
Spark本地安装及Linux下伪分布式搭建
title: Spark本地安装及Linux下伪分布式搭建
date: 2018-12-01 12:34:35
tags: Spark
categories: 大数据
toc: true
个人github博客:Josonlee’s Blog
前期准备
spark可以在Linux上搭建,也能不安装hadoop直接在Windows上搭建单机版本。首先是从官网上下载和你hadoop版本匹配的spark版本(版本不要太新,选择稳定版本,如我的是hadoop2.6版本对应spark-2.0.2-bin-hadoop2.6.tgz)
可以放心的是,spark安装远比hadoop安装简单的多
本地安装
把下载的压缩包解压到本地某个位置上,修改环境变量,添加%SPARK_HOME%:解压的位置;修改Path,增加一栏%SPARK_HOME%/bin
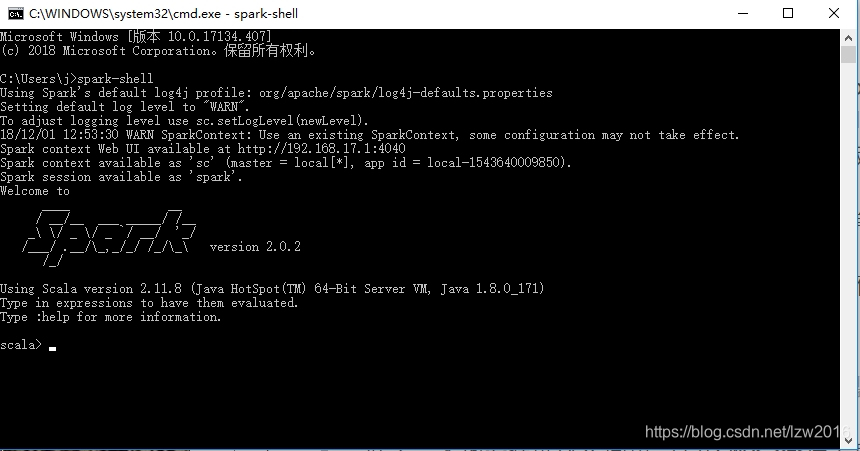
好了,本地安装就这么简单。打开CMD命令行工具,输入spark-shell,如图显示就是安装成功了
- Error:安装后运行是有可能会遇到一个错误:
Failed to find Spark jars directory- 解决方法:安装路径名上不能有空格(比如Program Files就不行)
基于hadoop伪分布式搭建
将你下载的spark压缩包,通过某些工具(我用的是WinSCP)上传到虚拟机中
有必要说一下,我的是centos7系统,hadoop也是伪分布式的,主从节点名namenode(具体的你可以看我之前搭建hadoop的博客)
- 解压到用户目录下(我这里是
/home/hadoop)
# 上传到了/root目录下,cd到该目录下执行
tar -zxvf spark-2.0.2-bin-hadoop2.6.tgz -C /home/hadoop
- 同本地安装一样,配置环境变量
- 可以选择在系统环境变量中配置
/etc/profile,也可以选择用户环境变量中配置/home/hadoop/.bash_profile,推荐后者
- 可以选择在系统环境变量中配置
vi .bash_profile
# 添加
export SPARK_HOME=/home/hadoop/spark-2.0.2-bin-hadoop2.6
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
# 保存退出后,source .bash_profile使配置生效
配置完成后同样可以输入spark-shell查看运行
- 配置spark的设置文件(conf目录下)spark-env.sh和slaves
切换到spark下的conf目录下,cd /home/hadoop/spark-2.0.2-bin-hadoop2.6/conf
spark没有spark-env.sh和slaves文件,只有以template结尾的两个模板文件,依据模板文件生成即可cp spark-env.sh.template spark-env.sh,cp slaves.template slaves
# 修改spark-env.sh
vi spark-env.sh
# 增加类似下文内容
export JAVA_HOME=/usr/java/jdk1.8.0_131
export HADOOP_HOME=/home/hadoop/hadoop-2.6.0-cdh5.12.1
