
BentoML:如何使用 JuiceFS 加速大模型加载
BentoML 是一个开源的大语言模型(LLM) AI 应用的开发框架和部署工具,致力于为开发者提供最简单的构建大语言模型 AI 应用的能力,其开源产品已经支持全球数千家企业和组织的核心 AI 应用。
当 BentoML 在 Serverless 环境中部署模型时,其中一个主要挑战是冷启动慢,尤其在部署大型语言模型时更为明显。由于这些模型体积庞大,启动和初始化过程耗时很长。此外,由于 Image Registry 的带宽较小,会让大体积的 Container Image 进一步加剧冷启动缓慢的问题。为了解决这一问题,BentoML引入了JuiceFS。
JuiceFS 的 POSIX 兼容性和数据分块使我们能够按需读取数据,读取性能接近 S3 能提供的性能 的上限,有效解决了大型模型在 Serverless 环境中冷启动缓慢的问题。使用 JuiceFS 后,模型加载速度由原来的 20 多分钟缩短至几分钟。在实施 JuiceFS 的过程中,我们发现实际模型文件的读取速度与预期基准测试速度存在差异。通过一系列优化措施,如改进数据缓存策略和优化读取算法,我们成功解决了这些挑战。在本文中,我们将详细介绍我们面临的挑战、解决方案及相关优化。
01 BentoML 简介以及 Bento 的架构
在介绍模型部署环节的工作之前,首先需要对 BentoML 是什么以及它的架构做一个简要的介绍。
BentoML 是一个高度集成的开发框架,采用简单易用的方式,支持以开发单体应用的方式进行开发,同时以分布式应用的形式进行部署。这意味着开发者可以用很低的学习成本来快速开发一个高效利用硬件资源的大语言模型 AI 应用。BentoML 还支持多种框架训练出来的模型,包括 PyTorch、TensorFlow 等常用 ML 框架。起初,BentoML 主要服务于传统 AI 模型,但随着大型语言模型的兴起,如 GPT 的应用,BentoML 也能够服务于大语言模型。
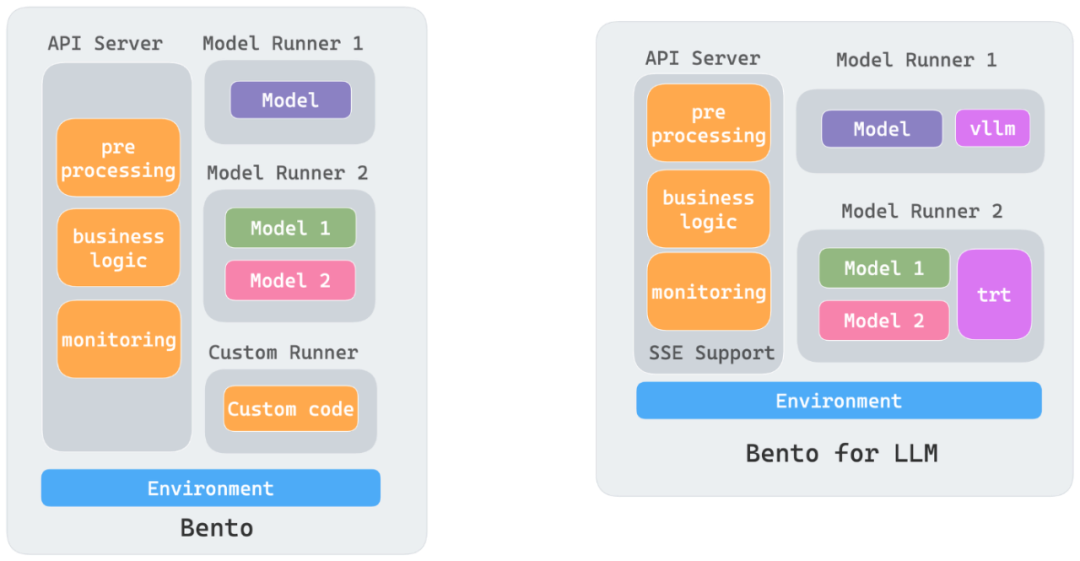
BentoML 产生的制品称为 Bento,Bento 的角色类似于 Container Image,是用于 AI 应用部署的最基本单位,一个 Bento 可以轻松部署在不同的环境中,比如 Docker、EC2、AWS Lambda、AWS SageMaker、Kafka、Spark、Kubernetes。
