oracle数据库 聚合函数 LISTAGG 实现 行转列
列转行
LISTAGG(列名,' 分割符号')
oracle 11g 以上的版本才有的一个将指定列名的多行查询结果,用 指定的分割符号 合并成一行显示:
WITH temp AS (
SELECT '001' TASK ,'t1' CODE ,'测试1' NAME FROM dual
UNION ALL
SELECT '001' TASK ,'t1' CODE ,'测试1' NAME FROM dual
UNION ALL
SELECT '001' TASK ,'t1' CODE ,'测试1' NAME FROM dual
)
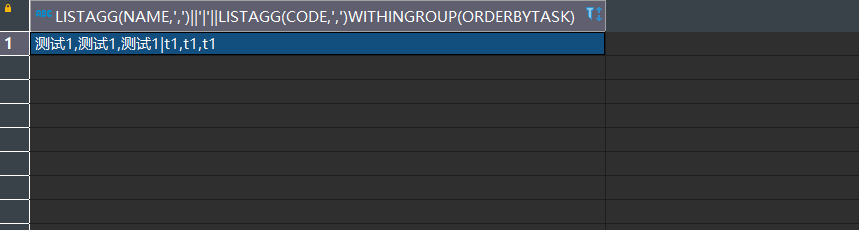
select listagg(name, ',' ) || '|' || listagg(code, ',' ) within group ( order by task ) from temp
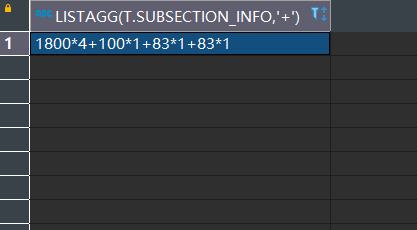
SELECT LISTAGG(t.SUBSECTION_INFO,'+') FROM (
SELECT ps.SUBSECTION_NUM ||'*'|| ps.SUBSECTION_COUNT SUBSECTION_INFO FROM PLAN_SUBSECTION ps
)t
表原始数据:
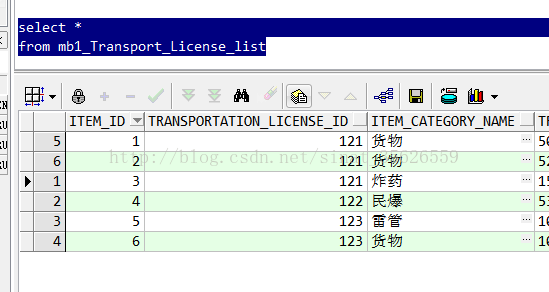
需求:将 mb1_Transport_License_list 表中的数据,根据 transportation_license_id 数据进行分组,对 Item_Category_Name 列的数据进行 去重合并
使用聚合函数 LISTAGG 解决
SELECT transportation_license_id,
LISTAGG( to_char(Item_Category_Name), ',') WITHIN GROUP(ORDER BY Item_Category_Name) AS employees
FROM ( select distinct transportation_license_id, item_category_name
from mb1_Transport_License_list ) group by transportation_license_id
SQL解析:
select distinct transportation_license_id, item_category_name from mb1_Transport_Lincense_list ; -- 对需要做合并处理的数据源数据进行去重处理,如果实际要求不需要去重处理,这里可以直接改为 表名,(例如: from mb1_Transport_Lincense_list)进行查询
LISTAGG( to_char(Item_Category_Name), ',') WITHIN GROUP(ORDER BY Item_Category_Name) -- 将 Item_Category_Name 列的内容以", "进行分割合并、排序;
to_char(Item_Category_Name) -- to_char(列名) 解决使用聚合函数 LISTAGG 进行查询后,对查询结果乱码问题进行转码处理;
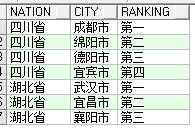
运行后的结果:
1.oracle的pivot函数
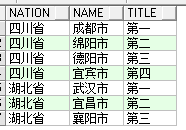
with temp as(select '四川省' nation ,'成都市' city,'第一' ranking from dual union allselect '四川省' nation ,
'绵阳市' city,'第二' ranking from dual union allselect '四川省' nation ,'德阳市' city,
'第三' ranking from dual union allselect '四川省' nation ,'宜宾市' city,
'第四' ranking from dual union allselect '湖北省' nation ,'武汉市' city,
'第一' ranking from dual union allselect '湖北省' nation ,'宜昌市' city,
'第二' ranking from dual union allselect '湖北省' nation ,'襄阳市' city,
'第三' ranking from dual)select * from (select nation,city,ranking from temp)pivot (max(city) for
ranking in ('第一' as 第一,'第二' AS 第二,'第三' AS 第三,'第四' AS 第四));

说明:pivot(聚合函数 for 列名 in(类型)),其中 in(‘’) 中可以指定别名,in中还可以指定子查询,比如
select distinct ranking from temp
SELECT * FROM [StudentScores] /*数据源*/
AS P
PIVOT
(
SUM(Score/*行转列后 列的值*/) FOR
p.Subject/*需要行转列的列*/ IN ([语文],[数学],[英语],[生物]/*列的值*/)
) AS T
2.使用max结合decode函数
原表
使用max结合decode函数
with temp as(select '四川省' nation ,'成都市' city,'第一' ranking from dual union allselect '四川省' nation ,
'绵阳市' city,'第二' ranking from dual union allselect '四川省' nation ,'德阳市' city,
'第三' ranking from dual union allselect '四川省' nation ,'宜宾市' city,
'第四' ranking from dual union allselect '湖北省' nation ,'武汉市' city,
'第一' ranking from dual union allselect '湖北省' nation ,'宜昌市' city,
'第二' ranking from dual union allselect '湖北省' nation ,'襄阳市' city,
'第三' ranking from dual)select nation,max(decode(ranking, '第一', city, '')) as 第一,
max(decode(ranking, '第二', city, '')) as 第二,max(decode(ranking, '第三', city, '')) as 第三,
max(decode(ranking, '第四', city, '')) as 第四from temp group by nation;
3、使用max结合case when 函数
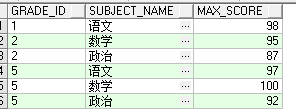
select case when grade_id='1' then '一年级'
when grade_id='2' then '二年级'
when grade_id='5' then '五年级'
else null end "年级",
max(case when subject_name='语文' then max_score
else 0 end) "语文" ,
max(case when subject_name='数学' then max_score
else 0 end) "数学" ,
max(case when subject_name='政治' then max_score
else 0 end) "政治"
from dim_ia_test_ysf
group by
case when grade_id='1' then '一年级'
when grade_id='2' then '二年级'
when grade_id='5' then '五年级'
else null end
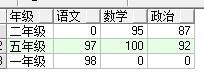
4、unpivot函数
说明:unpivot(自定义列名/列的值/ for 自定义列名/列名/ in(列名))

with temp as(select '四川省' nation ,'成都市' 第一,'绵阳市' 第二,'德阳市' 第三,'宜宾市' 第四
from dual union allselect '湖北省' nation ,'武汉市' 第一,'宜昌市' 第二,'襄阳市' 第三,'' 第四
from dual)select nation,name,title fromtemp
unpivot(name for title in (第一,第二,第三,第四))t
转载自:https://www.cnblogs.com/xiao02fang/p/9705609.html
转载自:https://blog.csdn.net/sinat_35626559/article/details/72621695
本文作者:Journey&Flower
本文链接:https://www.cnblogs.com/JourneyOfFlower/p/14240715.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步