
一文详解 JuiceFS 读性能:预读、预取、缓存、FUSE 和对象存储
在高性能计算场景中,往往采用全闪存架构和内核态并行文件系统,以满足性能要求。随着数据规模的增加和分布式系统集群规模的增加,全闪存的高成本和内核客户端的运维复杂性成为主要挑战。
JuiceFS,是一款全用户态的云原生分布式文件系统,通过分布式缓存大幅提升 I/O 吞吐量,并使用成本较低的对象存储来完成数据存储,适用于大规模 AI 业务。
JuiceFS 数据读取流程从客户端的读请求开始,然后再经过 FUSE 发送给 JuiceFS 客户端,通过预读缓冲层,接着进入缓存层,最终访问对象存储。为了提高读取效率,JuiceFS 在其架构设计中采用了包括数据预读、预取和缓存在内的多种策略。
本文将详细解析这些策略的工作原理,并分享我们在特定场景下的测试结果,以便读者深入理解 JuiceFS 的性能优势及一些相关的限制,从而更有效地应用于各种使用场景。
鉴于文章内容的深度和技术性,需要读者有一定操作系统知识,建议收藏以便在需要时进行仔细阅读。
01 JuiceFS 架构简介
JuiceFS 社区版架构分为客户端、数据存储和元数据三部分。 数据访问支持多种接口,包括 POSIX 、HDFS API、S3 API,还有 Kubernetes CSI,以满足不同的应用场景。在数据存储方面,JuiceFS 支持几十种对象存储,包括公共云服务和自托管解决方案,如 Ceph 和 MinIO。元数据引擎支持多种常见的数据库,包括 Redis、TiKV 和 MySQL 等。
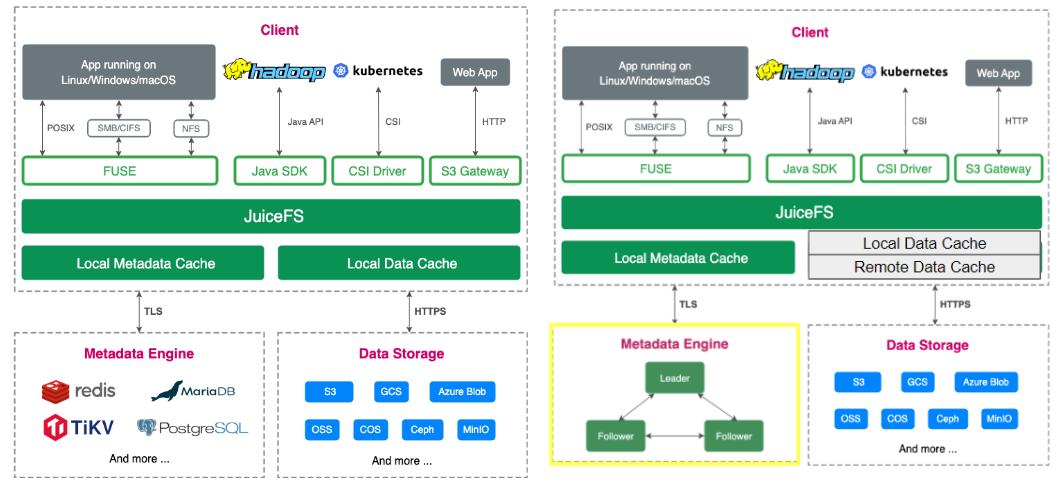
企业版与社区版的主要区别在图片左下角元数据引擎和数据缓存的处理。企业版包括一个自研的分布式元数据引擎,并支持分布式缓存,社区版只支持本地缓存。
02 Linux 中关于“读”的几个概念
在 Linux 系统中,数据读取主要通过几种方式实现:
