【转载】C语言数组操作和指针操作谁更高效
在上一篇博文 代码优化小技巧(持续更新......) 第三条关于数组和指针谁更高效, 意犹未尽, 决定单独拉出一篇来讲
1. 数组和指针操作对比
#include <stdio.h>
int main()
{
char *char_p, char_arr[5]={0,1,2};
short *short_p, short_arr[5]={1,2,3};
int *int_p, int_arr[5]={2,3,4};
char_p=char_arr;
short_p=short_arr;
int_p=int_arr;
printf("111\n");
(*(char_p+2)) ++;
printf("222\n");
char_arr[2] ++;
printf("111\n");
(*(short_p+2)) ++;
printf("222\n");
short_arr[2] ++;
printf("111\n");
(*(int_p+2)) ++;
printf("222\n");
int_arr[2] ++;
return 0;
}
编译和反汇编
 x86编译和反汇编
x86编译和反汇编 arm编译和反汇编
arm编译和反汇编横向对比:
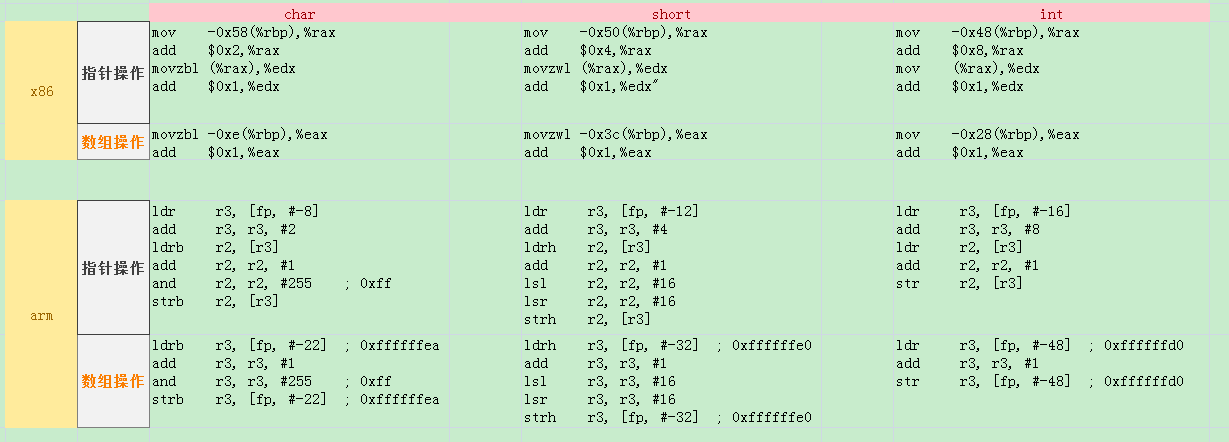
这里可以很明显得出结论: 使用数组操作比指针高效!, 理由很简单, 编译器认为数组偏移多少成员其对于地址都是确定的, 取数组[0]和[3]没有区别就是个地址, 而指针偏移是一个独立行为,
所以要显性执行这个动作, 因此多出这部分指令!
这个表还有其他有意思的地方, 比如用int变量比char、short高效, char要and或者movzbl屏蔽溢出, short要lsl/lsr左移右移等
另外就是x86可以直接通过mov操作内存, 而ARM结构采用load-store, 必须先加载到寄存器, 进行操作后再回写内存
2. 指针作为函数参数(x86编译为例)
#include <stdio.h>
void test1(int *p)
{
(*(p+4))++;
}
void test2(int *p)
{
p[4]++;
}
int main()
{
char *char_p, char_arr[5]={0,1,2};
short *short_p, short_arr[5]={1,2,3};
int *int_p, int_arr[5]={2,3,4};
char_p=char_arr;
short_p=short_arr;
int_p=int_arr;
/* 省略上面测试代码*/
printf("333\n");
test1(int_p);
test2(int_p);
printf("444\n");
test1(int_arr);
test2(int_arr);
return 0;
}
可以发现test1()、test2()反汇编实现是一样的, 不会因为“形式”上我用数组还是指针, 最终的本质是指针, 而调用无论传的是数组地址还是指针地址, 没有影响, 都是地址值而已

0000000000400596 <test1>: 400596: 55 push %rbp 400597: 48 89 e5 mov %rsp,%rbp 40059a: 48 89 7d f8 mov %rdi,-0x8(%rbp) 40059e: 48 8b 45 f8 mov -0x8(%rbp),%rax 4005a2: 48 83 c0 10 add $0x10,%rax 4005a6: 8b 10 mov (%rax),%edx 4005a8: 83 c2 01 add $0x1,%edx 4005ab: 89 10 mov %edx,(%rax) 4005ad: 90 nop 4005ae: 5d pop %rbp 4005af: c3 retq00000000004005b0 <test2>:
4005b0: 55 push %rbp
4005b1: 48 89 e5 mov %rsp,%rbp
4005b4: 48 89 7d f8 mov %rdi,-0x8(%rbp)
4005b8: 48 8b 45 f8 mov -0x8(%rbp),%rax
4005bc: 48 83 c0 10 add $0x10,%rax
4005c0: 8b 10 mov (%rax),%edx
4005c2: 83 c2 01 add $0x1,%edx
4005c5: 89 10 mov %edx,(%rax)
4005c7: 90 nop
4005c8: 5d pop %rbp
4005c9: c3 retq4006e7: e8 74 fd ff ff callq 400460 <puts@plt>
4006ec: 48 8b 45 b8 mov -0x48(%rbp),%rax
4006f0: 48 89 c7 mov %rax,%rdi
4006f3: e8 9e fe ff ff callq 400596 <test1>
4006f8: 48 8b 45 b8 mov -0x48(%rbp),%rax
4006fc: 48 89 c7 mov %rax,%rdi
4006ff: e8 ac fe ff ff callq 4005b0 <test2>
400704: bf e0 07 40 00 mov $0x4007e0,%edi
400709: e8 52 fd ff ff callq 400460 <puts@plt>
40070e: 48 8d 45 d0 lea -0x30(%rbp),%rax
400712: 48 89 c7 mov %rax,%rdi
400715: e8 7c fe ff ff callq 400596 <test1>
40071a: 48 8d 45 d0 lea -0x30(%rbp),%rax
40071e: 48 89 c7 mov %rax,%rdi
400721: e8 8a fe ff ff callq 4005b0 <test2>
3. 数组作为函数参数(x86编译为例)
代码和上面一样就不贴了, 只是将参数改成数组
/*
void test1(int *p)
{
(*(p+4))++;
}
void test2(int *p)
{
p[4]++;
}
*/
void test1(int p[])
{
(*(p+4))++;
}
void test2(int p[])
{
p[4]++;
}
反汇编的结果发现和上面函数形参是指针的一模一样! 也就是说虽然我的参数看起来像数组, 但实际上由于没有指定成员数量实际分配内存, 所以编译器还是把参数当做指针对待!
结论:
a. “真实”数组操作比指针高效
b. 有些看起来像数组, 实质是指针的, 指令走的还是指针那一套, 无论语法写的是*p++还是p[i]
