转载https://www.cnblogs.com/kirin365/articles/16457459.html
摘抄华为镜像站
学习内容:
1.K8S与容器的关系
2.存在的原因:
3.集群架构:
4.基本对象
5.弹性伸缩
一.k8s与容器的关系:
Docker提供容器的生命周期管理,Docker镜像构建运行时容器。但是,由于这些单独的容器必须通信,因此使用Kubernetes。因此,我们说Docker构建容器,这些容器通过Kubernetes相互通信。因此,可以使用Kubernetes手动关联和编排在多个主机上运行的容器。
二.k8
1.存在的原因:
Kubernetes是一个很容易地部署和管理容器化的应用软件系统,使用Kubernetes能够
方便对容器进行调度和编排。
Kubernetes可以把大量的服务器看做一台巨大的服务器,在一台大服务器上面运行应
用程序。无论Kubernetes的集群有多少台服务器,在Kubernetes上部署应用程序的方
法永远一样
2.集群架构:master控制节点 node 计算节点
控制节点的组件:
API server :各组件互相通讯的中转站,接受外部请求,并将信息写到ETCD中。
ETCD:一个分布式数据存储组件,负责存储集群的配置信息。
controller Manager : 执行集群级功能,例如复制组件,跟踪Node节点,处理节
点故障等等。
Scheduler:
负责应用调度的组件,根据各种条件(如可用的资源、节点的亲和性
等)将容器调度到Node上运行。
node:
kubectl :kubelet主要负责同Container Runtime打交道,并与API Server交互,
管理节点上的容器。
container runtime: 容器运行时,如Docker,最主要的功能是下载镜像和运行容
器。
kubectl-proxy: 应用组件间的访问代理,解决节点上应用的访问问题。
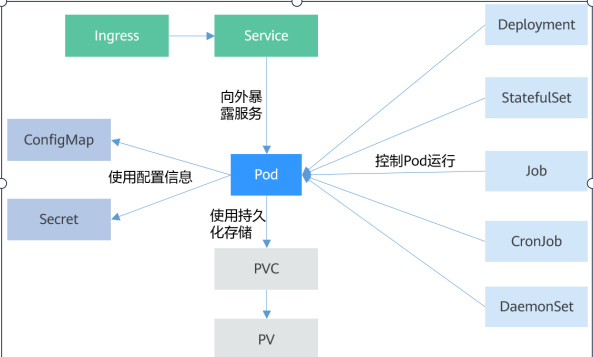
3.基本对象
![]()
pod
label 标签
namespace 命名空间
存活探针(Liveness Probe)
存活探针
Kubernetes提供了自愈的能力,具体就是能感知到容器崩溃,然后能够重启这个容
器。但是有时候例如Java程序内存泄漏了,程序无法正常工作,但是JVM进程却是一
直运行的,对于这种应用本身业务出了问题的情况,Kubernetes提供了Liveness Probe
机制,通过检测容器响应是否正常来决定是否重启,这是一种很好的健康检查机制。
Kubernetes支持如下三种探测机制。
● HTTP GET:向容器发送HTTP GET请求,如果Probe收到2xx或3xx,说明容器是
健康的。
● TCP Socket:尝试与容器指定端口建立TCP连接,如果连接成功建立,说明容器是
健康的。
● Exec:Probe执行容器中的命令并检查命令退出的状态码,如果状态码为0则说明
容器是健康的
deployment:控制pod
Kubernetes提供了Controller(控制器)来管理Pod,Controller可以创建和管理多个
Pod,提供副本管理、滚动升级和自愈能力,其中最为常用的就是Deployment。
怎么控制pod,通过replicaset
