
Scrapy入门学习初步总览
OK,因为数据分析的缘故需要采集一些数据,所以学了一段时间的爬虫,但都是利用urllib,requests,Beautifulsoup采取一些小规模的数据,感觉并不顺手,所以从今天开始进入scrapy框架的学习。
事先申明环境配置
- win10
- python3.6
- Pycharm2017.3专业版(网上找秘钥或是使用edu邮箱)
另附我的上一篇文章Windows下pip install scrapy 出错,含一些虚拟环境的创建,pycharm的使用安利
新建Scrapy工程和项目
- 进入命令行模式(使用Pychram下方的Terminal即可),cd到你项目文件下
- 通过
scrapy startproject ProjectName(你的项目名)新建工程,得到如图所示文件结构(注:截图时较晚,main.py和jobbole.py是后期创建的,忽略就好)

3. 进入命令行模式(使用Pychram下方的Terminal即可),通过scrapy genspider name(爬虫文件名) 域名新建爬虫文件
注意,这里可以选择不同模板(默认为basic),通过
scrapy genspider -t 模板名 name 域名
可选模板有:

这里我们通过爬取豆瓣读书来学习,所以如图所示

项目结构如下

OK,咱们来看看项目结构,如上图:
- 核心是spider文件夹,这里是放你处理爬虫逻辑代码的地方
- items.py是存放数据的容器,定义要获得的数据
- pipelines.py管道文件(类似django的路由文件),对items中的数据进行处理
- settings.py顾名思义,对项目的一些设置
- main.py自定义的,下文会说到
双击打开doubanread.py,这是你写爬虫逻辑和代码的地方,可见:

如图它自动创建好了DoubanreadSpider类,其中需要注意几点:name用于爬虫项目启动;start_urls是列表可用来存放链接
OK,命令行启动豆瓣爬虫scrapy crawl doubanread(这里就是上面所提的name),不出意外,一定会报错缺少pywin32这个包。通过Pycharm安装即可,不会的话,看文章开头的链接。
再次命令行启动,可以运行了。
这里再提一个开头说的main.py,在一个视频中学到的,用于在Pycharm中调试。在项目文件夹下新建一个main.py ,代码如下:
#新建main文件,用来设置断点调试程序
#在其他py文件上打上断点后,debug该main文件即可
from scrapy.cmdline import execute3#调用这个可以执行scrapy脚本
import sys
import os
sys.path.append(os.path.dirname(os.path.abspath(__file__)))#找到工程目录才能运行scrapy命令,你可以打印一下看看
# print(os.path.dirname(os.path.abspath(__file__)))
execute(['scrapy','crawl','doubanread'])#这其实就是scrapy启动项目的命令拆分在其他py文件上打上断点后,debug该main文件即可。
OK,学习一门语言不动手是不行的,先通过一个简单的爬虫(豆瓣TOP250爬取)来具体学习scrapy的使用。
我想豆瓣top250是大多数初学者都爬过的网页,毕竟他几乎没有反扒机制,而且页面结构简单,有利于信心增长,先来看一下该爬虫的流程图 。
parse是解析页面链接,detail_parse是解析书籍具体信息,‘获取评论’是获取每本书的热门短评(取前20页)。分析评论可知,短评更具代表性,且每本书都有上万条短评,但差不多15页左右短评点赞数就为0,且褒贬都有,这也表明前15页左右评论较其他评论更具代表性。
开始前
- 修改doubanread.py中的
start_urls= ['https://book.douban.com/top250'] - 修改settings.py,将
ROBOTSTXT_OBEY = True改为ROBOTSTXT_OBEY = False(这是是否遵守robots协议,遵守则爬取前都要判断能否爬取) - 修改settings.py,将
USER_AGENT = ''添加·头信息(F12—>Network刷新可查,不会就百度)
先做好这些,其余随项目进行而变动。
提取网页信息
- xpath选择器使用
- css选择器使用
因为个人前端学得不好,所以更倾向于xpath,但css也会涉及一二。
xpath常用语法:



