你是不是对MD5算法有误解?
大家常听到“MD5加密”、“对称加密”、“非对称加密”,那么MD5属于哪种加密算法?
面试问这样的问题,准是在给你挖坑。
"MD5加密"纯属口嗨,MD5不是加密算法,是摘要算法(散列算法)。
今天小码甲带大家梳理加密算法、摘要算法的定义和场景:
伸手党先看答案:
加密算法的目的,在于使别人无法成功查看加密的数据,并且在需要的时候还可以对数据进行解密来重新查看数据。
而MD5算法是一种哈希算法(散列算法),哈希算法的设计目的本身就决定了,它在大多数情况下都是不可逆的,即你通过哈希算法得到的数据,无法经过任何算法还原回去。 所以既然不能将数据还原,也就不能称之为解密;既然不能解密,那么哈希的过程自然也就不能称作是[加密]了。
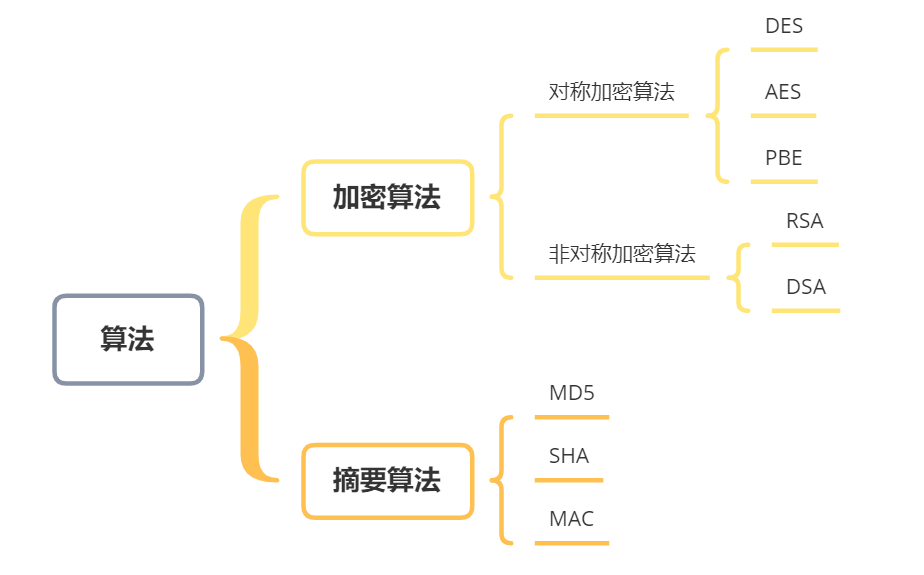
加密算法
加密: 是以某种特殊的算法改变原有的信息,使得未授权的用户即使获得已加密的信息,但因不知解密的方法,仍然无法了解信息的内容。
解密:加密的逆过程为解密,即将该加密信息转化为其原来信息的过程。
加密算法分为对称加密和非对称加密,其中对称加密算法的加解密密钥相同,非对称加解密的密钥不同。
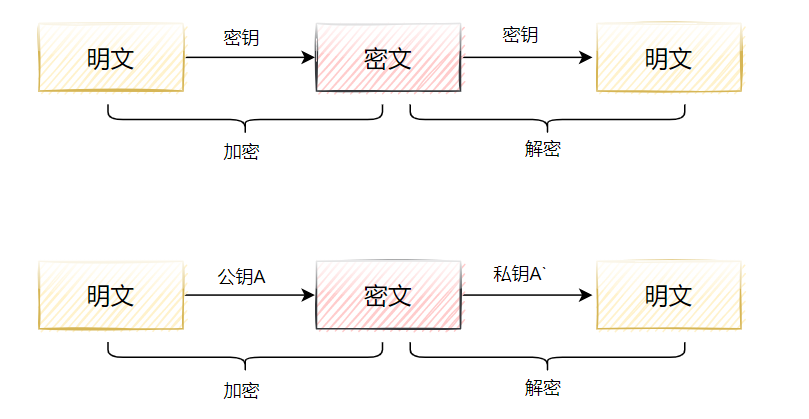
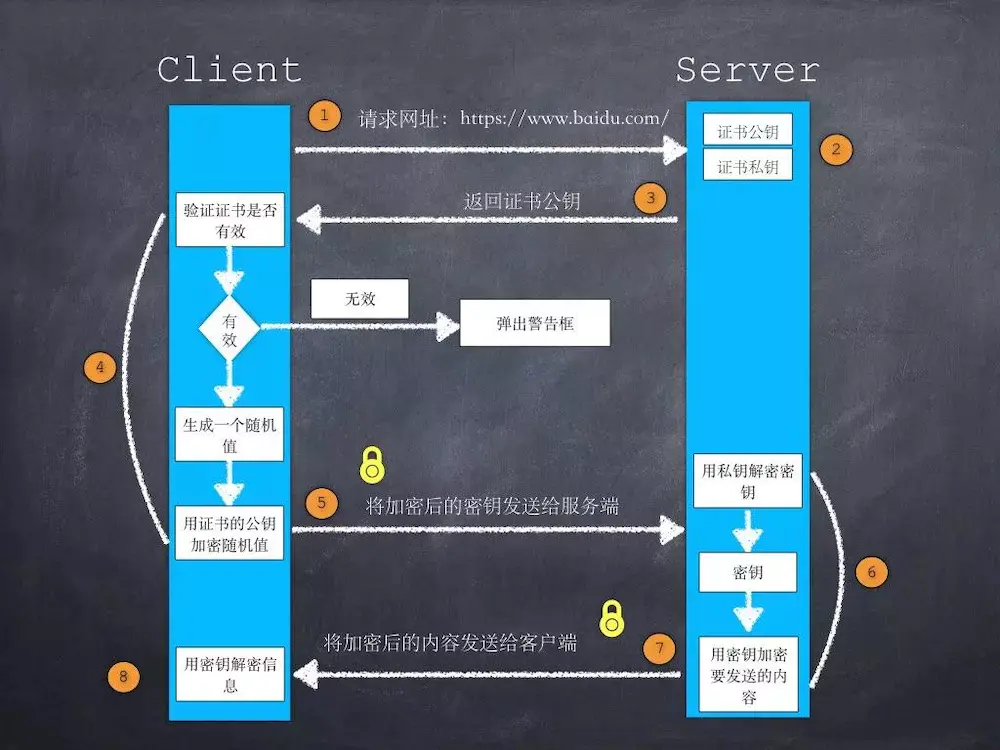
HTTPS就同时用到非对称加密和对称加密,在连接建立的阶段,使用非对称加解密(传输密钥), 在通信阶段使用对称密钥加解密数据。
摘要算法
摘要算法,又称哈希算法、散列算法。通过一个函数,将任意长度的内容转换为一个固定长度的数据串。