Deployment不是直接控制Pod的,Deployment是通过一种名为ReplicaSet的控制器控
制Pod,通过如下命令可以查询ReplicaSet,其中rs是ReplicaSet的缩写。
回滚
回滚也称为回退,即当发现升级出现问题时,让应用回到老的版本。Deployment可以
非常方便的回滚到老版本。
例如升级的新版镜像有问题,可以执行kubectl rollout undo命令进行回滚。
升级
Deployment可以设置不同的升级策略,有如下两种。
● RollingUpdate:滚动升级,即逐步创建新Pod再删除旧Pod,为默认策略。
● Recreate:替换升级,即先把当前Pod删掉再重新创建Pod。
Deployment的升级可以是声明式的,也就是说只需要修改Deployment的YAML定义即
可.Deployment可以通过maxSurge和maxUnavailable两个参数控制升级过程中同时重新
创建Pod的比例
statefulset:
与deployment不同的是: statefulset要求 每个Pod都有自己单独的状态时,对pod的要求:
Pod有固定的标识。
每个Pod有单独存储,Pod被删除恢复后,读取的数据必须还是以前那份,否则状态就会不一致。
StatefulSet 存储状态,StatefulSet可以通过PVC做持久化存储,保证Pod重新调度后还是能访问到相同的持久化数据,在删除Pod时,PVC不会被删除。
Kubernetes提供了StatefulSet来解决这个问题,其具体如下:
1. StatefulSet给每个Pod提供固定名称,Pod名称增加从0-N的固定后缀,Pod重新
调度后Pod名称和HostName不变。
2. StatefulSet通过Headless Service给每个Pod提供固定的访问域名,Service的概念
会在后面章节中详细介绍。
3. StatefulSet通过创建固定标识的PVC保证Pod重新调度后还是能访问到相同的持久
化数据。
job cronjob:
任务:Job和CronJob是负责批量处理短暂的一次性任务,即仅
执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。
● Job:是Kubernetes用来控制批处理型任务的资源对象。批处理业务与长期伺服业
务(Deployment、Statefulset)的主要区别是批处理业务的运行有头有尾,而长
期伺服业务在用户不停止的情况下永远运行。Job管理的Pod根据用户的设置把任
务成功完成就自动退出(Pod自动删除)。
● CronJob:是基于时间的Job,就类似于Linux系统的crontab文件中的一行,在指定的时间周期运行指定的Job。
任务负载的这种用完即停止的特性特别适合一次性任务,比如持续集成。
damonset: 守护进程
DaemonSet跟节点相关,如果节点异常,也不会在其他节点重新创建
DaemonSet中讲到使用nodeSelector选择Pod要部署的节点,其实Kubernetes
还支持更精细、更灵活的调度机制,那就是亲和(affinity)与反亲和(anti-affinity)
调度。
亲和 反亲和 affinity表示亲和,anti-affinity表示节点亲和,
节点优先选择: 是一种强制选择的规则,节点亲和还有一种优先选择规则,
