

一个请求的生命周期
1. 一个简单的请求:
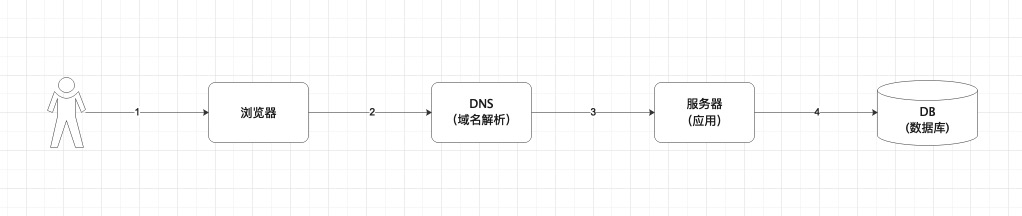
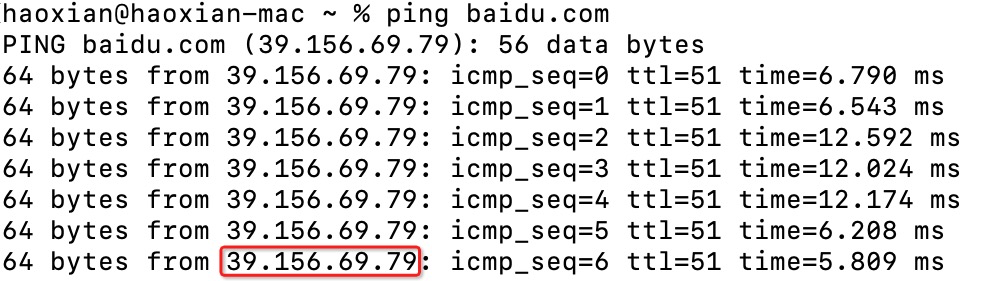
图1 图2
1)田大林在浏览器里输入baidu.com,浏览器会自动加上协议头,变成https://www.baidu.com/,baidu.com属于域名,代表你要访问的服务,http属于协议、标准,解析的规范。
2)域名通过DNS(Domain Name System) 域名解析服务器,置换成一个具体的ip 地址,然后再去请求具体的服务器。
运营商那里有很多服务器,每个服务器分配了一个ip地址,类似于一个地点的经纬度。所以,如果你想申请一个域名,需要去运营商那里申请。他们把你的域名和一个具体服务器绑定,然后你的域名才能使用。域名的好处是方便记忆。
我们通过ping 域名,可以查看域名对应的服务器。例如图2,ping baidu.com ,可以解析出来baidu.com对应的IP地址为:39.156.69.79 。你直接在浏览器里输入这个地址,也可以访问百度。域名的另一个好处是,一个域名可以对应多个服务器。当你的流量特大的时候,
你可以加多个服务器,每次相同域名请求,由不同的服务器来响应请求。不信你试试,每次 ping baidu.com,会得到不一样的ip 。
冷知识:域名解析其实第一步是去本地hosts文件去解析,如果在本地hosts文件中找到了域名对应的IP地址,就不会再去DNS里面解析。如果说有病毒串改了你的hosts文件,你访问某个网址,就会解析出一个错误的IP,进去一个钓鱼网站,输入密码账户的时候,就可能会被坏人记录下来。
3)有个具体IP就可以请求到具体的服务器,这个服务器上有公司提供的应用服务。例如:登录,商品展示,商品详情,购物等。服务上的应用要能知道你具体想要什么,所以如果请求只有域名,会对应一个默认页面。如果想请求其他页面内容,就需要在域名后面,加上其他内容,告诉应用你想干什么。
例如:http://m.news.cctv.com/2020/09/12/ARTIXGzpBgqTJbIeX49tppu6200912.shtml这个地址里面。m.news.cctv.com是域名,后面则是具体路径,路径对应你要请求的具体内容,后端一般称为:接口。
4)应用服务主要做逻辑处理,例如:校验用户是否登录,判断用户请求哪些数据,怎么筛选出符合用户条件的数据等。而数据真正存储的地方,叫:数据库(DB,DataBase)。常用的数据库有:mysql,oracle等。
例如:在数据库有两条记录:1号,田大林,安徽人 …… ;2号,陈小洁,天津人……。田大林登录服务器,应用服务就会根据田大林的信息,加载出田大林在数据库的信息:安徽人,程序员……。而陈小洁登录到服务器后,应用服务就会去加载陈小洁的信息:天津人,设计师……。
应用服务来判断取谁的数据,数据实际存储的地方在数据库。
一个请求,通过浏览器,访问域名解析,请求到具体服务器的具体应用,应用服务根据用户请求内容,分析用户想要的内容,然后从数据库中取出来,返回给浏览器,浏览器解析,展示给用户。这是一个最简单的请求。
2. 一个应用服务划分:

1)前端一般指用户能看到的服务。
HTML:超文本标记语言——HyperText Markup Language,是一种标识性的语言。可以理解成一种标准,所有的浏览器按这种标准来,就可以解析这种样式的文本。