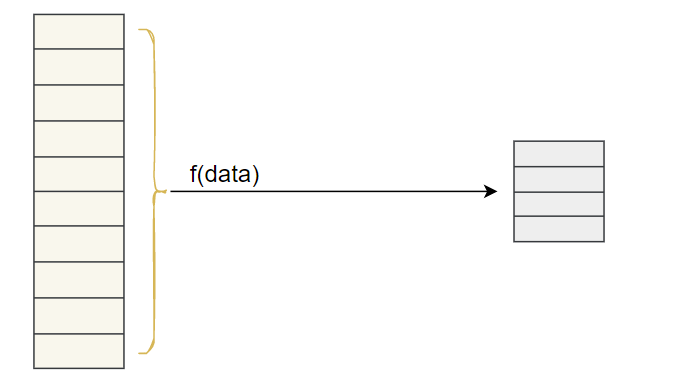
摘要算法之所以能指出数据是否被篡改,就是因为摘要函数是一个单向函数,计算很容易,但通过摘要(digest) 反推data却非常困难,而且,对于原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
理论上哈希算法都会有哈希冲突: 总会有不同的key,通过一个哈希函数,打到一个哈希值上, 现在的HMACSHA256的冲突概率极小,sha冲突基本可以忽略。
使用迅雷下载某片的时候,下载站会顺带给你一个MD5校验码;
你找一个MD5校验工具,对下载下来的文件执行MD5算法,将得到的哈希值与下载站附带的MD5值对比,如果值是相同的,说明从该网站下载的文件没有损坏。
HMAC
延伸聊一个结合了密钥和哈希功能的请求认证方案:
HMAC ( hash-based message authenticated code)
很多第三方平台都采用这种授权认证方案,你回想一下,api平台是不是经常给你一对AppID Serect Key
-
Client & Server 都知晓一个私钥
serect key -
客户端每次请求时,会针对(请求数据+ secret key)生成一个hash值
HMAC = hashFunc(secret key + message) -
客户端将哈希值做为请求的一部分,一起发送
-
当服务端收到请求, 对( 收到的请求+ 查到的
Serectkey')生成哈希,将计算的哈希值与请求中附带的原哈希值对比,如果相同,则认定请求来自受信Client,且请求未被篡改。
为什么会有这样的效果?