网络
关于k8s的意义:
Kubernetes
本身并不负责网络通信,Kubernetes提供了
容器网络接口CNI(ContainerNetwork Interface),具体的网络通信交给CNI插件来负责.
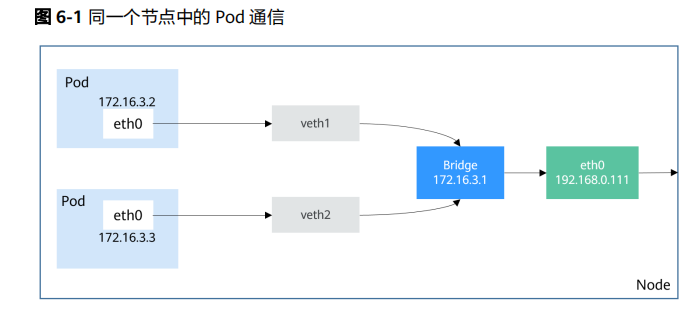
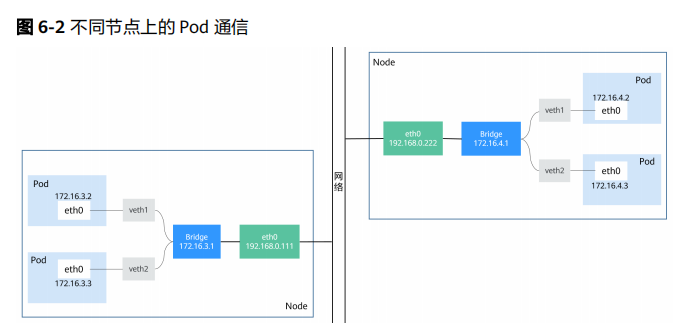
Kubernetes虽然不负责网络,但要求集群中的Pod能够互相通信,且Pod必须通过非NAT网络连接,即收到的数据包的源IP就是发送数据包Pod的IP。
Pod内部是通过虚拟Ethernet接口对(Veth pair)与Pod外部连接,Veth pair就像一根网线,一端留在Pod内部,一端在Pod之外。而同一个节点上的Pod通过网桥(LinuxBridge)通信
![]()
![]()
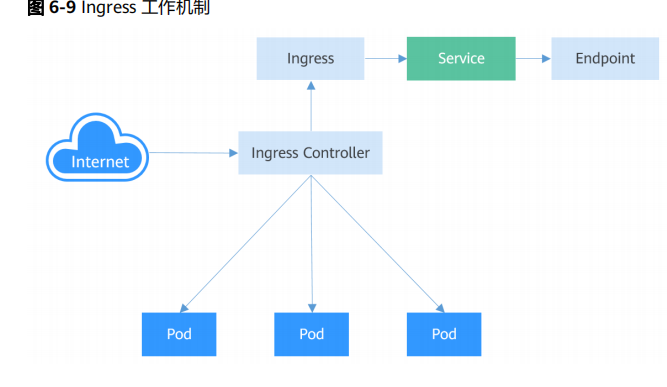
ingress
存在意义:service是基于四层TCP和UDP协议转发的,而Ingress可以基于七层的HTTP和HTTPS协议转发,可以通过域名和路径做到更细粒度的划分,
工作原理:外部请求首先到达Ingress Controller,Ingress Controller根据Ingress的路由规则,查找到对应的Service,进而通过Endpoint查询到Pod的IP地址,然后将请求转发给Pod。
![]()
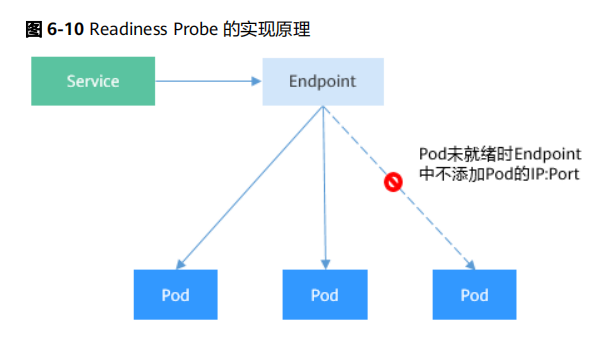
就绪探针(Readiness Probe)
一个Pod启动是需要时间的,如果Pod还没准备好(可能需要时间来加载配置或数据,或者可能需要执行一个预热程序之类),这时把请求转给Pod的话,Pod也无法处理,造成请求失败。
Kubernetes解决这个问题的方法就是给Pod加一个业务就绪探针Readiness Probe,当检测到Pod就绪后才允许Service将请求转给Pod。
Readiness Probe 的工作原理
通过Endpoints就可以实现Readiness Probe的效果,当Pod还未就绪时,将Pod的
IP:Port从Endpoints中删除,Pod就绪后再加入到Endpoints中,
![]()
就绪探针也支持如下三种类型。
● Exec:Probe执行容器中的命令并检查命令退出的状态码,如果状态码为0则说明
已经就绪。
● HTTP GET:往容器的IP:Port发送HTTP GET请求,如果Probe收到2xx或3xx,说
明已经就绪。
● TCP Socket:尝试与容器建立TCP连接,如果能建立连接说明已经就绪。
service:
1.Service相关的事情都由节点上的kube-proxy处理。在Service创建时Kubernetes会分配IP给Service,同
时通过API Server通知所有kube-proxy有新Service创建了,kube-proxy收到通知后通过iptables记录Service和IP/端口对的关系,从而让Service在节点上可以被查询到。
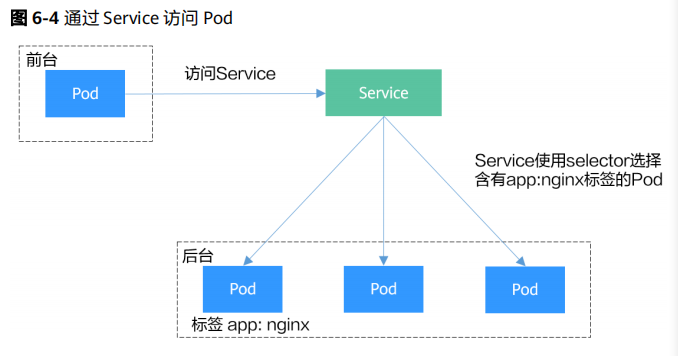
2.Pod创建完成后,如何访问Pod呢?直接访问Pod会有如下几个问题:
● Pod会随时被Deployment这样的控制器删除重建,那访问Pod的结果就会变得不
可预知。
● Pod的IP地址是在Pod启动后才被分配,在启动前并不知道Pod的IP地址。
●应用往往都是由多个运行相同镜像的一组Pod组成,逐个访问Pod也变得不现实
3.使用 Service 解决 Pod 的访问问题
Kubernetes中的Service对象就是用来解决上述Pod访问问题的。Service有一个固定IP
地址(在创建CCE集群时有一个服务网段的设置,这个网段专门用于给Service分配IP地
址),Service将访问它的流量转发给Pod,具体转发给哪些Pod通过Label来选择,而
且Service可以给这些Pod做负载均衡。
4. 发现pod: Kubernetes正是通过Endpoints监控到Pod的IP,从而让Service能够发现Pod。
5. 类型:ClusterIP:用于在集群内部互相访问的场景,通过ClusterIP访问Service。
NodePort:用于从集群外部访问的场景,通过节点上的端口访问Service,
LoadBalancer:用于从集群外部访问的场景,其实是NodePort的扩展,通过一个特定的LoadBalancer访问Service,这个LoadBalancer将请求转发到节点的NodePort,而外部只需要访问LoadBalancer,
NodePort 类型:NodePort类型的Service可以让Kubemetes集群每个节点上保留一个相同的端口, 外部访问连接首先访问节点IP:Port,然后将这些连接转发给服务对应的Pod。
headlessservice:Service解决了Pod的内外部访问问题,但还有下面这些问题没解决。
同时访问所有Pod, 一个Service内部的Pod互相访问,Headless Service正是解决这个问题的
持久化存储:
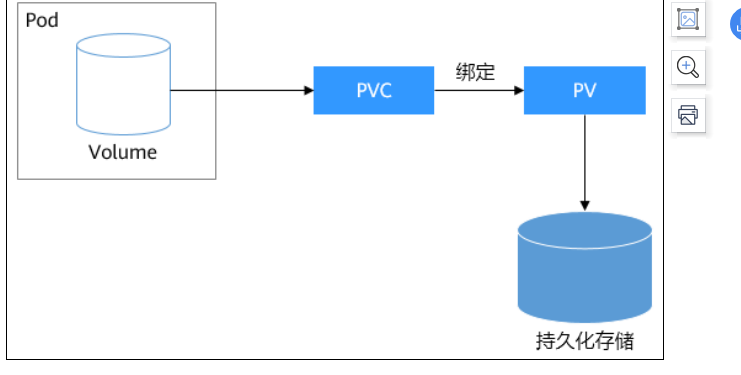
容器存储: volume 存储卷 volume不是单独的对象,不能独立创建,只能在pod中定义。
volume的生命周期与挂载他的pod相同,但是volume里的文件可能在volume消失后仍存在,这取决于volume的类型。
解决的问题: 1 容器中的文件都是临时存储在磁盘上的,容器重建的时,容器中的文件容易丢失
2.一个pod中运行多个容器时,常常这些容器之间需要共享文件,kubectl抽出volume解决这两个问题。
类型:emptyDir:一种简单的空目录,主要用于临时存储。(挂载在容器里面)
hostPath:将主机某个目录挂载到容器中。
configmap . Secret:特殊类型,将Kubernetes特定的对象类型挂载到Pod,
persistentVolumeClaim:Kubernetes的持久化存储类型,PV、PVC和StorageClass中会详细介绍。
网络存储:解决问题 :HostPath是一种持久化存储,但是HostPath的内容是存储在节点上,导致只适合读取。
如果要求Pod重新调度后仍然能使用之前读写过的数据,就只能使用网络存储了,网络存储种类非常多且有不同的使用方法,通常一个云服务提供商至少有块存储、文件存储、对象存储三种,Kubernetes解决这个问题的方式是抽象了PV(PersistentVolume)和PVC(PersistentVolumeClaim)来解耦这个问题,
