后缀数组 + 后缀自动机小记
后缀数组 & 后缀自动机小记
基本介绍
后缀数组,英文SA,可以用于解决不少与字符串相关的题目。后缀数组本质上就是将其所有后缀进行排序得到的数组。
后缀自动机同样是一个解决字符串的强力工具,可能稍微需要一些理解,但是很板子。
后缀自动机需要较为熟练的掌握,后缀数组也最好能够掌握。
后缀自动机和后缀数组只有前缀相同 (SA,SAM)
后缀数组
定义在上文已经讲述,简单明了。大概讲一下如何求后缀数组,思想是倍增方法
朴素
暴力的方法明显是
性质+倍增
设两个数组,
这里有个小的预处理,我们将字符串后面填上与之等长的0,以此解决长度不统一的问题
我们考虑倍增,假设我们知道现在的
我们思考对于两个相等长度的字符串
把这个过程反过来,我们可以直接用两个参数
附oiwiki的效果图

那我们就可以很轻易地做到
简单优化
这个复杂度的限制因素在于排序上面。有没有更快的排序方法?是有的。因为在
板子
/*强烈建议不要贺OIWiki的代码,因为跑得相当慢*/
#include<iostream>
#include<cstdio>
#include<cstring>
using namespace std;
char s[1000005];
int rk[1000005],cnt[1000005],tmp[1000005];
int sa[1000005],n,M=1000,tmp2[1000005];
int main(){
scanf("%s",s+1);
int n=strlen(s+1);
//presets
for(int i=1;i<=n;i++){
rk[i]=s[i];
cnt[rk[i]]++;
}
for(int i=2;i<=M;i++)cnt[i]+=cnt[i-1];
for(int i=n;i>=1;i--)sa[cnt[rk[i]]--]=i;
//opertation,every time *=2
for(int T=1;T<=n;T<<=1){
int po=0;
for(int i=n-T+1;i<=n;++i)tmp[++po]=i;
for(int i=1;i<=n;i++)
if(sa[i]>T)tmp[++po]=sa[i]-T;
//基数排序基本操作
for(int i=1;i<=M;i++)cnt[i]=0;
for(int i=1;i<=n;i++)cnt[rk[i]]++;
for(int i=2;i<=M;i++)cnt[i]+=cnt[i-1];
for(int i=n;i>=1;i--){
sa[cnt[rk[tmp[i]]]--]=tmp[i];
tmp[i]=0;
}
for(int i=1;i<=n;i++)tmp2[i]=rk[i];
po=1;rk[sa[1]]=1;
//倒回到rk上
for(int i=2;i<=n;i++){
if(tmp2[sa[i]]==tmp2[sa[i-1]] && tmp2[sa[i]+T]==tmp2[sa[i-1]+T])rk[sa[i]]=po;
else rk[sa[i]]=++po;
}
if(po==n)break;
M=po;
}
for(int i=1;i<=n;i++)cout<<sa[i]<<" ";
return 0;
}
可以详细讲一下这里面每一步的作用。
因为每一次是两个关键字的排序,采用基数排序可以大大加快排序的过程。基数排序的思路为,记录第二关键字排名第
落实到代码中,其中
之后就是基数排序的基本操作,排序之后会得到新的