首先:Client 和Server的哈希值相同,根据哈希算法的设计初衷,说明请求过程未被篡改;
(还要评估你的高强度哈希函数,忽略可能的哈希冲突)
另一方面也反推 Client 和Server使用了相同的Serect Key , 而Serect Key是私密信息,故此处的Client不可抵赖。
还可以考虑在客户端生成哈希时加入timestamp时间戳(请求还要附带这个时间戳),服务端收到后先对比服务器时间戳与请求时间戳,限制15s内为有效请求,再对(请求信息+ 时间戳+ serectkey)哈希对比,缓解重放攻击。
总结
本文给出的示例: HTTPS、迅雷MD5校验,足够帮助你了解加密算法和摘要算法的设计目的。
- 加密算法的目的是: 防止信息被偷看
- 摘要算法的目的是: 防止信息被篡改
以后使用时候也能有的放矢,面试时也不会闹出笑话。
最后给出的WebAPI授权方案HMAC,算是密钥+哈希算法结合的一个应用场景, 具备快速、自签名的特点。
有关MD5散列算法再补充我自己的几个理解。
- 在不同机器上对同一文件做md5sum, 为什么值是一样的?
这是因为md5的计算过程只依赖与文件的内容,而不依赖与文件的位置、文件名或者操作系统。
md5算法会逐字节地处理文件的数据,并通过一系列的数学运算来生成一个固定长度的输出,这个输出是文件内容的数字摘要, 这也是md5可以跨平台和跨设备工作的原因。
-
md5 算法的核心
- 初始化: 使用4个预定义的常量数
- 预处理
- 主循环
- 处理每一个字
- 更新寄存器
- 输出
md5算法的设计目的是 为了确保即使输入的微小变化,也能产生截然不同的输出,同时输出不嫩如果回溯到输入,这杯称为 雪崩效应。
-
md5 散列值是随机的吗 ?
md5 算法不是随机的,而是确定性的, 对同一内容的计算(不care环境、平台、时间)都会产生一个固定的输出, 这个过程看似复杂且看似随机,但实际每一步都是严格定义好的,我随后去gpt查询了md5算法的第一步:初始化使用的4个预定义的常量,这4个常量值也不是随机选取的,这4个值是固定的(在算法设计时就确定下来的), 这些值实际是从圆周率小数点的数字中计算出来的,具体是π的前32位小数, 选择小河蟹初始值的原因是希望能够确保算法从一个“随机”点开始, 从而增加其输出的不可预测性,但实际这些值并非真正的随机数,而是π这一无理数的特性精心挑选的, 它被认为是一种“自然的”随机数源,有助于确保md5算法的输出具有良好的散列特性。
本文来自博客园,作者:{有态度的马甲},转载请注明原文链接:https://www.cnblogs.com/JulianHuang/p/14858339.html
欢迎关注我的原创技术、职场公众号, 加好友谈天说地,一起进化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号