
海柔仿真系统存储实践:混合云架构下实现高可用与极简运维
海柔创新是一家专注于箱式仓储机器人系统的研发和设计的科技公司,其仿真平台通过数字模拟技术,再现实际仓库环境和设备,利用导入的地图、订单、库存及策略配置等数据来验证和优化仓储解决方案,确保设计方案的效率和合理性。
最初,海柔的仿真平台在单机环境中运行,但随着数据量的增长,运维逐渐面临挑战。因此,平台被迁移到私有云的 Kubernetes 环境中,团队随后开始寻找适合在 k8s 环境中运用的分布式文件系统。
仿真平台的数据特征包括:大量小文件、并发写入、跨云架构等。经过对比 Longhorn、Ceph 等多种系统后,海柔科技选择了 JuiceFS。目前,平台的总文件数量为 1100 万、日均写入文件数量 6000 多,以小文件为主,平均文件大小是 3.6KB;同时,Mount Point 数量超过 50个。
01 仿真平台存储挑战:从商用软件到自建
仿真平台(simulator)是基于离散事件引擎的工具平台。它通过底层的数字模拟,对接上层业务系统,在没有实体设备的情况下,达到与实体设备等效的能力。 简单的说 其实仿真平台就是建立了一个虚拟仓库,所有的模拟都是基于这个虚拟仓库来完成的。

传统公司通常使用商业软件,但这些软件无法进行大规模调度或减少计算资源消耗。为此,我们自研了一个仿真平台,涵盖 IaaS、PaaS 等服务。我们的仿真主要是基于离散事件进行,与使用 GPU 的商业软件不同,通过简化计算步骤,优化事件的抽象,显著减少了计算量,甚至可以只使用 CPU 完成倍速仿真的计算任务。
我们的仿真系统主要涵盖几个关键部分:首先是仿真本体,如机器人模拟,包括其运动、旋转和移动速度的逻辑模拟。仿真设备与我们自研的调度系统和 WMS (Warehose Management System)系统直接对接。这也是商业软件所不直接提供的功能。
仿真过程中还包括机械模拟、拣选作业模拟和上游系统环境的业务集成。仿真完成后,会生成大量事件数据,这些数据被记录在小文件中。我们通过这些小文件在另一节点进行存算分离,从而提取和分析这些数据。通过这种方法,我们能够有效地从仿真数据中洞察操作效率和潜在问题,进一步优化系统性能。
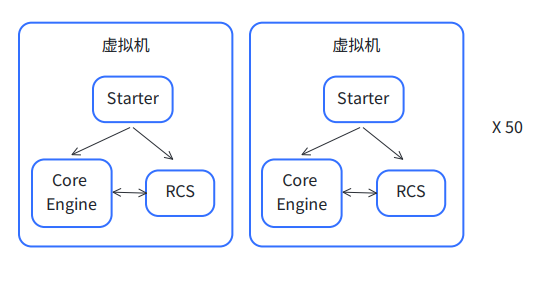
我们的仿真平台一开始是一个纯单机版系统。单机版主要包括一个启动器(starter),核心引擎(core engine,可以类比为一个游戏引擎),它将通过真实的通信协议与真实业务系统 RCS (Robot Control System)连接,从而高度还原现场。
然而,单机版系统存在一些缺点,如原 Core Enging 使用 Python 编写,不能满足单机高并发 IO 的需要,另外当系统扩展至 50 台虚拟机时,运维变得尤为困难。考虑到我们团队的人员数量,这种规模的运维对我们来说是一个巨大的挑战。
