
数据结构中的参见排序算法的实现,以及时间复杂度和稳定性的分析(2)
数据结构测参见算法分类如下(图片来源https://www.cnblogs.com/hokky/p/8529042.html)
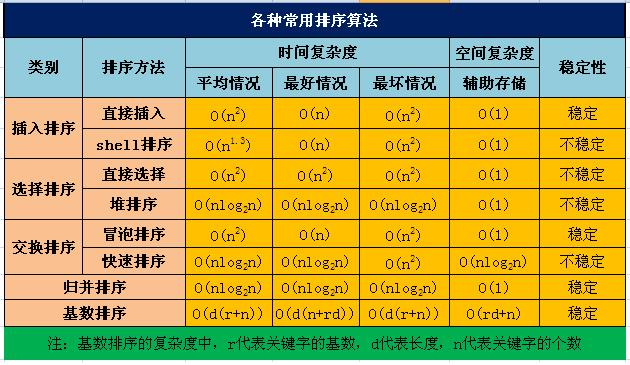
3.直接选择排序:每次查找当前序列中的最小元素,然后与序列头进行交换,再查询剩余序列中的长度,依次类推下去。
代码如下:

#include <iostream> using namespace std; int main() { int s[]={10,9,8,7,6,5,4,3,2,1}; for(int i=0;i<10;i++) { int min=i; for(int j=i+1;j<10;j++) { if(s[j]<s[min]) min=j; } cout<<"s[min]: "<<s[min]<<endl; int temp=s[min]; s[min]=s[i]; s[i]=temp; } for(int i=0;i<10;i++) { cout<<s[i]<<" "; } cout<<endl; return 0; }
不管初始序列是否有序,其时间复杂度都是O(n*2),当两个元素相同时,比如 2,2,3,1,第一次遍历后,会变为1,2,3,2 可见两个2的相对位置发生了改变,所以是不稳定的。
4.堆排序:分为大顶堆和小顶堆,比如大顶堆就是根节点的值是大于其左右子树上元素的值。堆排序(大顶堆)分为两步:第一步是构建初始堆,并将其调整为大顶堆。第二步是将堆顶元素取出,放到序列末尾,再调整堆为大顶堆。一直重复上面两步,直到堆中的元素为空。 代码如下:
#include <iostream> using namespace std; void adjust(int * s,int len,int index) { int left=2*index+1; int right=2*index+2; int maxIndex=index; if(left<len&&s[left]>s[maxIndex]) maxIndex=left; if(right<len&&s[right]>s[maxIndex]) maxIndex=right; if(maxIndex==index) return; int temp=s[maxIndex]; s[maxIndex]=s[index]; s[index]=temp; adjust(s,len,maxIndex); } void heap_sort(int * s,int len) { for(int i=len/2-1;i>=0;i--) { adjust(s,len,i); } for(int i=len-1;i>=1;i--) { int temp=s[i]; s[i]=s[0]; s[0]=temp; adjust(s,i,0); } } int main() { int s[]={10,9,8,7,6,5,4,3,2,1,12,11}; heap_sort(s,12); for(int i=0;i<12;i++) cout<<s[i]<<" "; cout<<endl; return 0; }
第一步构建初始堆(转载于https://blog.csdn.net/loveliuzz/article/details/77618530)
假设高度为k,则从倒数第二层右边的节点开始,这一层的节点都要执行子节点比较然后交换(如果顺序是对的就不用交换);倒数第三层呢,则会选择其子节点进行比较和交换,如果没交换就可以不用再执行下去了。如果交换了,那么又要选择一支子树进行比较和交换;
那么总的时间计算为:s = 2^( i - 1 ) * ( k - i );其中 i 表示第几层,2^( i - 1) 表示该层上有多少个元素,( k - i) 表示子树上要比较的次数,如果在最差的条件下,就是比较次数后还要交换;因为这个是常数,所以提出来后可以忽略;
S = 2^(k-2) * 1 + 2^(k-3)*2.....+2*(k-2)+2^(0)*(k-1) ===> 因为叶子层不用交换,所以i从 k-1 开始到 1;
这个等式求解,我想高中已经会了:等式左右乘上2,然后和原来的等式相减,就变成了:
S = 2^(k - 1) + 2^(k - 2) + 2^(k - 3) ..... + 2 - (k-1)
除最后一项外,就是一个等比数列了,直接用求和公式:S = { a1[ 1- (q^n) ] } / (1-q);
S = 2^k -k -1;又因为k为完全二叉树的深度,所以 (2^k) <= n < (2^k -1 ),总之可以认为:k = logn (实际计算得到应该是 log(n+1) < k <= logn );
综上所述得到:S = n - longn -1,所以时间复杂度为:O(n)
更改堆元素后重建堆时间:O(nlogn)
第二步取出堆顶,不断的调整堆(转载于https://blog.csdn.net/loveliuzz/article/details/77618530)
更改堆元素后重建堆时间:O(nlogn)
推算过程:
1、循环 n -1 次,每次都是从根节点往下循环查找,所以每一次时间是 logn,总时间:logn(n-1) = nlogn - logn ;
综上所述:堆排序的时间复杂度为:O(nlogn)
稳定性分析:比如 1 2 3 4 4,大家可以自己调整,当取出堆顶元素时,两个4的相对位置会发生改变。
5.冒泡排序:每次遍历确定当前序列的最大值,知道所有元素都已完成遍历为止。
代码如下:
#include <iostream> using namespace std; int main() { int s[]={10,9,8,7,6,5,4,3,2,1,12,11}; for(int i=0;i<12;i++) { for(int j=0;j<12-i-1;j++) { if(s[j]>s[j+1]) { int temp=s[j]; s[j]=s[j+1]; s[j+1]=temp; } } } for(int i=0;i<12;i++) { cout<<s[i]<<" "; } cout<<endl; return 0; }
时间复杂度:如序列是有序的,那么每次都不用交换,此时时间复杂度为O(n);如果序列是逆序的,那么每次遍历都要逐个比较并交换,此时的时间复杂度为O(n*2)。
