Spark RDD 分区之HashPartitioner
Spark RDD 分区
Spark RDD分区是并行计算的一个计算单元,RDD在逻辑上被分为多个分区,分区的格式决定了并行计算的粒度,任务的个数是是由最后一个RDD的
的分区数决定的。
Spark自带两中分区:HashPartitioner RangerPartitioner。一般而言初始数据是没有分区的,数据分区只作用于key value这样的RDD上,
当一个Job包含Shuffle操作类型的算子时,如groupByKey,reduceByKey等,就会使用数据分区的方式进行分区,即确定key放在哪一个分区。
shuffle与Partition关系
摘自[Spark分区方式详解](https://blog.csdn.net/dmy1115143060/article/details/82620715)
在Spark Shuffle阶段中,共分为Shuffle Write阶段和Shuffle Read阶段,其中在Shuffle Write阶段中,Shuffle Map Task对数据进行处理产生中间数据,然后再根据数据分区方式对中间数据进行分区。最终Shffle Read阶段中的Shuffle Read Task会拉取Shuffle Write阶段中产生的并已经分好区的中间数据。图2中描述了Shuffle阶段与Partition关系。下面则分别介绍Spark中存在的两种数据分区方式。

HashPartitioner
HashPartitioner采用哈希方式对kay进行分区,分区规则为 partitionId = Key.hashCode % numPartitions,其中partitionId代表该Key对应的键值对数据应当分配到的Partition标识,Key.hashCode表示该Key的哈希值,numPartitions表示包含的Partition个数。
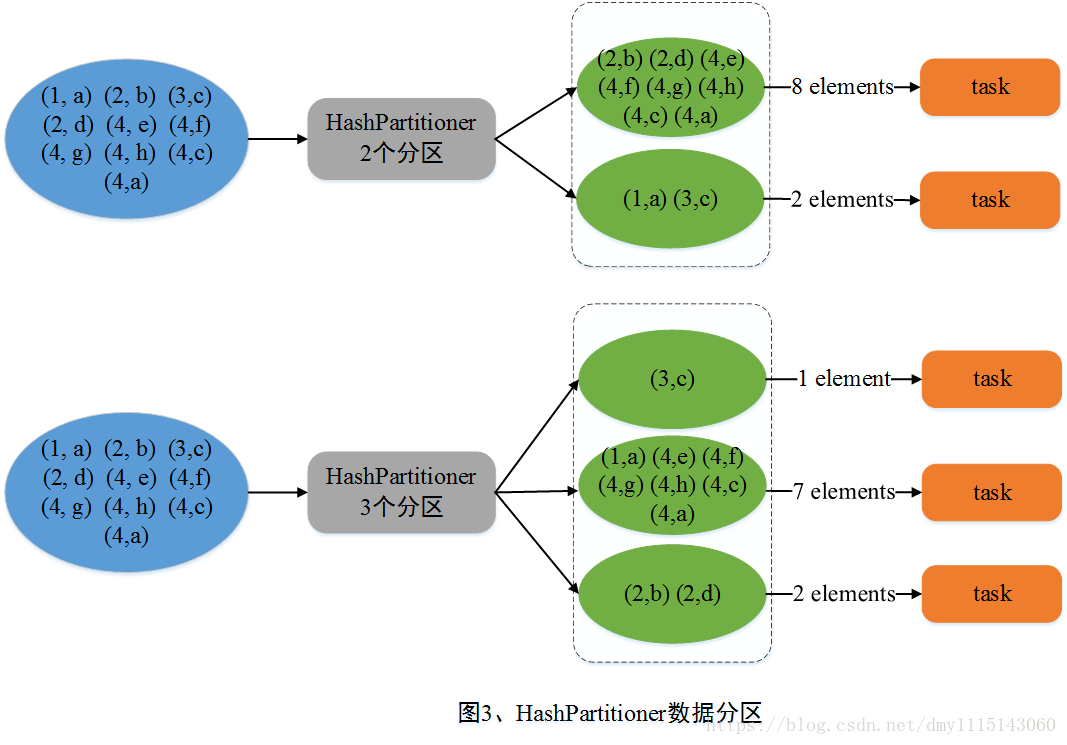
RDD 分区例子
package com.learn.hadoop.spark.doc.analysis.chpater.rdd;
import org.apache.spark.HashPartitioner;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
/**
* RDD分区
*HashPartitioner
*/
public class RddTest05 {
public static void main(String[] args) {
SparkConf sparkConf =new SparkConf().setMaster("local[*]").setAppName("RddTest05");
JavaSparkContext sc =new JavaSparkContext(sparkConf);
JavaRDD<String> rdd =sc.parallelize(Arrays.asList("hello spark world ","hello java world","hello python world"));
//设置当前分区数与cpu core有关
System.out.println("local partitions:");
System.out.println("rdd partitions num "+rdd.getNumPartitions());
System.out.println("rdd partitioner :"+rdd.partitioner().toString());
JavaRDD<String> words = rdd.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.asList(s.split(" ")).iterator();
}
});
//输出所有的word
System.out.println("console all word");
words.foreach(s -> System.out.println(s));
JavaPairRDD<String,Integer> wordPairs = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<>(s,1);
}
});
//输出所有的对pairRDD
System.out.println("console all pair");
//wordPairs.foreach(stringIntegerTuple2 -> System.out.println(stringIntegerTuple2));
wordPairs.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
System.out.println(stringIntegerTuple2);