- Buffered I/O:这是标准的文件读取方式,数据会通过内核缓冲区,并且内核会进行预读操作,以优化读取效率;
- Direct I/O:允许绕过内核缓冲区直接进行文件 I/O 操作,以减少数据拷贝和内存占用,适合大量数据传输;
- Asynchronous I/O:通常与 Direct I/O 一起使用。它允许应用程序在单个线程中发出多个 I/O 请求,而不必等待每个请求完成,从而提高 I/O 并发性能;
- Memory Map:将文件映射到进程的地址空间,可以通过指针直接访问文件内容。通过内存映射,应用程序可以像访问普通内存一样访问映射的文件区域,由内核自动处理数据的读取和写入。
几种主要的读取模式及它们对存储系统带来的挑战:
- 随机读取,包括随机大 I/O 读和随机小 I/O 读,主要考验存储系统的延迟和 IOPS。
- 顺序读取,主要考验存储系统的带宽。
- 大量小文件读取,主要考验存储系统的元数据引擎的性能和系统整体的 IOPS 能力。
03 JuiceFS 读流程原理解析
JuiceFS 采用了文件分块存储的策略。 一个文件首先逻辑上被分割成若干个 chunk,每个 chunk 固定大小为 64MB。每个 chunk 进一步被细分为若干个 4MB 的 block,block 是对象存储中的实际存储单元,JuiceFS 的设计中有不少性能优化措施与这个分块策略紧密相关。(进一步了解 JuiceFS 存储模式)。 为了优化读取性能, JuiceFS 采取了预读、预取与缓存等多种优化方案。
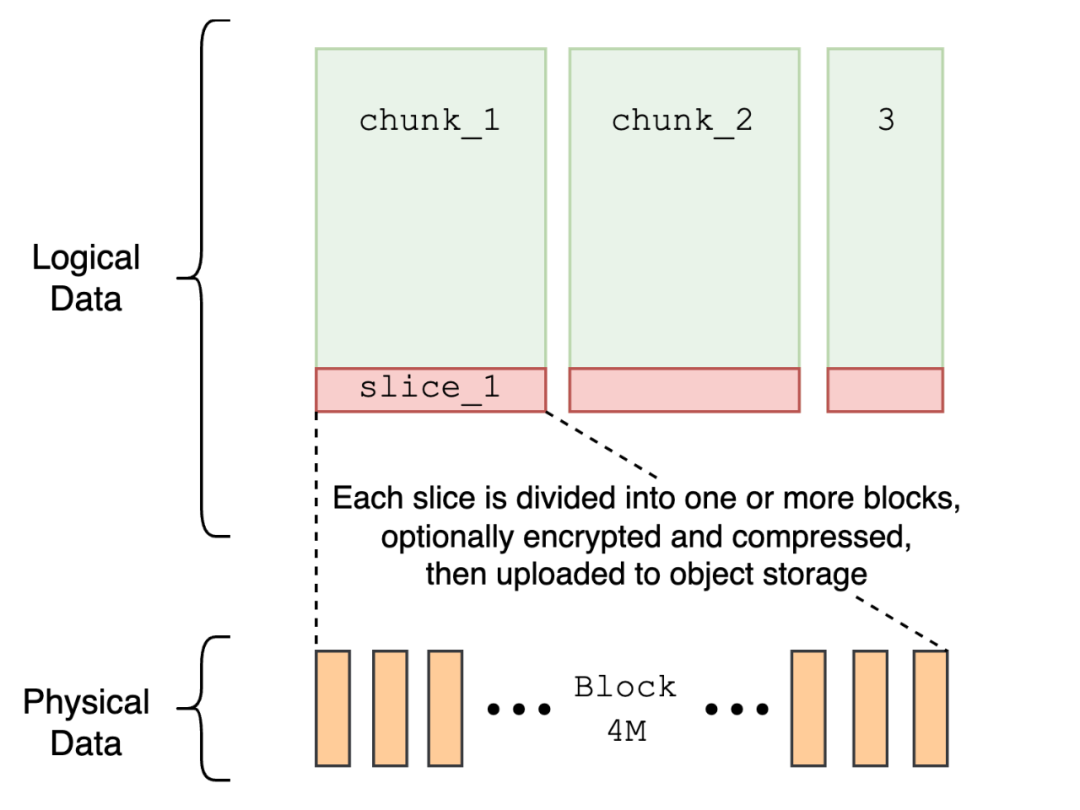
预读 readahead
预读(readahead):通过预测用户未来的读请求,提前从对象存储中加载数据到内存中,以降低访问延迟,提高实际 I/O 并发。下面这张图是一张简化的读取流程的示意图。虚线以下代表应用层,虚线以上是内核层。
当用户进程(左下角标蓝色的应用层) 发起文件读写的系统调用时,请求首先通过内核的 VFS,然后传递给内核的 FUSE 模块,经过 /dev/fuse 设备与 JuiceFS 的客户端进程通信。
