公式:

一般认为牛顿法可以利用到曲线本身的信息,比梯度下降法更容易收敛(迭代更少次数),如下图是一个最小化一个目标方程的例子,红色曲线是利用牛顿法迭代求解,绿色曲线是利用梯度下降法求解。

在上面讨论的是2维情况,高维情况的牛顿迭代公式是:

其中H是hessian矩阵,定义为:

高维情况依然可以用牛顿迭代求解,但是问题是Hessian矩阵引入的复杂性,使得牛顿迭代求解的难度大大增加,但是已经有了解决这个问题的办法就 是Quasi-Newton methond,不再直接计算hessian矩阵,而是每一步的时候使用梯度向量更新hessian矩阵的近似。Quasi-Newton method的详细情况我还没完全理解,且听下回分解吧。。。
1 from numpy import * 2 import matplotlib 3 import matplotlib.pyplot as plt 4 import csv 5 from numpy.matlib import repmat 6 from numpy.linalg import inv 7 def str2double(lst): 8 lst = mat(lst) 9 m, n = shape(lst) 10 mt = ones((m, n)) 11 for i in range(m): 12 for j in range(n): 13 mt[i, j] = double(lst[i, j]) 14 return mt 15 16 def getData(path): 17 l = [] 18 with open(path) as file: 19 lines = csv.reader(file) 20 for line in lines: 21 l.append(line) 22 ret = str2double(l) 23 return ret 24 25 def sigmoid(inX): 26 return 1.0/(1+exp(-inX)) 27 28 def gradAscent(dataArray, labelArray): 29 dataMat = matrix(dataArray); labelMat = matrix(labelArray) 30 m, n = shape(dataMat) 31 alpha = 0.0005 32 maxCycle = 1500 33 weights = zeros((n, 1)) 34 for k in range(10): 35 h = sigmoid(dataMat*weights) 36 error = h-labelMat 37 delta_J = repmat(error, 1, 3) 38 for i in range(shape(delta_J)[0]): 39 for j in range(shape(delta_J)[1]): 40 delta_J[i, j] *= dataMat[i, j] 41 delta = zeros((1, shape(delta_J)[1])) 42 for j in range(shape(delta_J)[1]): 43 for i in range(shape(delta_J)[0]): 44 delta[0, j] += delta_J[i, j] 45 tmp = zeros((shape(h)[0], 1)) 46 for i in range(shape(h)[0]): 47 tmp[i, 0] = h[i, 0] * (1-h[i, 0]) 48 temp = repmat(tmp, 1, 3) 49 for i in range(shape(dataMat)[0]): 50 for j in range(shape(dataMat)[1]): 51 temp[i, j] *= dataMat[i, j] 52 H = dataMat.transpose() * temp 53 weights = weights - inv(H)*(delta.transpose()) 54 return weights 55 path1 = 'C:\\Users\\lg\\Desktop\\DL\\ex4x.csv' 56 path2 = 'C:\\Users\\lg\\Desktop\\DL\\ex4y.csv' 57 58 x = getData(path1) 59 y = getData(path2) 60 61 xx = ones((shape(x)[0], shape(x)[1]+1)) 62 for i in range(shape(x)[0]): 63 for j in range(shape(x)[1]): 64 xx[i, j+1] = x[i, j] 65 66 axes = plt.subplot(111) 67 type1_x = [] 68 type1_y = [] 69 type2_x = [] 70 type2_y = [] 71 72 for i in range(shape(y)[0]): 73 if y[i, 0] == 1: 74 type1_x.append(x[i, 0]) 75 type1_y.append(x[i, 1]) 76 else: 77 type2_x.append(x[i, 0]) 78 type2_y.append(x[i, 1]) 79 80 type1 = axes.scatter(type1_x, type1_y, s=20, c='red') 81 type2 = axes.scatter(type2_x, type2_y, s=40, c='green') 82 weights = gradAscent(xx, y) 83 print(weights) 84 minx = 100000000; miny = -100000000 85 for i in range(shape(x)[0]): 86 if x[i, 0] < minx: 87 minx = x[i, 0] 88 if x[i, 0] > miny: 89 miny = x[i, 0] 90 plot_x = [minx, miny] 91 plot_y = [(-weights[0,0]-weights[1,0]*minx)/weights[2,0], (-weights[0,0]-weights[1,0]*miny)/weights[2,0]] 92 plt.plot(plot_x, plot_y) 93 axes.legend((type1, type2), ('OK', 'NO'), loc=2) 94 plt.show() 95 96 cnt = 0 97 for i in range(shape(x)[0]): 98 tmp = sigmoid(weights[0,0]+weights[1,0]*xx[i,1]+weights[2,0]*xx[i,2]) 99 if tmp >= 0.5: 100 tmp = 1.0 101 else: 102 tmp = 0 103 if tmp != y[i, 0]: 104 cnt += 1 105 print(cnt/shape(x)[0])
下面是个不错的MATLAB代码
1 function [theta, J ] = newton( x,y ) 2 %NEWTON Summary of this function goes here 3 % Detailed explanation goes here 4 m = length(y); 5 theta = zeros(3,1); 6 g = inline('1.0 ./ (1.0 + exp(-z))'); 7 pos = find(y == 1); 8 neg = find(y == 0); 9 J = zeros(10, 1); 10 for num_iterations = 1:10 11 %计算实际输出 12 h_theta_x = g(x * theta); 13 %将y=0和y=1的情况分开计算后再相加,计算J函数 14 pos_J_theta = -1 * log(h_theta_x(pos)); 15 neg_J_theta = -1 *log((1- h_theta_x(neg))); 16 J(num_iterations) = sum([pos_J_theta;neg_J_theta])/m; 17 %计算J导数及Hessian矩阵 18 delta_J = sum(repmat((h_theta_x - y),1,3).*x); 19 H = x'*(repmat((h_theta_x.*(1-h_theta_x)),1,3).*x); 20 %更新θ 21 theta = theta - inv(H)*delta_J'; 22 end 23 % now plot J 24 % technically, the first J starts at the zero-eth iteration 25 % but Matlab/Octave doesn't have a zero index 26 figure; 27 plot(0:9, J(1:10), '-') 28 xlabel('Number of iterations') 29 ylabel('Cost J') 30 end