稳定性:分析比较过程可以知道,算法是稳定的。
6.快速排序:就是每次选择一个分割标准flag,小于flag的值放在左边,大于等于flag的值放在右边
代码如下:
#include <iostream> using namespace std; void quickSort(int * s,int i,int j) { int end=j; if(i>j) return; int flag=s[i]; while(i<j) { while(j>i&&s[j]>=flag) j--; if(j>i) { s[i]=s[j]; i++; } while(i<j&&s[i]<flag) i++; if(j>i) { s[j]=s[i]; j--; } } cout<<"i: "<<i<<" j: "<<j<<endl; s[i]=flag; cout<<"flag "<<flag<<": "; for(int ii=0;ii<=9;ii++) { cout<<s[ii]<<" "; } cout<<endl; quickSort(s,0,i-1); quickSort(s,i+1,end); } int main() { int s[]={10,9,8,7,6,1,2,3,4,5}; quickSort(s,0,9); for(int i=0;i<10;i++) { cout<<s[i]<<" "; } cout<<endl; return 0; }
时间复杂度:
如果每次划分都能将序列平分为两半,此时f(n)=2*f(n/2)+n=.....=(k^2)*f(n/(k^2)+(k-1)*n,此时n=k^2,得出k=logn,f(n)=n*f(1)+(logn-1)*n,故此时的时间复杂度为O(n*logn)。
如果每次划分都会产生一个空集时,此时f(n)=f(n-1)+n=...=f(1)+n*n,故此时的时间复杂度为O(n*2)
稳定性分析:
比如 4 2 4 3 5,第一次划分后为 3 2 4 4 5,此时两个4的相对位置发生了改变。
7.归并排序:归并排序分为两个部分,第一部分是不断的分割序列,第二部分就是不断的合并序列。
代码如下:
#include <iostream> using namespace std; void merge_fun(int * s,int i,int mid,int j,int * t) { int k=0,s1=i,s2=mid+1; while(s1<=mid&&s2<=j) { if(s[s1]>s[s2]) { t[k++]=s[s2]; s2++; } else if(s[s1]<=s[s2]) { t[k++]=s[s1]; s1++; } } while(s1<=mid) { t[k++]=s[s1]; s1++; } while(s2<=j) { t[k++]=s[s2]; s2++; } for(int ss=0;ss<k;ss++) { s[ss+i]=t[ss]; } } void merge_sort(int * s,int i,int j,int * t) { if(i>=j) return; int mid=(i+j)/2; if(mid!=0) cout<<"mid: "<<mid<<" i:"<<i<<" j:"<<j<<endl; merge_sort(s,i,mid,t); merge_sort(s,mid+1,j,t); merge_fun(s,i,mid,j,t); } int main() { int s[]={10,9,8,7,6,1,2,3,4,5}; int t[10]; merge_sort(s,0,9,t); for(int i=0;i<10;i++) { cout<<t[i]<<" "; } cout<<endl; return 0; }
和快排有点类似,总共会划分logn次,然后每一次都会归并,所以会比较n次,故时间复杂度为O(n*logn)。
8.基数排序:先找出序列中元素的最大位数,再从各位数开始,依次执行桶排序,从序列尾部开始回收元素。
代码如下:
#include <iostream> using namespace std; int get_oper_nums(int * s,int len) { int reV=0; for(int i=0;i<len;i++) { int temp_s=s[i]; int temp_rev=0; while(temp_s!=0) { temp_s=temp_s/10; temp_rev++; } if(temp_rev>reV) { reV=temp_rev; } } return reV; } void jishu_sort(int * s,int len) { int oper_nums=get_oper_nums(s,len); int r=1; for(int i=0;i<oper_nums;i++) { int count[10]; for(int i=0;i<10;i++) count[i]=0; for(int i=0;i<len;i++) { int temp=s[i]/r; int j=temp%10; count[j]++; } for(int i=1;i<10;i++) { count[i]+=count[i-1]; } int temp_s[len]; for(int i=len-1;i>=0;i--) { int temp=s[i]/r; int j=temp%10; temp_s[count[j]-1]=s[i]; count[j]--; } for(int i=0;i<len;i++) { s[i]=temp_s[i]; } r=r*10; for(int i=0;i<12;i++) { cout<<s[i]<<" "; } cout<<endl; } } int main() { int s[]={10,9,8,7,6,5,4,3,2,1,12,11}; jishu_sort(s,12); for(int i=0;i<12;i++) { cout<<s[i]<<" "; } cout<<endl; return 0; }
时间复杂度分析:
d表示最大位数,r表示基数,n表示要排序的元素个数,则时间复杂度为O(d*(r+n));


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话