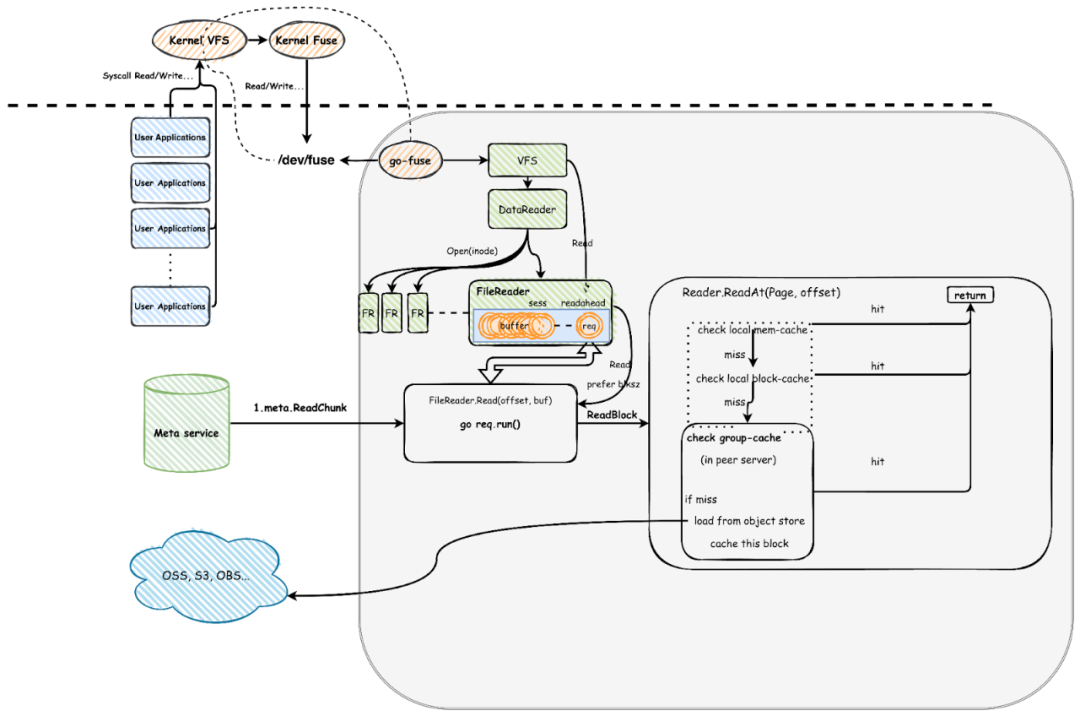
右下角所示的流程是后续在 JuiceFS 中进行的预读优化。系统通过引入“session” 跟踪一系列连续读。每个 session 记录了上一次读取的偏移量、连续读取的长度以及当前预读窗口大小,这些信息可用于判断新来的读请求是否命中这个 session,并自动调整/移动预读窗口。 通过维护多个 session,JuiceFS 还能轻松支持高性能的并发连续读。
为了提升连续读的性能,在系统设计中,我们增加了提升并发的措施。具体来说,预读窗口中的每一个 block (4MB) 都会启动一个 goroutine 来读数据。 这里需要注意的是,并发数会受限于 buffer-size 参数。在默认 300MB 设置下,理论最大对象存储并发数为 75(300MB 除以 4MB),这个设置在一些高性能场景下是不够的,用户需要根据自己的资源配置和场景需求去调整这个参数,下文中我们也对不同参数进行了测试。
以下图第二行为例,当系统接收到连续的第二个读请求时,实际上会发起一个包含预读窗口和读请求的连续三个数据块的请求。按照预读的设置,接下来的两个请求都会直接命中预读的 buffer 并被立即返回。
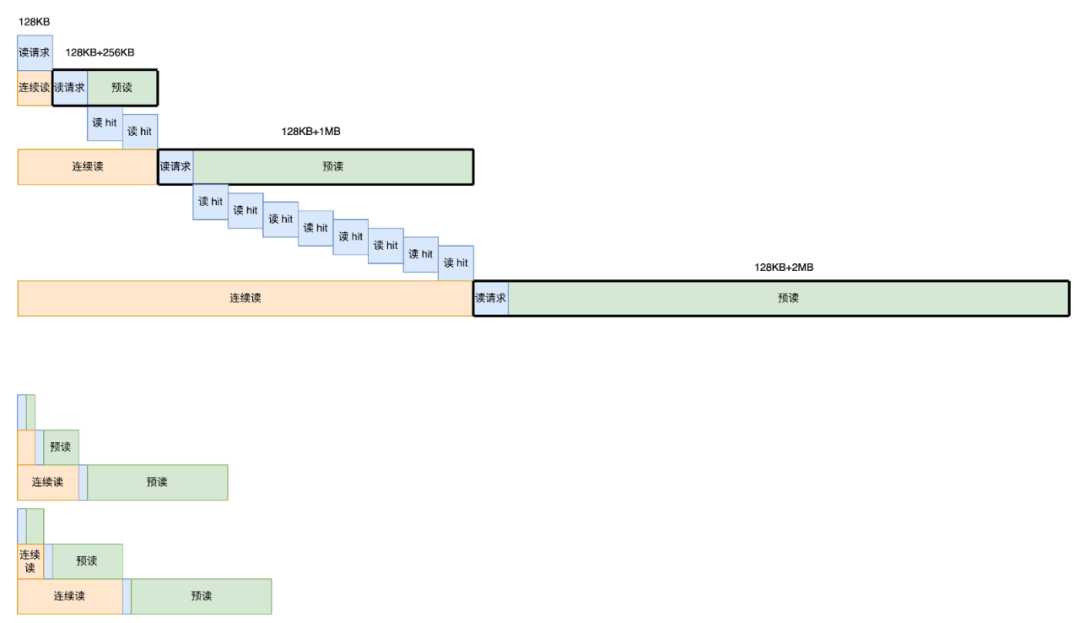
如果第一个和第二个请求没有被预读,而是直接访问对象存储,延迟会比较高(通常大于10ms)。而当延迟降低在 100 微秒以内,则说明这个 I/O 请求成功使用了预读,即第三个和第四个请求,直接命中了内存中预读的数据。
预取 prefetch
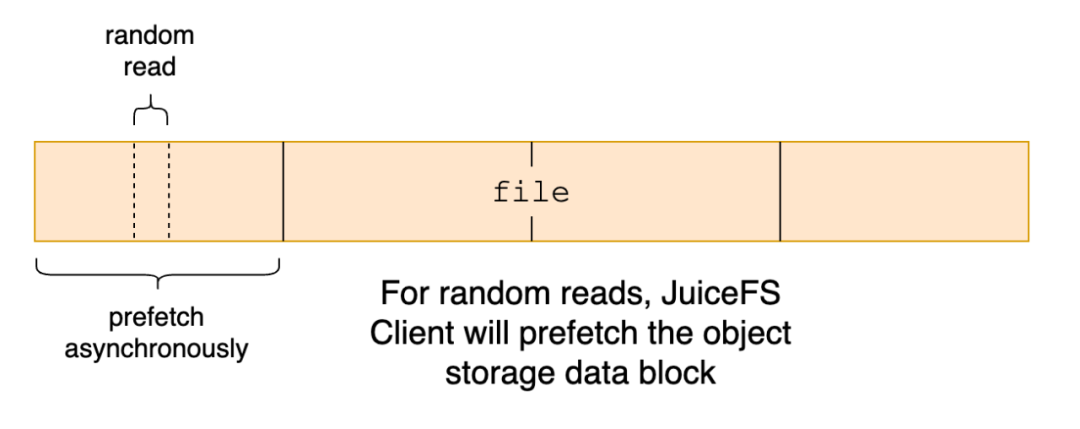
预取(prefetch):当随机读取文件中的一小段数据时,我们假设这段数据附近的区域也可能会被读取,因此客户端会异步将这一小段数据所在的整个 block 下载下来。