pv:PV描述的是持久化存储卷,主要定义的是一个持久化存储在宿主机上的目录,比如一个NFS的挂载目录
pvc :PVC描述的是Pod所希望使用的持久化存储的属性,比如,Volume存储的大小、可读写权限等等。
Kubernetes管理员设置好网络存储的类型,提供对应的PV描述符配置到Kubernetes,使用者需要存储的时候只需要创建PVC,然后在Pod中使用Volume关联PVC,即可让Pod使用到存储资源,
![]()
storageclass: PV和PVC方法虽然能实现屏蔽底层存储,但是PV创建比较复杂(可以看到PV中csi字段的配置很麻烦),通常都是由集群管理员管理,这非常不方便.
Kubernetes解决这个问题的方法是提供动态配置PV的方法,可以自动创PV。管理员可
以部署PV配置器(provisioner),然后定义对应的StorageClass,这样开发者在创建
PVC的时候就可以选择需要创建存储的类型,PVC会把StorageClass传递给PV
provisioner,由provisioner自动创建PV。
4.弹性伸缩
kubernets支持Pod和集群节点的自动弹性伸缩,设置自动弹性伸缩规则,当外部条件达到一定时,根据规则自动伸缩pod和集群节点
具备弹性伸缩的条件: 做弹性伸缩,首先就要能感知各种运行数据,例如:集群节点,容器的cpu等,而这些数据的监控能力k8s不能实现,通过prometheus . metrics server 来扩展kubernetes的监控能力。
Prometheus是一套开源的系统监控报警框架,能够采集丰富的Metrics(度量数据),目前已经基本Kubernetes的标准监控方案。
Metrics Server是Kubernetes集群范围资源使用数据的聚合器。Metrics Server从kubelet公开的Summary API中采集度量数据,能够收集包括了Pod、Node、容器、Service等主要Kubernetes核心资源的度量数据,且对外提供一套标准的API。
使用HPA(Horizontal Pod Autoscaler)配合Metrics Server可以实现基于CPU和内存的自动弹性伸缩,再配合Prometheus还可以实现自定义监控指标的自动弹性伸缩。
HPA机制实现:HPA(Horizontal Pod Autoscaler)是用来控制Pod水平伸缩的控制器,HPA周期性检查Pod的度量数据,计算满足HPA资源所配置的目标数值所需的副本数量,进而调整目标资源(如Deployment)的replicas字段。
Cluster AutoScaler
HPA是针对Pod级别的,但是如果集群的资源不够了,那就只能对节点进行扩容了。集群节点的弹性伸缩本来是一件非常麻烦的事情,但是好在现在的集群大多都是构建在云上,云上可以直接调用接口添加删除节点,这就使得集群节点弹性伸缩变得非常方便。
Cluster Autoscaler是Kubernetes提供的集群节点弹性伸缩组件,根据Pod调度状态及资源使用情况对集群的节点进行自动扩容缩容。由于要调用云上接口实现弹性伸缩,这就使得在不同环境上的实现与使用各不相同,



 浙公网安备 33010602011771号
浙公网安备 33010602011771号