题目中所用的数据请点击这里进行下载。
此时的模型表达式如下所示:
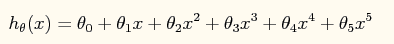
模型中包含了规则项的损失函数如下:
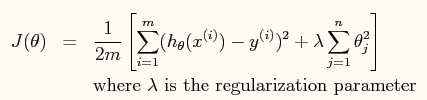
模型的normal equation求解为:
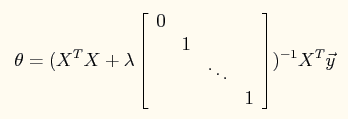
程序中主要测试lambda=0,1,10这3个参数对最终结果的影响。

点击这里下载实验数据
1 clc,clear 2 %加载数据 3 x = load('C:\\Users\\lg\\Desktop\\DL\\ex5\\ex5Linx.dat'); 4 y = load('C:\\Users\\lg\\Desktop\\DL\\ex5\\ex5Liny.dat'); 5 6 %显示原始数据 7 plot(x,y,'o','MarkerEdgeColor','b','MarkerFaceColor','r') 8 9 %将特征值变成训练样本矩阵 10 x = [ones(length(x),1) x x.^2 x.^3 x.^4 x.^5]; 11 [m n] = size(x); 12 n = n -1; 13 14 %计算参数sidta,并且绘制出拟合曲线 15 rm = diag([0;ones(n,1)]);%lamda后面的矩阵 16 lamda = [0 1 10]'; 17 colortype = {'g','b','r'}; 18 sida = zeros(n+1,3); 19 xrange = linspace(min(x(:,2)),max(x(:,2)))'; 20 hold on; 21 for i = 1:3 22 sida(:,i) = inv(x'*x+lamda(i).*rm)*x'*y;%计算参数sida 23 norm_sida = norm(sida) 24 yrange = [ones(size(xrange)) xrange xrange.^2 xrange.^3,... 25 xrange.^4 xrange.^5]*sida(:,i); 26 plot(xrange',yrange,char(colortype(i))) 27 hold on 28 end 29 legend('traning data', '\lambda=0', '\lambda=1','\lambda=10')%注意转义字符的使用方法 30 hold off


 浙公网安备 33010602011771号
浙公网安备 33010602011771号