CSS: 层叠样式表(英文全称:Cascading Style Sheets)是一种用来表现HTML等文件样式的计算机语言。例如:第一个页面我把字体设置为:微软雅黑,15号字体,加粗。第二个页面也是。为了避免重复设置,我就可以把这些样式抽取出来,定义一个id(唯一标记)。我在html页面需要设置这种格式的地方,只需要关联一下id,就可以设置成这种样式。如果我想改变样子,只需要改一下id , 或者改一下这个id对应的样式。那么,就可以一次把所有关联的页面样式,全部改变。
JS : JavaScript(简称“JS”) 是一种具有函数优先的轻量级,解释型或即时编译型的高级编程语言。简单理解:页面可以和用户交互,和后端服务交互的功能,一般都是由JS完成的。拖拽、点击等,都是触发了事件,这个事件对应一些列后续操作。
2)后端服务介于前端服务和数据库之间,主要做业务逻辑的处理。本质上前端也可以直接访问数据库,但对于一些复杂业务,如果由前端来进行处理,则每次前端页面都要加载大量数据,引入更多函数,用户体验不好。主流的后端语言有:Java ,go,Python等。
Java是现在最流行的后端开发语言,java语言有个超牛的框架,叫:Spring ,程序员的春天。Spring集成很多能力,我们基于Spring框架开发,可以节省很多时间。
3)数据库:就像一个小本本,记录数据用。主流数据库:mysql , oracle ,db2 等。
3. 进阶
当一个网站有大量用户的时候,对于一个程序员来说,是一个幸福的烦恼。
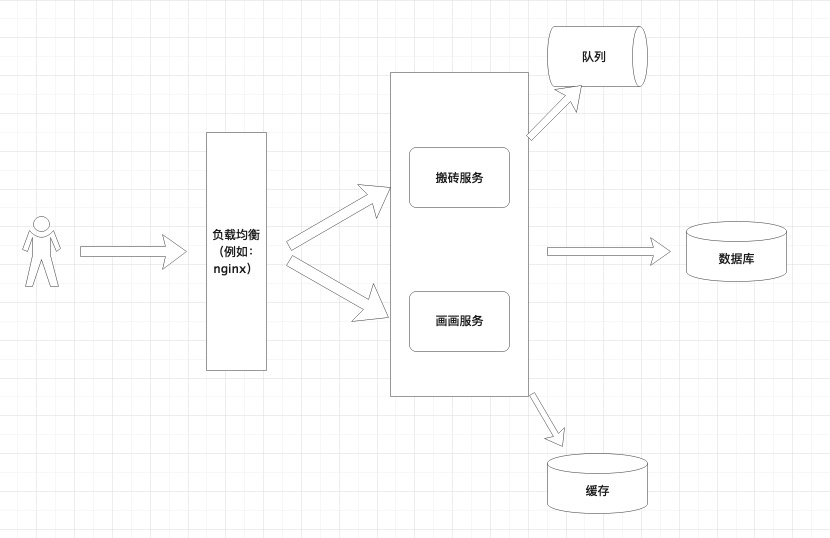
负载均衡:一台服务器的运算能力是有限的。假如一个服务器是一个人,田大林1天只能搬500块砖。如果要1天搬1万块砖怎么办?答:找20个田大林搬砖。负载均衡就是负责给二十个田大林分配任务,看谁闲着,就把任务分配给谁。A客户要100块砖让田大林1号搬过去,B客服要100块砖,让田大林2号搬过去……
负载均衡常用的服务:nginx,LVS等。他们可以根据服务器的地址、响应速度等,决定一次请求发送到哪个服务器。
分布式:两种理解:
1)第一种理解:术业有专攻,假如公司既有搬砖业务,又有画画业务。田大林1天能搬500块砖或者画10幅画,陈小洁一天能画50幅画 或者 搬200块砖。如果只雇佣田大林这种类型人才,可能画画效率不高,只雇佣陈小洁这种类型的人才,可能搬砖效率不高。所以公司考虑将人才分为两组,大林组主要负责搬砖,小洁组主要负责画画。
如果某天公司画画业务多了,只需要多增加小洁组的人。反之,只需要增加大林组的人。让不同组的人,不同组的服务器负责不同的业务,更灵活的调整服务。即使哪天砖被搬完了,公司还可以继续接画画的业务。
2)第二种理解:把一个大的功能拆分成几部分处理。例如:统计全国的GDP。可以拆分成32个任务,32个省市分别计算本省市的GDP,然后汇总到中央进行加和处理。
缓存:缓存是指把一些不会改变、或者请求多、修改少的数据,放到内存里。这样获取的效率更高。假如一个人是一个服务应用,缓存可以理解成人的记忆,我每天上班,这条路线是我常用的、不改变的,我根据记忆就可以找到公司。但如果我要去中国尊大楼,可能就要查查地图,中国尊在哪里,怎么走。
缓存的好处是效率高,反应快。坏处是数据放在内存里,价格贵,成本高,容量有限。并且,如果数据更新不及时,可能会返回错误数据。例如:社保局换地址了,你不知道,还去之前的地方,可能就错了。 所以缓存数据要及时更新,只存储不变的数据,或者变化很少的数据。如果请求能从缓存中拿到想要的数据,效率会大大提高。
常用的缓存:redis。服务器自身也有内存,所以缓存分为:本地缓存和分布式缓存。redis属于分布式缓存。
队列(MQ,Message Queue):队列主要针对短时间有大量用户请求,同时资源有限。例如:田大林卖煎饼,5分钟只能做一个,一下子来了10个买煎饼的。如果一次做10个煎饼,锅里放不下,并且田大林也顾不过来,可能10个煎饼全做糊了。所以田大林,可以给10个客户编个号,先来的是1号客户,然后是2号客户、3号客户…。做完1个煎饼,再做下1个。