02 仿真平台上云:从私有云到混合云架构
单机系统大约持续了 2 年时间,随着数据量的增长,单机系统面临的运维问题日益复杂,于是我们迁移到了 Kubernetes 架构,采用了服务化 (SAAS) 的方式,将所有组件都部署在 K8s 环境中。由此面临,如何在 Kuberenetes 环境中进行存储选型。
K8s 环境存储选型:JuiceFS vs CephFS vs Longhorn
在我们选择分布式文件系统时,性能并不是首要考虑因素,更关键的是如何有效实现跨云网络结构。我们简单评估了 JuiceFS、CephFS 和 Longhorn。
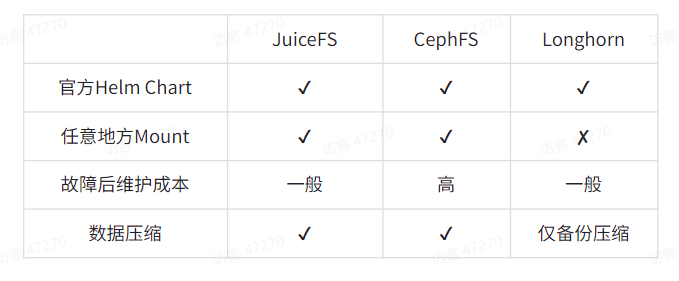
Longhorn 仅支持单集群内文件共享,需要先打通 Kubernetes 的多云集群网络通信,这对我们来说运维成本繁琐。而 CephFS 对于我们这种小规模团队来说,存在过高的维护难度。
因此,我们选择了 JuiceFS,主要因为它的运维特别简单,非常适合小团队使用。JuiceFS 的即插即用特性意味着即使是初学者也能轻松上手,几乎不会遇到大问题,这降低了运营风险。此外,自从部署以来,JuiceFS 未出现过任何故障,这一点非常值得赞扬。
目前 JuiceFS 使用规模方面,过去六个月我们处理了大约 1,100 万个文件。我们每半年会进行一次数据清洗,删除不再需要的数据,因此总数据量不会继续增加。日均写入大约是 6.4k 个文件,平均每日总文件数量为 6 万个,文件大小介于 5kB 到 100kB 之间。日均数据写入量约为 5GB,最高可达 8GB。我们计划将并发写入量逐步扩展至 50 个。
在私有云 K8s 环境中搭建仿真平台
2023 年中,我们开始在 K8s 环境中搭建仿真平台。当系统扩展到 1000 台机器人时,我们发现 Python的 IO 处理能力不足以支撑。因此,我们采用了 Go 语言,这一改变显著提升了系统的 IO 性能,使得单机可以轻松支持超过 1 万台机器人的并发操作。
整个系统的文件处理特征为小文件的高并发写入,当前的并发级别为 50,能够满足了我们的需求。
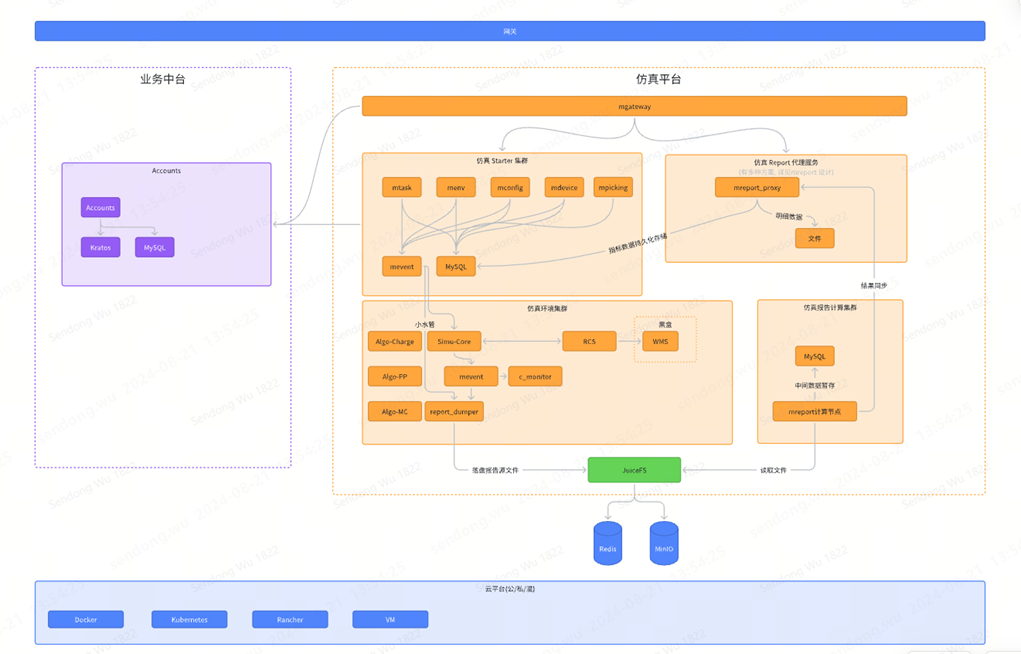
最近,我们将系统从单体架构转变为微服务架构。这一转变解决了原有团队代码混杂和耦合的问题,确保各个服务间代码的独立性,从而提升了系统的可维护性和扩展性。
我们还实施了存算分离的策略,在仿真节点通过使用 JuiceFS 写入仿真过程数据小文件,并在写入结束时重命名为 *.fin 文件;当另一个分析计算节点实时发现 *.fin 文件并开始计算,从而实现隔离仿真与分析的存算分离,避免 CPU 抢占造成仿真过程失真。