图片来自网络
可参考文章:
【1】Scrapy Selectors 选择器
【2】xpath教程
【3】xpath提取多个标签下的text
【4】利用xpath如何读取以下节点的属性值
具体结合代码运用xpath选择器
首先打开豆瓣图书 Top 250,打开开发者工具(F12或者右键审查元素),可见如下图
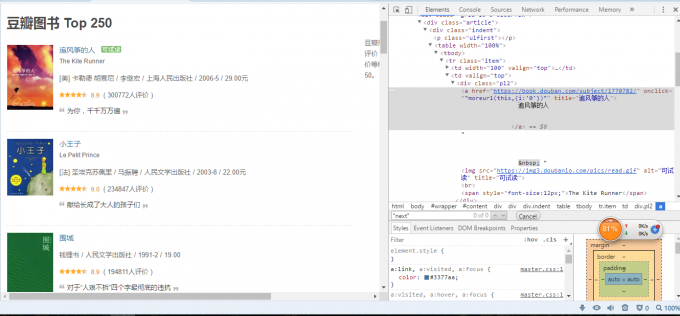
随便点击进入一本书,如下图(要获取圈中有用信息)

查看下一页链接,如下图

基本思路就是获取这些内容,OK,看看具体如何实现
xpath解析静态HTML文件,最简单的方式是(如图):
1. 打开开发者工具,选择元素
2. 移动鼠标箭头到你想要选取的地方
3. 右键你选取的元素,选择copy
4. 选择copy xpath

parse函数中response的xpath函数,生成selector对象,可再次使用xpath。使用extract()函数可转换为列表
post_urls=response.xpath(‘//[@id=”content”]/div/div[1]/div/table[1]/tbody/tr/td[2]/div[1]/a/@href’).extract()
@href是获取href的属性值,text()是获取标签间的值
在pycharm中debug‘main’,设置断点对代码进行调试,如图:

在工具栏中可以看到具体信息,如图。你会发现post_urls返回的是空

注意:浏览器中向上面一样确定xpath有时会出错,因为在开发者工具中选择xpath会包含通过js异步加载的信息,在通过查看源文件,你会发现,像上面那个xpath他并不包含<tbody>标签。
使用xpath时谨记:
- 使用开发者工具确定xpath时,要禁用JavaScript
- 不要用完整的XPath路径。使用相对及基于属性(例如
id , class , width等)的路径或者具有区别性的特性例如contains(@href, 'image') - 不要在XPath表达式中加入
<tbody>元素
所以写代码时就要多调试,判断xpath是否正确。但你会发现通过debug非常的慢,这里推荐使用scrapy的shell交互环境,一次加载出HTML,不需要反复获取HTML。在pycharm的Terminal中输入命令行scrapy shell https://book.douban.com/top250,就能愉快的玩耍了。
修改为
post_urls=response.xpath('//div[@class="indent"]/table/tr/td[2]/div/a/@href').extract()
成功获取到连接了,如图:

粘贴到代码中就好了。其余元素类似获取即可,可参考下文的代码。
关于xpath使用问题:首先你要知道xpath有多种写法,都可以获取你想要的元素。推荐确定class属性和确定id属性,通常class属性更好用,因为它可以先选取一个大模块,再次xpath解析其余小模块。
比如:
con=response.xpath(‘… . . .’) ————>注意这里没有extract()
i=con.xpath(‘. . . . . .’).extract()[0]
j=con.xpath(‘. . . . . .’).extract()[0]
等等
extract会把selector对象转换成list类型,extract_first()直接转换为str类型。后者可以设置参数为空extract_first(''),避免没有解析到内容是抛出异常
编辑spider
这是需要导入的
import scrapy
from scrapy.http import Request #见下文
import re #有时使用正则会更简单
#涉及item-pipeline使用,先不管
#from AticleSpider.items import AticlespiderItem以下是parse函数:
def parse(self, response):
"""
1、 top250开始页面,获取每本书链接和推荐语(好像要用到meta)
2、 每本书交给Request下载,并传给detail_parse解析
3、 判断下一页是否存在,调用parse?
"""
post_urls = response.xpath('//div[@class="indent"]/table/tr/td[2]/div/a/@href').extract()
notes = response.xpath('//div[@class="indent"]/table/tr/td[2]/p/span/text()').extract()
img_urls=response.xpath('//div[@class="indent"]/table/tr/td[1]/a/img/@src').extract()#可写成'//a[@class="nbg"]/img/@src'
for url,note,img in zip(post_urls,notes,img_urls):
print(response.url)
print(url,note)
yield Request(url=url,meta={'book_note':note,'book_img':img},callback=self.detail_parse)
# break
next_url=response.xpath('//link[@rel="next"]/@href').extract_first('')
if next_url:
yield Request(url=next_url,callback=self.parse)
pass你能看到代码中出现了yield Request(url=url,meta={'book_note':note,'book_img':img},callback=self.detail_parse)
和yield Request(url=next_url,callback=self.parse)
这里要导入from scrapy.http import Request
- 如果你有其他语言的学习经验,会知道
yield关键字类似递归(返回某个对象后继续执行) ,迭代器你懂吗。 而Request(url,callback=func),scrapy为start_urls中每个url都创建了scrapy.Request对象,并返回scrapy.http.Response对象,赋给回调函数,callback是回调函数。
而meta参数起将信息传递给下一个函数的作用(可用来传cookie),它伴随着Request产生,回调函数得到的response中就有相应的meta。接受字典数据,可用字典相应方式处理。
额,反正我是这样理解的(如果你不需要深入理解的话,只要掌握如何使用就好了,o( ̄︶ ̄)o)。要是你还糊涂,可以参考:
【1】 scrapy的重要对象request和response
【2】scrapy的request的meta参数是什么意思?—->如何传cookie
以下是detail_parse函数:
后期再具体处理时发现有一些匹配值为空,所以加上了try/except/else语句
def detail_parse(self,response):
book_note=response.meta.get('book_note','')
img_url=response.meta.get('book_img','')
try:
title = response.xpath('//span[@property="v:itemreviewed"]/text()').extract_first('')
text = response.xpath('//*[@id="info"]/a[1]/text()').extract()[0].split('\n')
author = text[-1].strip()
if len(text) == 2:
country = u'中国'
else:
country = text[1].strip() #
date = response.xpath('//*[@id="info"]').extract_first('')
content = re.compile(r'<span class="pl">出版年:</span>(.*?)<br>', re.S)
if re.findall(content, date):
publish_date = re.findall(content, date)[0]
else:
publish_date = ''
press = response.xpath('//*[@id="info"]/text()[5]').extract_first('') # 出版社
Score = float(
response.xpath('//*[@id="interest_sectl"]/div/div[2]/strong/text()').extract_first('').strip()) # 总评分数
star = response.xpath('//*[@id="interest_sectl"]/div/div[2]/div/div[1]/@class').extract_first('')
Star = float(re.match(r'.*?(\d+)', star).group(1)) / 10 # 平均星数
participation_num = int(
response.xpath('//a[@class="rating_people"]/span/text()').extract_first('')) # 参与评分人次
s = response.xpath('//span[@class="rating_per"]/text()').extract()
s5 = float(s[0].strip('%')) / 100
s4 = float(s[1].strip('%')) / 100
s3 = float(s[2].strip('%')) / 100
s2 = float(s[3].strip('%')) / 100
s1 = float(s[4].strip('%')) / 100
except:
pass
else:
# 实例化items
#先不用管,后面谈如何保存数据会讲
#items = AticlespiderItem()
# items['title'] = title
# items['author'] = author
# items['country'] = country
# items['publish_date'] = publish_date
# items['note'] = book_note
# items['press'] = press
# items['Score'] = Score
# items['Star'] = Star
# items['People_nums'] = participation_num
# items['s5'] = s5
# items['s4'] = s4
# items['s3'] = s3
# items['s2'] = s2
# items['s1'] = s1
# yield items
comments_url=response.xpath('//div[@class="mod-hd"]/h2/span[2]/a/@href').extract_first('')
if comments_url:
pages=0 #这个用以标记请求评论的页数(<15)
yield Request(url=comments_url,meta={'Title':title ,'Pages':pages},callback=self.getcomments)
print('{}请求评论。。。'.format(title))
pass以下是获取每本书的热门评论getcomments()
def getcomments(self,response):
"""
1、 评论主要获取:短评、打分(有坑,有的人没有打分)、点赞数
2、 txt保存,15页
:param response:
:return:
"""
comment = response.xpath('//div[@class="comment"]')
#分别获取评论comments,评星stars,点赞votes
lines=[]
for i in comment:
votes=i.xpath('h3/span[1]/span/text()').extract_first('')
comments = i.xpath('p/text()').extract_first('')
stars=i.xpath('h3/span[2]/span/@class').extract_first('')
if stars=='':
stars='0'
else:stars=stars[-9:-8]
lines.append(comments+','+stars+','+votes+'\n')
title=response.meta['Title']
#具体文件路径,自己指配即可
with open('\\comments\\{}.txt'.format(title),'a+')as f:
for line in lines:
f.writelines(line)
pages = response.meta['Pages']#用来标记请求页数
next=response.xpath('//*[@id="content"]/div/div[1]/div/div[3]/ul/li[3]/a/@href').extract_first('')
url=response.urljoin(next)
pages+=1
while url :
if pages<4:#初步测试时,请求页数写小些,毕竟只是看看运行结果
print('正在请求{}第{}页'.format(title, pages))
yield Request(url, meta={'Title': title,'Pages':pages}, callback=self.getcomments)
break
print('{}超过{}页'.format(title,pages))
breakOK,貌似以上工作都准备集全了,debug一下main.py能看到确实是爬取到了想要的数据,但在运行时却无法获取数据,下意识猜想可能是被反爬检测到了。然后我就查看了一下豆瓣TOP250,果真ip被豆瓣给封了。。。

