Azure EventHubs快速入门和使用心得
Azure Event Hubs(事件中心)是一个大数据流式数据摄取服务平台,每秒接受数百万事件;
EventHubs 是一个有数据保留期限的缓冲区,类似分布式日志;可缩放的关键在于【分区消费模型】,每分区独立存储数据,被后端独立消费。随着时间推移,事件会逐渐老化,所以分区不会 full.
发送到Eventhub 中的数据可以被 readl-time analytics provider 和后端batch/storage adapters 处理和存储。
为什么要使用EventHubs?
从EventHubs中及时获取、探索数据 相当简单,EventHubs 提供了低延迟的分布式流式处理平台(低延迟、无缝集成Azure内外的数据和分析服务)
EventHubs代表“event管道”的前门,一般被定义为事件摄取器:在事件发布者和事件消费者之间起解耦作用的组件或服务。
特性
- Paas 上全托管
- 支持实时和批处理
- 可缩放
- 丰富的生态
本文主要记录两个重要知识点:Partition, EventHubs Capture
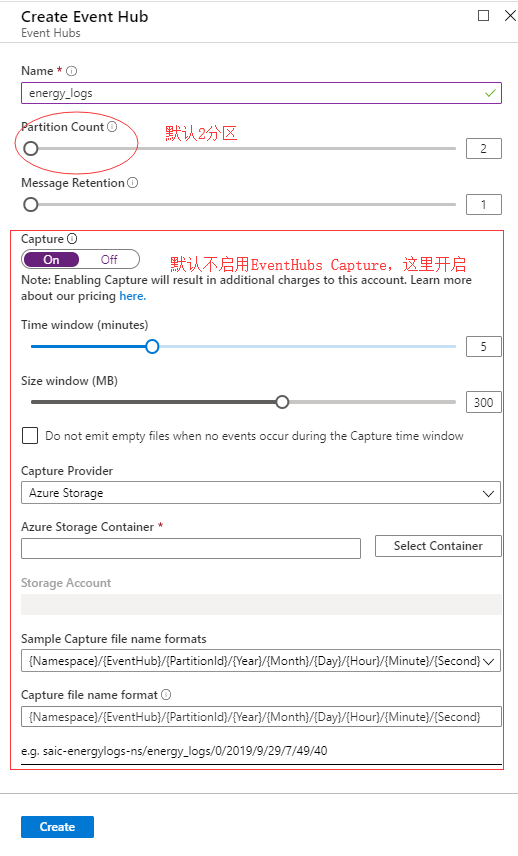
Azure上创建EventHubs命名空间之后,新增EventHubs时要关注以上配置。
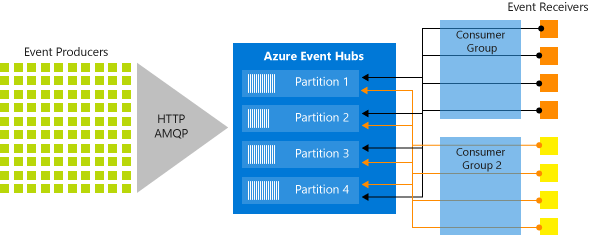
Partition Consumer Model
为支持摄取、存储、 实时处理流式数据,EventHub是建立在分区消费模型之上,提高了可用性和并发度;
① 水平扩展事件处理能力,提供了Queue和topic等流式结构不具备的特性(某分区节点下线,其余分区可继续提供 发送和接受能力)
② 可让多进程并发处理流式数据, 并可自行控制处理速度。
③ 支持批量发送事件, 单批次发送不超过1M事件
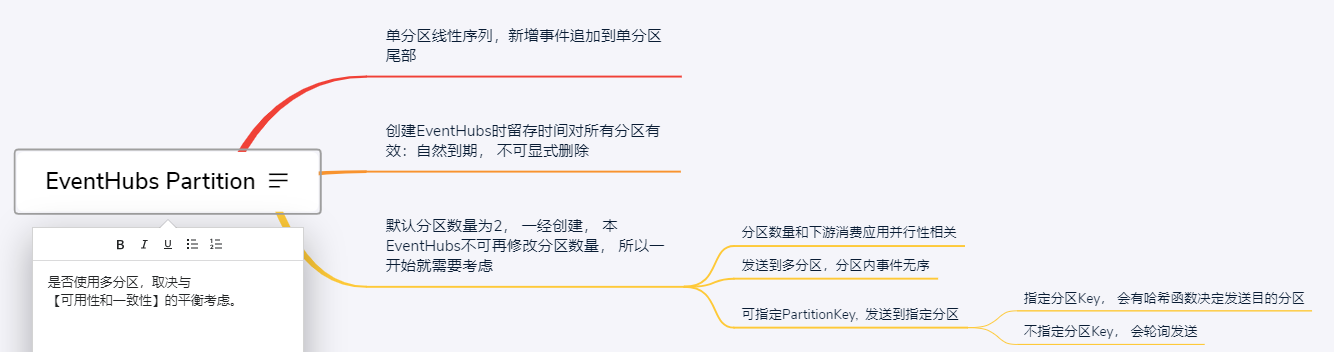
【是否启用分区】取决于开发者在【数据一致性和可用性之间的平衡思考】
If high availability is most important, do not specify a partition key; in that case events are sent to partitions using the round-robin model described previously.
In many cases, using a partition key is a good choice if event ordering is important. 著名的CAP定理。
EventHubs Capture
Azure EventHubs Capture 是把数据加载到Azure中最快捷的方式,可在使用 EventHubs Capture时 指定 Azure Blob storage account 或者 Azure Data Lake Store account存储数据。
捕获时机: 最上面Capture配置图, 捕获时机支持2种策略:time window 和 size window, 每个分区满足任一策略则触发该分区的捕获动作。
// 文件路径如下,包含命名空间、捕获分区,每个文件以秒命名
{Namespace}/{EventHub}/{PartitionId}/{Year}/{Month}/{Day}/{Hour}/{Minute}/{Second}
Azure EventHubs Capture 开始工作之后,在没有数据的情况下默认会写入空文件,这给后端消费程序提供了稳定的流量预期, 当然也可在创建EventHubs 配置勾选【Do not emit empty files when no events occur during the Capture time window<】
捕获文件格式: avro 是一种简洁快速,携带丰富数据结构的二进制格式
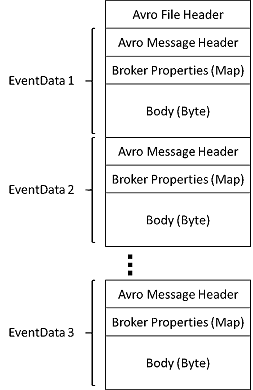
捕获的文件可使用Azure Storage Explorer查看, 注意这里要使用账号登陆Azure中国区, 后面就是 Azure Storage Account的事宜。
本文来自博客园,作者:{有态度的马甲},转载请注明原文链接:https://www.cnblogs.com/JulianHuang/p/11725586.html
欢迎关注我的原创技术、职场公众号, 加好友谈天说地,一起进化


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?