混合云 SaaS 仿真服务
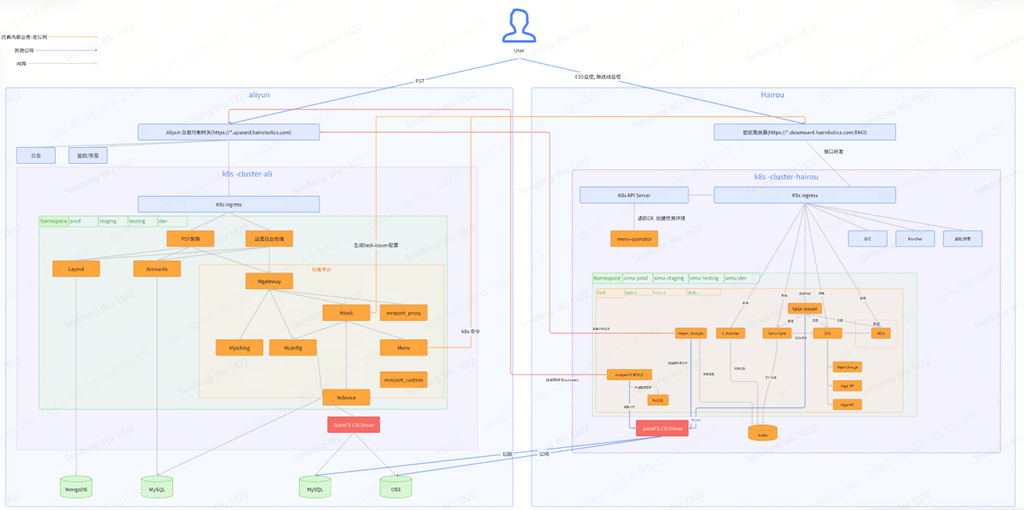
在私有云 K8s 环境中,我们的团队需要管理众多组件,如 MySQL、OSS 等,为了解决资源和精力分散的问题,我们在 2024 年 1 月开始转向混合云 SaaS 解决方案,并选择将存储服务迁移到阿里云。对于小团队来说,如果条件允许,我建议尽量利用公有云服务,特别是在存储方面,因为数据安全是基本需求,不能有失误。
我们采用了阿里云的 OSS 和 MySQL 服务,在两个集群间实现数据共享。这种配置不仅提升了数据处理的效率,还带来了成本效益和灵活性的优势。例如,当本地数据中心的机器资源不足时,利用 JuiceFS 天然的跨云存储能力,在这个架构下,我们可以轻松地从任意云厂商租用机器弹性伸缩集群以满足需求,从而实现成本节约。
03 使用 JuiceFS 踩过的坑
在迁移到云端之前,我们本地使用 Redis 和 Minio 运行得很好,因为我们拥有充足的内存和存储空间,这样就不会出现性能问题。然而,迁移到云端后,遇到了一些问题。
默认的缓存过大,导致 Pod 驱逐
默认的缓存大小设为 100GB,而标准阿里云服务器通常配备的磁盘只有 20GB。这种配置不匹配会导致 Pod 被驱逐,因为缓存过大超出了实际可用磁盘空间。
混合云场景下 storageClasses 的 bucket 设置问题
在实现跨云功能时,尽管官方文档可能推荐使用内网,实际操作表明应当使用外网地址,特别是在使用容器存储接口(CSI)时。默认情况下,第一个执行的操作是格式化 Pod(format pod),它会将当前的配置参数写入数据库。如果其他节点未指定 bucket 设置并依赖于数据库中的这一设置,使用内网地址可能导致外网访问失败。
对象存储占用空间比实际多
尽管阿里云账户下我们有 6TB 的存储空间,实际使用中发现只存储了大约 1.27TB 数据,对象存储占用的空间明显膨胀,远超实际数据量。这可能是由于缺乏自动垃圾回收(GC)处理。因此,我们必须定期手动执行 GC 操作,以减少存储占用。
04 未来展望
我们计划在云端实现弹性伸缩,采用混合平台策略,并推出高速版服务。目前,我们在机器学习领域的高效仿真已经取得显著进展,成功实现了仿真倍速提升至 100 倍。
为了进一步提升效率,我们计划完善整个系统的闭环管理。由于我们的仿真系统已经能够生成大量数据,这些数据理应被充分利用,通过机器学习训练来完善闭环系统,实现数据的最大化利用。这将极大地增强我们系统的智能化和自动化水平。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号