KMP学习笔记
KMP 学习笔记
你说得对,但是还是怀着对于OI的热情来了。
好了,搞一下字符串。
考虑这样的一个问题,给出字符串 和 ,在主串 中找到 子串 。
先定义。
-
一个 字符串 是将 个字符顺次排列形成的序列, 称为 的长度,表示为 。
-
定义前缀,表示从 下标顺序组成的字符串,真前缀指字符串除了他本身的所有前缀。后缀就是从 为下标组成的。真后缀定义类似。
-
为了方便,定义字符串 中由下标 组成的字符串记为 。
考虑求出这样一个数组 , 表示 中,找到一个最长的真前缀 ,满足该 是 的真后缀。 保存的值就是 。
他可以被 求出来,先让 ,考虑递推,如果已经知道 的答案,求 。
-
如果 保存的答案 ,满足 ,就有 。
-
如果不满足,那就一直往后跳 ,一直到可以满足 为止。
这样做是没有问题的,原因在于,每次在往前跳的时候(比如从 跳到 (也就是 )),必定可以发现 这段一定都是不合法的。因为根据定义,这之间的任何一个位置作为末尾的前缀必然不满足是他的真后缀,(去反证他,如果满足的话,那就和 的定义违背了。)
那就达不到求解 的目的。那既然全都不是,一直往前跳也就不会跳过可能的答案了。
而这个字符串的匹配,恰好是 数组的应用。
考虑这样一个问题,给出主串 和子串 ,要求在 中找到 。
考虑一个暴力算法,对于主串S,从前往后地,每次到第 位作为起点开始匹配,匹配到对应字符位置不同位置,到 去匹配。能匹配完就记录答案,这样做是 的。
而我们可以做到 。
考虑对 求出 数组,每次在匹配的时候,比如到第 位匹配不下去了,我们就对当前位跳 数组,一直到满足 ,让 作为终点,让当前的字符串匹配 的部分。
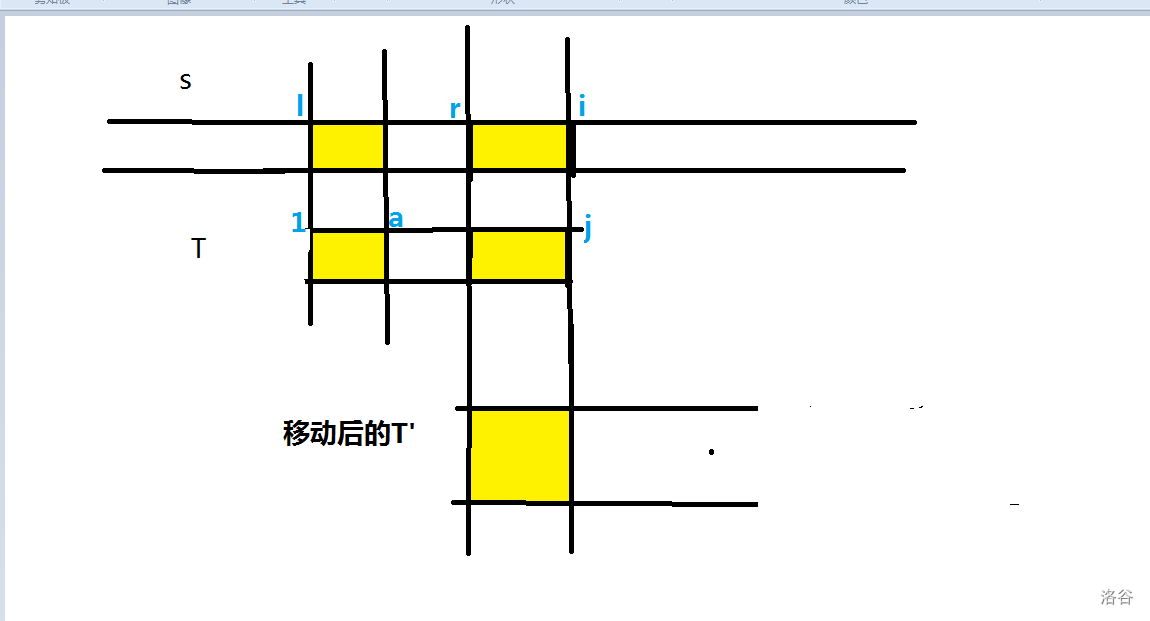
这么做也是对的,因为,只匹配 的部分,决定了以 为起点去匹配都是不合法的。反证他,如果有比 前的 可以的话,那必然会有一个更右的 和他去匹配,也就是 ,又因为 ,两段重合。所以有一个更前的 。
不难发现,,那么 就是一个更大的 值了。这和 假设矛盾。
如果匹配完整个串 的话,就相当于在 的位置失配了。
然后就是实现的细节问题,让指针 一直在停留在 的位置,这样方便 去跳 求值,更加简洁一些,具体参照 Link。
题目大意:在一个字符串里面找到一个最长的前缀,满足他是字符串的后缀,以及他在字符串中间有出现过。
做法就是,在对他跑 KMP 的时候,对每个点的 值打标记,然后遍历 ,这里面就是满足既是前缀,又是后缀,再看 为前缀在标记中是否有出现过(如果有的话,说明 有一段前缀的后缀与其相等,那就是在中间出现过了)
差不太多,对 跑 数组,然后发现其实对 进行保留,复制字符串剩下的,这样就可以达到复制完最小的长度,(因为 是最大的)。
这样一定是优秀的,因为 是最早能够新贡献一个答案的位置了。
其实做的时候都是拼感性的理解。
更厉害了。
毫无规律可循,对第一篇题解补充。
就是他对齐的过程,就是把相等前后缀拉出来“对齐”的过程,更细致一点,就是把字符串复制一遍,找到前后缀相等的过程。
第三张图“依此类推”,其实就是,你把下面那部分的前缀对上去,再对回来一下,就能够发现,他是一一重合的,也就像是 所复制过去的了。
同时,可以发现 是最大的, 是最小的,所以不会错过答案。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号