}
});
System.out.println("wordPairs partitioner :"+wordPairs.partitioner().toString());
//归纳redues
JavaPairRDD<String,Integer> wordredues = wordPairs.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer+integer2;
}
});
//reduceByKey默认的分区器就是HashPartitioner
System.out.println("wordredues partitioner num: "+wordredues.getNumPartitions());
System.out.println("wordredues partitioner :"+wordredues.partitioner().toString());
//输出字符统计
System.out.println("console all");
wordredues.foreach(stringIntegerTuple2 -> System.out.println(stringIntegerTuple2));
//测试默认排序,默认是ascending(上升)true,如果sortByKey参数是false则是降序
System.out.println("test sort:");
wordredues=wordredues.sortByKey(true);
wordredues.foreach(stringIntegerTuple2 -> System.out.println(stringIntegerTuple2));
//sorkByKey的分区器是RangerPartitioner
System.out.println("after sort partitioner num: "+wordredues.getNumPartitions());
System.out.println("after sort partitioner . partitioner : " +
""+wordredues.partitioner().toString());
//设置HashPartitioner
wordredues =wordredues.partitionBy(new HashPartitioner(wordredues.getNumPartitions()));
System.out.println("after set hash partitioner . partitioner num :"+wordredues.partitioner().toString());
System.out.println("after set hash partitioner . partitioner :"+wordredues.partitioner().toString());
}
}
运行结果
local partitions:
rdd partitions num 8
rdd partitioner :Optional.empty
console all word
hello
java
world
hello
python
world
hello
spark
world
console all pair
(hello,1)
(java,1)
(world,1)
(hello,1)
(python,1)
(world,1)
(hello,1)
(spark,1)
(world,1)
wordPairs partitioner :Optional.empty
wordredues partitioner num: 8
wordredues partitioner :Optional[org.apache.spark.HashPartitioner@8]
console all
(python,1)
(spark,1)
(hello,3)
(java,1)
(world,3)
test sort:
(python,1)
(spark,1)
(java,1)
(hello,3)
(world,3)
after sort partitioner num: 5
after sort partitioner . partitioner : Optional[org.apache.spark.RangePartitioner@e6319a7d]
after set hash partitioner . partitioner num :5
after set hash partitioner . partitioner :Optional[org.apache.spark.HashPartitioner@5]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号