假如这时,陈小洁也来买煎饼,着急去上班。田大林和陈小洁关系好,之前给陈小洁办了VIP会员,于是先给陈小洁做煎饼,其他人自动往后排一位。这种根据规则可以插队的队列,称为:优先级队列。
冷知识:12306铁路购票网站,由于短时间内有大量抢票请求,并且票的数量有限,所以也是用了队列功能。我们经常提交完买票请求后,进入一个排队购票……页面。其实是服务器端,在一个个从队列里取出来用户的请求,然后一个个处理。如果车票充足,就购票成功,页面过会变成购票成功页面。如果,车票不足,可能过会页面就会变成购票失败。
4. 名词解释:
1)日志:记录用户的请求、参数、服务器异常等信息的一个服务。一般存储到文本文件中,存储效率高,是程序员的好帮手。主要作用是帮助程序员了解服务的请求状态,有哪些请求,参数是什么,返回是否正常,哪些服务用的比较多,服务器是否有报错,报什么错等等。
2)SQL : 指结构化查询语言,全称是 Structured Query Language。用于访问和处理数据库的标准的计算机语言。
3) BUG : 程序错误,即英文的Bug,也称为缺陷、臭虫,是指在软件运行中因为程序本身有错误而造成的功能不正常、死机、数据丢失、非正常中断等现象。
4) DEBUG: debug是计算机排除故障的意思。有一天,一位技术大牛在调试设备时出现故障,拆开继电器后,发现有只飞蛾被夹扁在触点中间,从而“卡”住了机器的运行。于是,大牛诙谐的把程序故障统称为“臭虫(BUG)”,把排除程序故障叫DEBUG,而这奇怪的“称呼”,竟成为后来计算机领域的专业行话。
5) MD5: 一种加密算法,把你输入内容,转换成另一种固定长度的字符串。例如:你注册一个网站,输入密码。靠谱的网站一般都会把你的密码加密存储,即使黑客拿到数据库数据,也不知道你的密码是什么。而你登录的时候,服务会拿你属于的密码,加密后,跟数据库密码对比,如果一致则登录成功,否则登录失败。
冷知识:由于MD5之前使用太广泛,一些人为了能反推出加密前的内容。于是搞了一张彩虹表,这个彩虹表记录所有加密字符串和对应加密后的密文。这样就可以通过密文,反推出加密前的内容。为了避免反推破译密码,有些服务,会将用户的密码和一个固定的字符串拼接完成以后,再加密存储到数据库。这样即使黑客能反推出加密前的内容,也不知道密码是字符串的哪部分。加字符串后再加密,这个操作被称为:加盐。
6)linux : 一个操作系统,和 Windows类似,一般作为应用服务器系统,效率高,处理能力强。可视化页面不如Windows。Mac 的Mac OS 系统,也是基于linux开发的。
7)7*24 :一周7天,一天24小时。7*24小时不宕机,就是指 程序一直正常运转。
8)分库分表:一个表记录太大,会影响请求效率。可以把一个表拆分成多少个表,但查询的时候,就需要做特殊处理。分库同理,分多个数据库便于管理。
9)主从服务:主服务器提供服务,从服务器备份。如果主服务器挂了,请求可以直接切换到从服务器。
10)读写分离:主数据库只处理写请求,从服务器只处理读请求,这样可以减少数据库加锁。
11)加锁:是指两个修改或者删除请求同时过来,为避免操作顺序导致脏数据,会对数据库加锁,加锁成功的请求,有优先修改数据库的权限。例如:数据库还剩1台手机,两个购买请求,购买成功,数据库手机数量要-1。如果没有锁,请求都判断数据库有1台手机,都进行了-1。数据库手机库存可能就变成了-1。
12)tomcat:应用容器,应用服务一般在tomcat中运行。其他还有jetty等。
其他种种,如:三次握手四次挥手,大数据库Hadoop,ES等,有兴趣,可以自行了解。