但是在有些场景,预取这个策略不适用,例如应用对大文件进行大幅偏移的、稀疏的随机读取,预取会访问到一些不必要的数据,导致读放大。因此,用户如果已经深入了解应用场景的读取模式,并确认不需要预取,可以通过 --prefetch=0 禁用该行为。
缓存 cache
在之前的一次分享中,我们的架构师高昌健详细介绍了 JuiceFS的缓存机制,或查看缓存文档。 在这篇文章中,对于缓存的介绍会以基本概念为主。
页缓存 page cache
页缓存(page cache)是 Linux 内核提供的机制。它的核心功能之一就是预读(readahead),它通过预先读取数据到缓存中,确保在实际请求数据时能够快速响应。
进一步,页缓存(page cache)在特定场景下的应用也非常关键,例如在处理随机读操作时,如果用户能策略性地使用页缓存,将文件数据提前填充至进页缓存,如内存空闲的情况下提前完整连续读一遍文件,可以显著提高后续随机读的性能,从而极大地提升业务整体性能。
本地缓存 local cache
JuiceFS 的本地缓存可以利用本地内存或本地磁盘保存 block,从而在应用访问这些数据时可以实现本地命中,降低网络时延并提升性能。我们通常推荐使用高性能 SSD。数据缓存的默认单元是一个 block,大小为 4MB,该 block 会在首次从对象存储中读取后异步写入本地缓存。
关于本地缓存的配置,如 --cache-dir 和 --cache-size 等细节,企业版用户可以查看文档。
分布式缓存 cache group
分布式缓存是企业版的一个重要特性。与本地缓存相比,分布式缓存将多个节点的本地缓存聚合成同一个缓存池,提高缓存的命中率。但由于分布式缓存增加了一次网络请求,这导致其在时延上通常稍高于本地缓存,分布式缓存随机读延迟一般是 1-2ms,而本地缓存随机读延迟一般是 0.2-0.5ms。关于分布式缓存具体架构,可以查看官网文档。
04 FUSE & 对象存储的性能表现