export HADOOP_CONF_DIR=/home/hadoop/hadoop-2.6.0-cdh5.12.1/etc/hadoop
export SPARK_MASTER_HOST=namenode
export SPARK_WORKER_MEMORY=1024m
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
像JAVA_HOME,HADOOP_HOME是你之前java和hadoop安装的位置,可以使用echo JAVA_HOME查看
SPARK_MASTER_HOST,spark也是主从关系,这里指定spark主节点为hadoop的主节点名即可
后三行是默认配置,依你电脑配置可修改。分别代表worker内存、核、实例分配
# 修改slaves
vi slaves
# 增加从节点
namenode #因为是伪分布式,namenode既是主也是从
还有就是要注意,你之前配置hadoop时已经完成了ip和名的映射
以上内容完成后,就搭建完了
启动spark
先完成一个事,你可以看到spark下sbin目录中启动和结束的命令是start-all.sh,stop-all.sh,和hadoop启动结束命令重名了,用mv命令修改为start-spark-all.sh,stop-spark-all.sh就好了
- 启动hadoop集群
start-hdfs.sh,start-yarn.sh - 启动spark
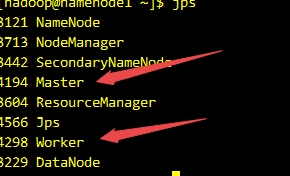
start-spark-all.sh - 使用jps命令查看运行情况
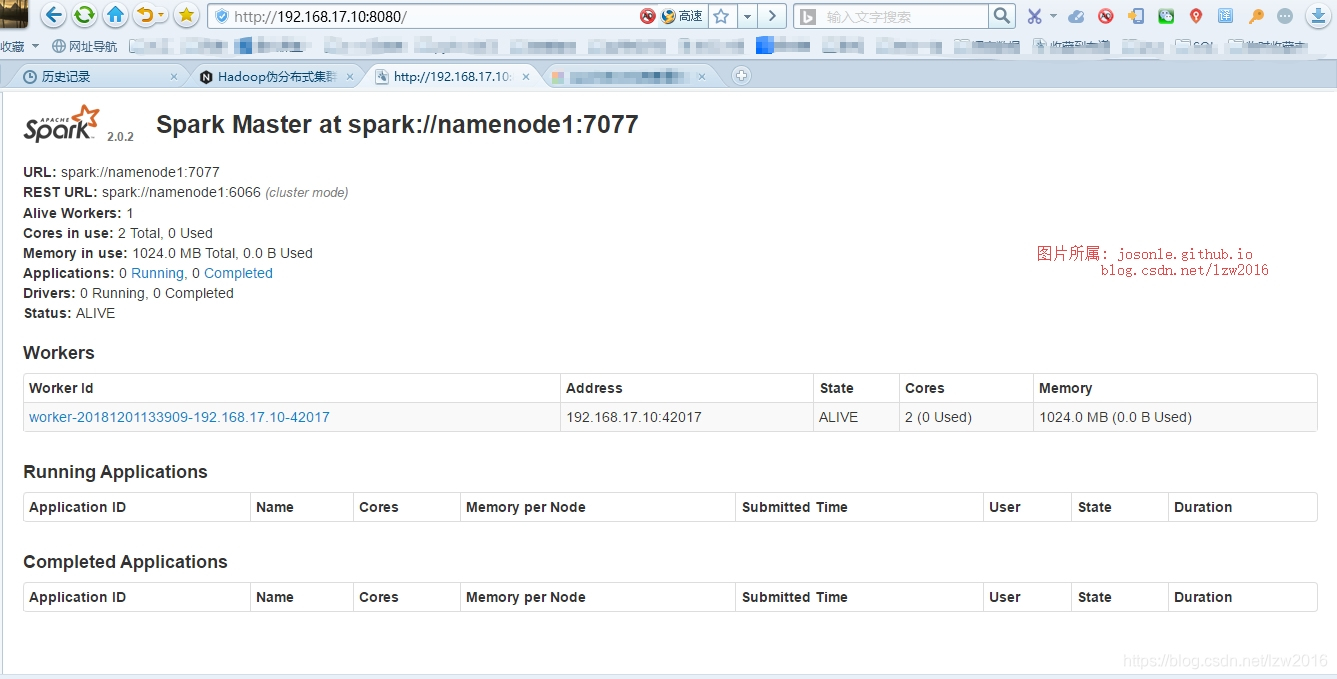
- 本地浏览器打开
http://192.168.17.10:8080(这个IP是我之前在hadoop中配置的namenode的IP,端口是固定的)
![在这里插入图片描述]()
![在这里插入图片描述]()
安装过程可能遇到的问题
在配置以上设置时,一定要分清楚,这都是我的环境设置,要合理的区分开。比如说你java,hadoop安装的位置和我的不一样等等
在替别人查看这一块配置时,它运行spark集群时,遇到了几个问题
- 用户hadoop无权限在spark下创建logs等目录
- 通过
ls -l查看spark-2.0.2-bin-hadoop2.6这个文件夹所属组和用户是root - 修改文件夹所属组和用户即可,
chown -R hadoop:hadoop /home/hadoop/spark-2.0.2-bin-hadoop2.6
- 通过
spark-class: line 71…No such file or directory,显示大概是找不到java- 这个问题就是配置写错了,spark-env.sh中java_home写错了
spark完全分布集群搭建
过程和伪分布式搭建一样,不同在于slaves中设置的从节点名为datanode1、datanode2类似的
然后,再复制到从节点主机中,如scp -r /home/hadoop/spark-2.0.2-bin-hadoop2.6 datanode1:/home/hadoop (这是因为之前配好了ssh免密登录)
版权声明:本文为博主原创文章,未经博主允许不得转载。
https://josonle.github.io
https://blog.csdn.net/lzw2016

 浙公网安备 33010602011771号
浙公网安备 33010602011771号