这下应该就能够完全看懂 SA 的代码实现了。
当然后缀数组还有一些其他的东西可以操作
后缀树
定义
后缀树就是所有后缀数组组成的 Trie 树。
小小优化
首先我们考虑简单建树,但是由于本质不同的字串的数量可能做到
但是我们不要忘记一个很优秀的性质,就是所有叶子节点一定不会超过
构建后缀树
此处我们先放下不讲,为什么呢?因为后缀树用可以直接用SAM来进行构造更方便。
关于hight数组
定义
其中
作用
- 求本质不同的子串个数。
很显然,我们对于每个后缀,跳过
我们换过来想,我们每次要跳过
- 求两个字串的LCP
假设两个字串
接着我们求
构造方法
结论:
通过此结论,可以
int k=0;
for(int i=1,k=0;i<=n;i++){
if(k>0)k--;
while(s[i+k]==s[sa[rk[i]-1]+k])k++;
ht[rk[i]]=k;
}
虽然这个性质确实感觉有点无中生有,我也没有搞明白是怎么想到的。但是是能够证明的。证明比较无聊而且没有什么意思,大概就是强行分析两者的关系。
后缀自动机(SAM)
后缀自动机和很多其他自动机一样,后缀自动机每个节点接受对于原字符串
不多介绍,我们从头开始讲起。
Endpos
我们定义

如图,对于原串,
我们将利用它来进行自动机的构造
parent tree
首先思考一下关于
- 如果
- 对于所有相等的
第一个性质是显然的,因为
第二个性质根据
当然这两个性质都可以更为严谨地证明。
根据这两个我们会发现这是一个类似树形的结构,尝试根据包含关系构造出来树。
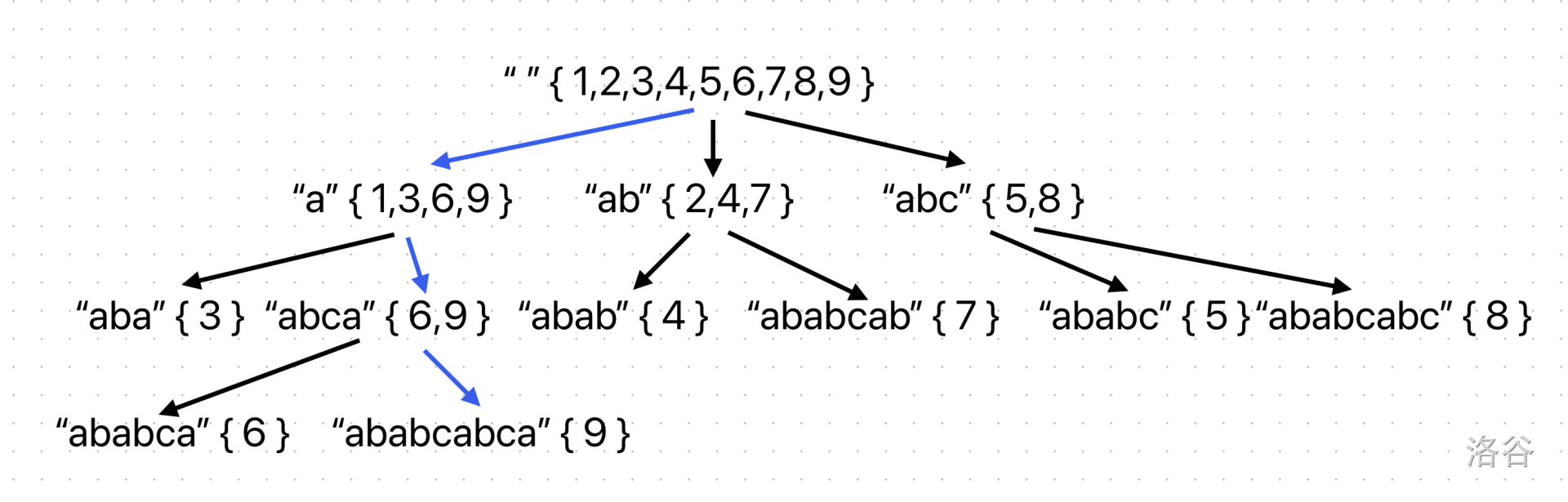
这棵树就叫做 parent tree,其节点和后缀自动机状态一一对应(注意 parent tree 并不是 SAM 真正的转移边,这个概念是不同的,只是他们的状态,即节点对应的内容是相同的)。
接下来考虑如何构造 parent tree
构造
采用动态构造的方法,对于每次新添加一个字符,考虑其所有的后缀的位置。
需要维护若干个变量:
- 设
- 设
- 设
- 设
每次加入一个新的字符
-
Case1
如果一直找不到,那么表示这是一个全新的后缀,直接
-
Case2
如果
-
Case3
如果
我们复制一个
记得最后
void ins(int c){
int x=++cnode,p=lst;
lst=cnode;
w[cnode]=1;
len[x]=len[p]+1;
for(;p&&!tr[p][c];p=fa[p])tr[p][c]=x;
if(!p)fa[x]=1;//Case 1
else{
int q=tr[p][c];
if(len[q]==len[p]+1)fa[x]=q;//Case 2
else{
int newn=++cnode;//Case 3:clone
for(int i=0;i<=25;i++)tr[newn][i]=tr[q][i];
fa[newn]=fa[q];
len[newn]=len[p]+1;
fa[q]=fa[x]=newn;
for(;p&&tr[p][c]==q;p=fa[p])tr[p][c]=newn;//reset
}
}
}
后缀自动机的主要部分也就讲完了,但是没有讲性质,因为需要结合具体的题目。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 一文读懂知识蒸馏
· 终于写完轮子一部分:tcp代理 了,记录一下