JuiceFS 的读请求都要经过 FUSE,数据要从对象存储读取,因此理解 FUSE 和对象存储的性能表现是理解 JuiceFS 性能表现的基础。
关于 FUSE 的性能
我们对 FUSE 性能进行了两组测试。测试场景是当 I/O 请求到达 FUSE 挂载进程后,数据被直接填充到内存中并立即返回。测试主要评估 FUSE 在不同线程数量下的总带宽,单个线程平均带宽以及CPU使用情况。硬件方面,测试 1 是 Intel Xeon 架构,测试 2 则是 AMD EPYC 架构。
| Threads | Bandwidth(GiB/s) | Bandwidth per Thread (GiB/s) | CPU Usage(cores) |
|---|---|---|---|
| 1 | 7.95 | 7.95 | 0.9 |
| 2 | 15.4 | 7.7 | 1.8 |
| 3 | 20.9 | 6.9 | 2.7 |
| 4 | 27.6 | 6.9 | 3.6 |
| 6 | 43 | 7.2 | 5.3 |
| 8 | 55 | 6.9 | 7.1 |
| 10 | 69.6 | 6.96 | 8.6 |
| 15 | 90 | 6 | 13.6 |
| 20 | 104 | 5.2 | 18 |
| 25 | 102 | 4.08 | 22.6 |
| 30 | 98.5 | 3.28 | 27.4 |
FUSE 性能测试 1, 基于 Intel Xeon CPU 架构
- 在单线程测试中,最大带宽达到 7.95GiB/s,同时 CPU 使用量不到一个核;
- 随着线程数增加,带宽基本实现线性扩展,当线程数增加到 20 时,总带宽增加到 104 GiB/s;
此处,用户需要特别注意的是,相同 CPU 架构下使用不同硬件型号、不同操作系统测得的 FUSE 带宽表现都有可能不同。我们使用过多种机型进行测试,在其中一种机型上测得的最大单线程带宽仅为 3.9GiB/s。