如图所示
根据以往经验,随机添加UA,随机延长请求时间,或是直接使用ip代理。再结合现实情况,毕竟数据不大没有必要上代理,所以考虑前两种方法。
而scrapy框架非常方便的为此提供了解决方法。修改middleware.py中间件(这里定义了爬虫是如何请求,解析页面等等)和settings.py。
settings.py中
1. 定义一个USER_AGENT_LIST
2. DOWNLOAD_DELAY = 3 下载器在下载同一个网站下一个页面前需要等待的时间,该选项可以用来限制爬取速度,减轻服务器压力。默认为3秒,适当修改即可,同时也支持小数:0.25 以秒为单位
3. COOKIES_ENABLED = False禁用cookies
4. 如下,添加下载中间件的配置,RandomUA下面会说,200可以随便设置(越小优先级越高)
DOWNLOADER_MIDDLEWARES = {
'AticleSpider.middlewares.RandomUA':200,
}
middlewares.py
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
import random
from AticleSpider.settings import USER_AGENT_LIST#注意要导入settings中的UA列表
#定义随机请求头RandomUA类,继承自UserAgentMiddleware
class RandomUA(UserAgentMiddleware):
def process_request(self, request, spider):
ua=random.choice(USER_AGENT_LIST)
request.headers.setdefault("User-Agent:",ua)这里是搜集的一些User-Agent,百度一下很多。
#粘贴用即可
USER_AGENT_LIST=[
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Opera/9.80 (J2ME/MIDP; Opera Mini/5.0 (Windows NT 6.1; WOW64) AppleWebKit/23.411; U; en) Presto/2.5.25 Version/10.54 ",
"Opera/9.80 (J2ME/MIDP; Opera Mini/4.3.24214 (Windows; U; Windows NT 6.1) AppleWebKit/24.838; U; id) Presto/2.5.25 Version/10.54 ",
"Opera/9.80 (Windows NT 6.1; Opera Mobi/49; U; en) Presto/2.4.18 Version/10.00 ",
"Opera/7.51 (Windows NT 5.1; U) [en] ",
"Opera/8.0 (Windows NT 5.1; U; en) ",
"Opera/8.0 (Windows NT 5.1; U; zh-cn) ",
]再次对main文件debug,发现该请求的数据抓到了,直接运行main.py就好了。
发现码了太多字了(o( ̄︶ ̄)o,下篇文章再讲解scrapy如何用item-Pipeline保存数据吧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号