三分钟掌握共享内存 & Actor并发模型
- 共享内存
- Actor并发编程模型
- 202309反省: 求素数和不适合体现Actor模型
吃点好的,很有必要。今天介绍常见的两种并发模型: 共享内存&Actor
共享内存编程模型
面向对象编程中,万物都是对象,数据+行为=对象;
多核时代,可并行多个线程,但是受限于资源对象,线程之间存在对共享内存的抢占/等待,实质是多线程调用对象的行为方法,这涉及#线程安全#线程同步#。
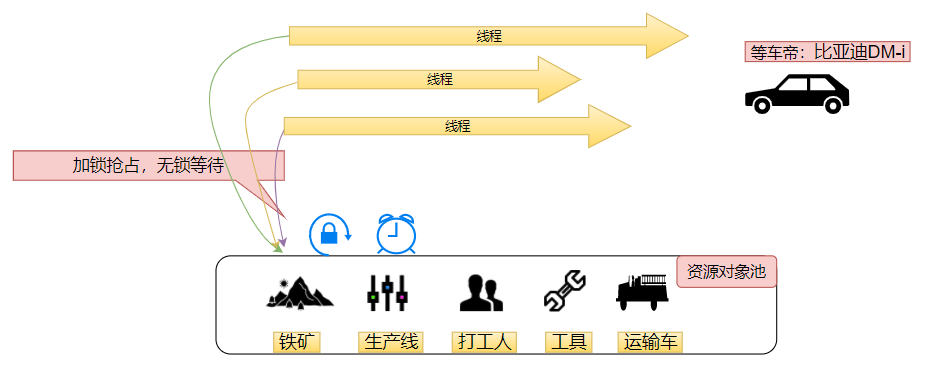
假如现在有一个任务,找100000以内的素数的个数,如果用共享内存的方法,代码如下:
可以看到,这些线程共享了sum变量,对sum做sum++操作时必须上锁。
using System; using System.Threading.Tasks; using System.Collections; using System.Collections.Generic; using System.Threading; using System.Diagnostics; /// <summary> /// 利用并行编程库Parallel,计算10000内素数的个数 /// </summary> namespace Paralleler { class Program { static object syncObj = new object(); static void Main(string[] args) { Stopwatch sw = new Stopwatch(); sw.Start(); ShareMemory(); sw.Stop(); Console.WriteLine($"共享内存并发模型耗时:{sw.Elapsed}"); } static void ShareMemory() { var sum = 0; Parallel.For(1, 100000 + 1,(x, state) => { var f = true; if (x == 1) f = false; for (int i = 2; i <= x / 2; i++) { if (x % i == 0) // 被[2,x/2]任一数字整除,就不是质数 f = false; } if(f== true) { lock(syncObj) { sum++; // 共享了sum对象,“++”就是调用sum对象的成员方法 } } }); Console.WriteLine($"1-10000内质数的个数是{sum}"); } } }
共享内存更贴合"面向对象开发者的固定思维", 强调线程对于资源的掌控力。
Actor并发模型
Actor模型则认为一切皆是Actor,Actor模型内部的状态由自己的行为维护,外部线程不能直接调对象的行为,必须通过消息才能激发行为,也就是消息传递机制来代替共享内存模型对成员方法的调用, 这样保证Actor内部数据只能被自己修改。

还是找到10000内的素数,我们使用.NET TPL Dataflow来完成,代码如下:
每个Actor的产出物就是流转到下一个Actor的消息。
using System; using System.Threading.Tasks; using System.Collections; using System.Collections.Generic; using System.Threading; using System.Threading.Tasks.Dataflow; using System.Diagnostics; /// <summary> /// 利用并行编程库Paralleler,计算10000内素数的个数 /// </summary> namespace Paralleler { class Program { static void Main(string[] args) { Stopwatch sw = new Stopwatch(); sw.Start(); Actor(); sw.Stop(); Console.WriteLine($"Actor并发模型耗时:{sw.Elapsed}"); } static void Actor() { var linkOptions = new DataflowLinkOptions { PropagateCompletion = true }; var bufferBlock = new BufferBlock<int>(); var transfromBlock = new TransformBlock<int,bool>(x=> { var f = true; if (x == 1) f = false; for (int i = 2; i <= x / 2; i++) { if (x % i == 0) // 被[2,x/2]任一数字整除,就不是质数 f = false; } return f; }, new ExecutionDataflowBlockOptions { MaxDegreeOfParallelism=Environment.ProcessorCount}); // 