| Threads | Bandwidth(GiB/s) | Bandwidth per Thread (GiB/s) | CPU Usage(cores) |
|---|---|---|---|
| 1 | 3.5 | 3.5 | 1 |
| 2 | 6.3 | 3.15 | 1.9 |
| 3 | 9.5 | 3.16 | 2.8 |
| 4 | 9.7 | 2.43 | 3.8 |
| 6 | 14.0 | 2.33 | 5.7 |
| 8 | 17.0 | 2.13 | 7.6 |
| 10 | 18.6 | 1.9 | 9.4 |
| 15 | 21 | 1.4 | 13.7 |
FUSE 性能测试 2, 基于 AMD EPYC CPU 架构
- 在测试 2 中,带宽不能线性扩展,特别是当并发数量达到 10 个时,每个并发的带宽不足 2GiB/s;
在多并发情况下,测试 2( EPYC 架构)带宽峰值约为 20GiBps;测试 1(Intel Xeon 架构)表现出更高的性能空间,峰值通常在 CPU 资源被完全占用后出现,这时应用进程和 FUSE 进程的 CPU 都达到了资源极限。
在实际应用中,由于各个环节的时间开销,实际的 I/O 性能往往会低于上述测试峰值 3.5GiB/s。例如,在模型加载的场景中,加载 pickle 格式的模型文件,通常单线程带宽只能达到 1.5 到 1.8GiB/s。这主要是因为读取 pickle 文件的同时,要进行数据反序列化,还会遇到 CPU 单核处理的瓶颈。即使是不经过 FUSE,直接从内存读取的情况下,带宽也最多只能达到 2.8GiB/s。
关于对象存储的性能
我们使用 juicefs objbench 工具进行测试,测试涵盖了单并发、10 并发、200 并发以及 800 并发的不同负载。用户需要注意的是,不同对象存储的性能差距可能很大。
| 上传带宽 upload objects- MiB/s | 下载带宽 download objects MiB/s | 上传平均耗时 ms/object | 下载平均耗时 ms/object | |