一个 Bento 包含了业务代码、模型文件、静态文件,同时我们抽象出来了 API Server 和 Runner 的概念,API Server 是流量的入口,主要承载一些 I/O 密集型的任务,Runner 通常是执行模型的推理工作,主要承载一些 GPU/CPU 密集型的任务,从而可以将一个 AI 应用中不同硬件资源需求的任务进行轻松解耦。
BentoCloud 是一个使 Bento 可以部署在云上的平台,一般开发任务分为三个阶段:
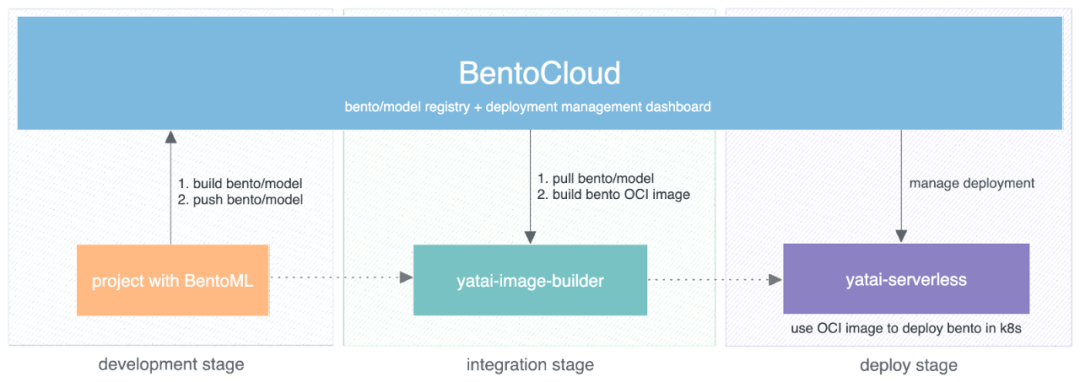
- 第一阶段:开发阶段
当项目使用 BentoML 进行 AI App 开发时,产生制品 Bento。此阶段 BentoCloud 的角色是 Bento Registry。
- 第二阶段:集成阶段
若要将 Bento 部署到云环境中,需要一个 OCI 镜像(Container Image)。在这个阶段,我们有一个组件称为 yatai-image-builder,负责将 Bento 构建成 OCI 镜像,以便后续应用。
- 第三阶段:部署阶段,也是本文的重点内容
这其中一个关键组件是 yatai-serverless。在这个阶段,yatai-serverless 负责将上一阶段构建的 OCI 镜像部署到云上。
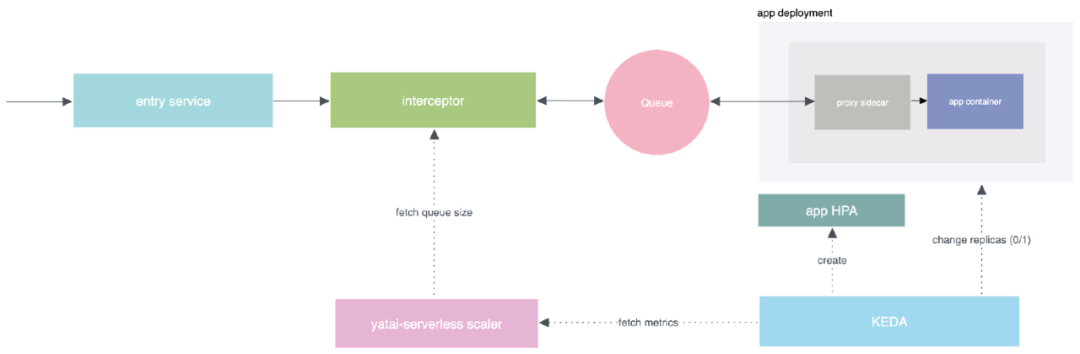
02 Serverless 平台部署大模型的挑战
- 挑战 1:冷启动慢
对于 Serverless 平台而言,冷启动时间至关重要。想象一下,当请求到达时,从零开始增加副本,这可能需要超过 5 分钟。在这段时间内,前面的某些 HTTP 基础设施可能认为已经超时,对用户体验不利。特别是对于大语言模型,其模型文件通常很大,可能达到十几到二十几 GB 的规模,导致在启动时拉取和下载模型的阶段非常耗时,从而显著延长冷启动时间。
- 挑战 2:数据一致性问题
这是 Serverless 平台中特有的问题。我们的平台通过对 Bento 的一些建模解决了这些问题。
- 挑战 3:数据安全性问题
这是将 Bento 部署到云上的主要原因之一,也是 BentoML 提供给用户的核心价值之一。众所周知,OpenAI 以及国内的一些大语言模型会提供一些 HTTP API 供用户使用,但由于许多企业或应用场景对数据安全性有极高的要求,因此他们不可能将敏感数据传递给第三方平台的 API 进行处理。他们希望将大型语言模型部署到自己的云平台上,以确保数据的安全性。
03 为什么使用 JuiceFS ?