默认MaxDegreeOfParallelism =1, 这里可充分利用多核能力 var sum = 0; var actionBlock = new ActionBlock<bool>(x=> { if (x == true) sum++; },new ExecutionDataflowBlockOptions { }); // 涉及外部共享变量sum, 不能加锁的话,就挨个处理,使用默认并发度1 transfromBlock.LinkTo(actionBlock, linkOptions); for (int i = 1; i <= 100000; i++) { transfromBlock.Post(i); } transfromBlock.Complete(); // 通知头部,不再投递了; 会将信息传递到下游。 actionBlock.Completion.Wait(); // 等待尾部执行完成 Console.WriteLine($"1-10000内质数的个数是{sum}"); } } }
TPL datflow中的所有块默认是单线程的 (并发度MaxDegreeOfParallelism= 1);意味着TransformBlock 和ActionBlock默认都是一个线程挨个处理消息。
当数据流块需要执行长时间运行的计算并且可从并行处理消息中获益时, 可以开启多核能力。
202309反省: 求素数数量不适合体现Actor
[求质数数量的例子]来对比 共享内存/actor其实并不合适。
第二阶段必然涉及最终共享变量的求和,违背了Actor内封状态和行为、由消息驱动的本质特征。
Actor模型, 你可以声明当数据可用时的处理方式,以及数据之间的所有依赖项。 由于运行时管理数据之间的依赖项,因此通常可以避免这种要求来同步访问共享数据。 此外,因为运行时计划基于数据的异步到达,所以数据流可以通过有效管理基础线程提高响应能力和吞吐量。
Actor模型最常见的使用场景是: 生产者消费者模型。
static void Actor1() { var linkOptions = new DataflowLinkOptions { PropagateCompletion = true }; var transfromBlock = new TransformBlock<int,string>(x=> { Thread.Sleep(1000); // 模拟生产时间 Console.WriteLine($"生产者0生产了 {0}:{x}"); return $"0:{x}"; }, new ExecutionDataflowBlockOptions { MaxDegreeOfParallelism = Environment.ProcessorCount }); var actionBlock = new ActionBlock<string>(x=> { Console.WriteLine("消费者消费了 {0}", x); Thread.Sleep(1000); // 模拟消费时间 },new ExecutionDataflowBlockOptions { MaxDegreeOfParallelism = Environment.ProcessorCount }); // 这里无所谓, 并没有线程安全问题。 transfromBlock.LinkTo(actionBlock, linkOptions); // 准备从pipeline头部开始投递 for (int i = 0; i < 10; i++) { transfromBlock.Post(i); } transfromBlock.Complete(); // 通知头部,不再投递了; 会将信息传递到下游。 actionBlock.Completion.Wait(); // 等待尾部执行完成 }
我的理解是:
- Actor模型规避了任务之间的显式依赖、共享数据,内封数据和行为,只能由消息来驱动Actor自己来改变内封的数据。---> 不依赖回调和同步,降低并发编程代码的心智负担。
- 在这种模型下,每个Actor都内置了一个mailbox,由mailbox体现不同Actor之间的依赖,由运行时来维护依赖数据的异步到达 & 确保mailbox并发安全。
总结
- 共享内存并发模型,需要开发者重视多线程对于共享代码的掌控力。
- Actor模型强调内封状态和行为、由消息驱动,由运行时维护actor之间的依赖(编码阶段提前定义了依赖关系),降低了编写高性能,低延迟应用的难度(开发者不再需要自行维护代码线程安全)。
- Golang使用的
Channel是类Actor模型,使用Channel进一步解耦了调用的参与方,你都不用关注下游提供者是谁。
本文来自博客园,作者:{有态度的马甲},转载请注明原文链接:https://www.cnblogs.com/JulianHuang/p/15035283.html
欢迎关注我的原创技术、职场公众号, 加好友谈天说地,一起进化


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?