|---|---|---|---|---|
| 单并发 | 32.89 | 40.46 | 121.63 | 98.85ms |
| 10 并发 | 332.75 | 364.82 | 10.02 | 10.96 |
| 200 并发 | 5590.26 | 3551.65 | 067 | 1.13 |
| 800 并发 | 8270.28 | 4038.41 | 0.48 | 0.99 |
当我们增加对象存储 GET 操作的并发数到 200 和 800 后,才能够达到非常高的带宽。这说明直接从对象存储上读数据时,单并发带宽非常有限,提高并发对整体的带宽性能至关重要。
05 连续读与随机读测试
为了给大家提供一个直观的基准参考,我们使用 fio 工具测试了 JuiceFS 企业版在连续读取和随机读场景下的性能。
连续读
从下图可以看到 99% 的数据都小于 200 微秒。在连续读场景下,预读窗口总能很好地发挥作用,因此延迟很低。
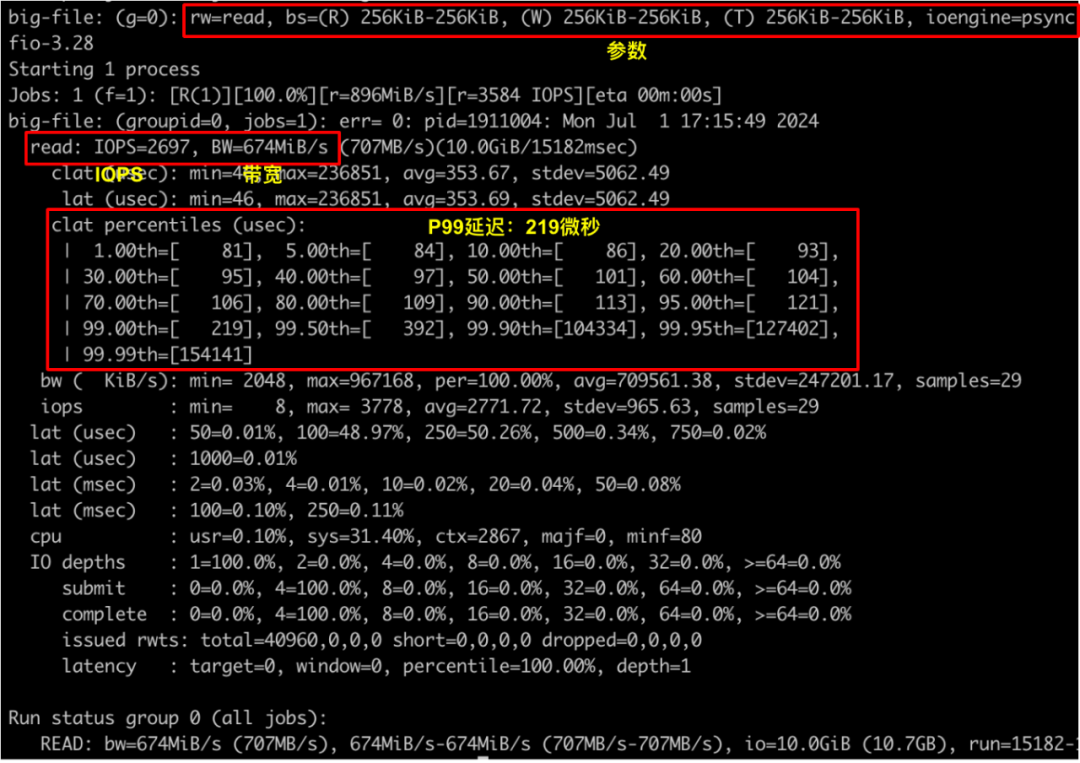
同时,我们也能通过加大预读窗口,以提高 I/O 并发,从而提升带宽。当我们将 buffer-size 从默认 300MiB 调整为 2GiB 后,读并发不再受限,读带宽从 674MiB/s 提升到了 1418 MiB/s,此时达到单线程 FUSE 的性能峰值,进一步提高带宽需要提高业务代码中 I/O 并发度。
| buffer-size | 带宽 |
|---|---|
| 300MiB | 674MiB/s |
| 2GiB | 1418MiB/s |
不同 buffer-size 带宽性能测试(单线程)
当提高业务线程数到 4 线程时,带宽能达到 3456MiB/s;16 线程时,带宽达到了 5457MiB/s,此时网络带宽已经达到饱和。
| buffer-size | 带宽 |
|---|---|
| 1线程 | 1418MiB/s |