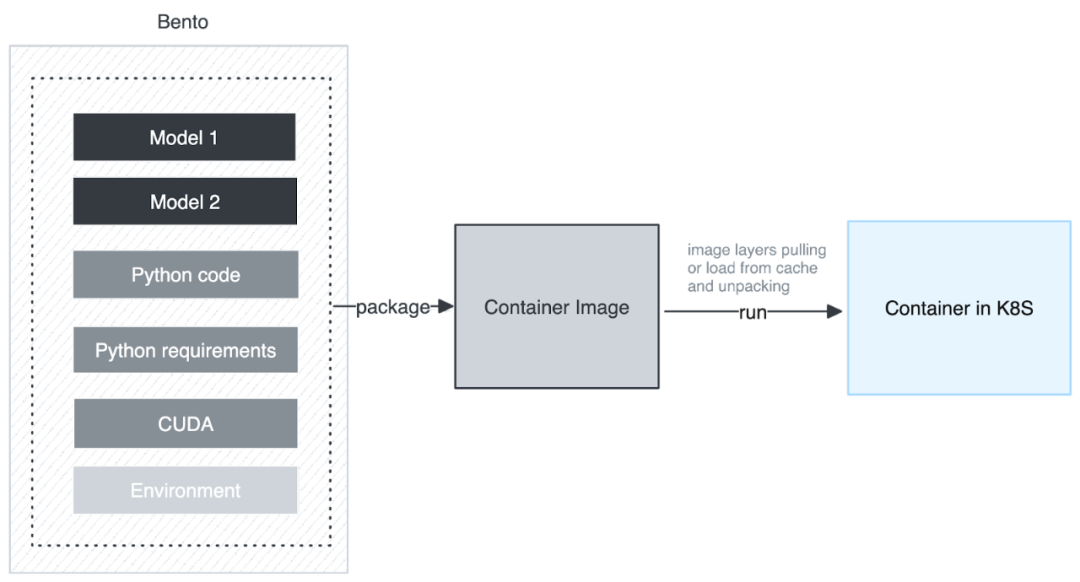
接下来将详细探模型部署这一关键阶段的具体工作。下图展示了我们最初采用的架构,即将所有模型文件,包括 Python 代码、Python 依赖和扩展,都打包成一个 Container Image,然后在 Kubernetes 上运行。然而,这一流程面临着以下挑战:
-
首先,一个 Container Image 由一系列 Layer 组成,因此 Container Image 最小的下载和缓存单位是 Layer,虽然在下载 Container Image 时,Container Image 的 Layer 是并行下载的,但 Layer 在解压的时候是串行的。当解压到模型所在的 Layer 时速度会减慢,同时占用大量的 CPU 时间。
-
另一个挑战是当不同的 Bento 使用相同的模型时。这种架构会浪费多份相同的空间,并且被打包到不同的 Image 中,作为不同 Layer 存在,导致了多次下载和解压,这是极大的资源浪费。因此,这种架构无法共享模型。
在解决这个问题时,我们首选了 JuiceFS,主要因为它具有以下三个优势。
-
首先,它采用 POSIX 协议,无需再加一层抽象就使我们能够以连贯的方式读取数据。
-
其次,它可以达到很高的吞吐,可以接近整个 S3 或 GCS 的带宽。
-
第三,它能够实现良好的共享模型。当我们将模型存储在 JuiceFS 中时,不同实例可以共享同一个大型语言模型。
下图是我们集成 JuiceFS 后的架构。在构建 Container Image 时,我们将模型单独提取并存储到 JuiceFS 中。Container Image 中仅包含用户的 Python 业务代码和 Python 运行所需的依赖和基础环境,这样的设计带来的好处是可以同时下载模型和运行,无需在本地解压模型。整体解压过程变得非常迅速,下载的数据量也大大减少,从而显著提升了下载性能。
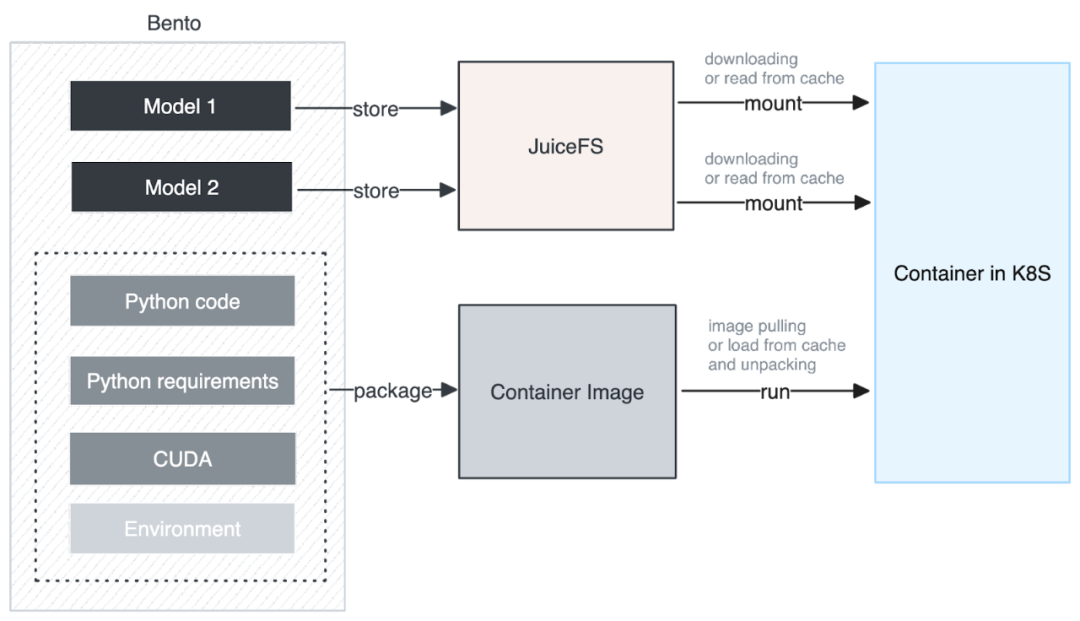
此外,我们进一步优化了下载和缓存的颗粒度,不仅每个模型都有自己的缓存颗粒度,而且 JuiceFS 对大文件分割成了一系列 chunk,以 chunk 为单位进行下载和缓存,利用这个特性可以实现类似于大模型的 Stream Loading 的效果。