| 4线程 | 3456MiB/s |
| 16线程 | 5457MiB/s |
不同线程数量下带宽性能测试 (buffer-size:2GiB)
随机读
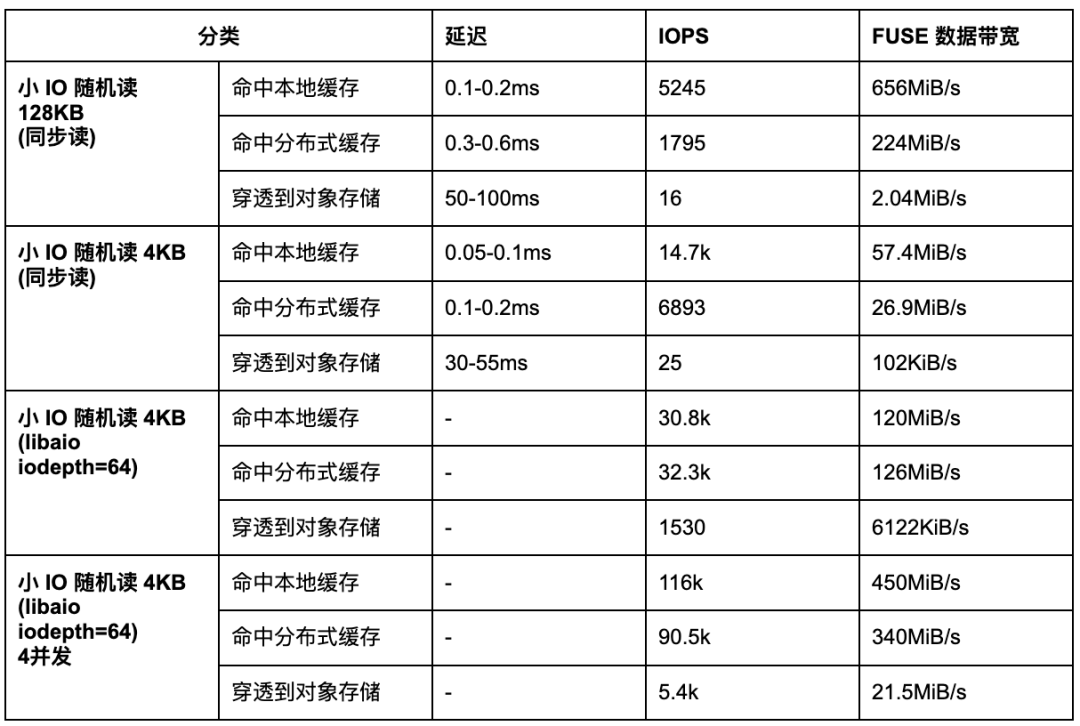
对于小 I/O 随机读,其性能主要由延迟和 IOPS 决定,由于总 IOPS 能够通过增加节点线性扩展,所以我们先关注单节点上的延迟数据。
“FUSE 数据带宽”是指通过 FUSE 层传输的数据量,代表用户应用实际可观察和操作的数据传输速率;“底层数据带宽”则指的存储系统本身在物理层或操作系统层面处理数据的带宽。
从表格中可以看到与穿透到对象存储相比,命中本地缓存和分布式缓存的情况下,延迟都更低,当我们需要优化随机读延迟的时候就需要考虑提高数据的缓存命中率。同时,我们也能看到使用异步 I/O 接口及提高线程数可以大大提高 IOPS。
不同于小 I/O 的场景,大 I/O 随机读场景还要注意读放大问题。如下表所示,底层数据带宽高于 FUSE 数据带宽,这是因为预读的作用,实际的数据请求会比来自于应用的数据请求多1-3倍,此时可以尝试关闭 prefetch 并调整最大预读窗口来调优。
| 分类 | FUSE 数据带宽 | 底层数据带宽 |
|---|---|---|
| 1MB buffered IO | 92MiB | 290MiB |
| 2MB buffered IO | 155MiB | 435MiB |
| 4MB buffered IO | 181MiB | 575MiB |
| 1MB direct IO | 306MiB | 306MiB |
| 2MB direct IO | 199MiB | 340MiB |
| 4MB direct IO | 245MiB | 735MiB |
JuiceFS(开启分布式缓存) 大 I/O 随机读测试结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号