我们还充分利用了 GKE 的 Image Streaming 技术。通过 Model Streaming 和 Image Streaming 同时进行数据拉取,我们成功降低了启动时间,提升了整体性能。
04 集成 JuiceFS 时遇到的挑战
- 挑战 1:无缝集成
在引入 JuiceFS 这一新组件时,必须处理如何与已有组件实现无缝集成的问题。这种情况是在任何较为成熟的平台引入新组件时都会遇到的普遍挑战。为了更好地继承 JuiceFS, 我们采用了 AWS MemoryDB,以代替自己运维的 Redis,从而降低架构的复杂度。
- 挑战 2: 引入新组件对业务逻辑的影响
引入 JuiceFS 可能导致业务逻辑的变化。之前,Bento 的容器镜像包含了完整的模型,而现在的 Bento 容器镜像则不再携带模型。在 yatai-serverless 平台的部署中,我们必须在代码层面确保这两种不同的镜像在业务逻辑上实现相互兼容。为此,我们使用不同的 label 来区分不同版本的 bento,然后在代码逻辑里做向前兼容。
- 挑战 3: JuiceFS 下载速度问题
在测试 JuiceFS 时发现,使用 JuiceFS 下载模型的速度非常慢,甚至比直接从镜像中下载还要慢。通过 JuiceFS 团队的协助,我们发现我们的 Boot Disk 是网络磁盘,所以我们一直使用网络磁盘作为 JuiceFS 的缓存盘,这就会导致一个奇怪的现象:不命中缓存时速度更快,一旦命中缓存就变慢。为了解决这个问题,我们为我们的 GKE 环境都添加了 Local NVME SSD,并将 Local NVMe SSD 作为 JuiceFS 的缓存盘,从而完美地解决了这一问题。
05 展望
在未来,我们将深入进行更多的可观测性工作,以确保整个架构保持良好的运行状态,并获得足够的指标以便更好地优化配置,尽量避免再次出现类似的问题。
希望可以高效利用 JuiceFS 自带的缓存能力。例如,将模型提前种植到 JuiceFS 后,这意味着在业务集群中,可以提前在节点中预热模型的缓存,从而进一步提升缓存和冷启动时间的性能。
希望这篇内容能够对你有一些帮助,如果有其他疑问欢迎加入 JuiceFS 社区与大家共同交流。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号