02-NLP-03-主题模型
PPT
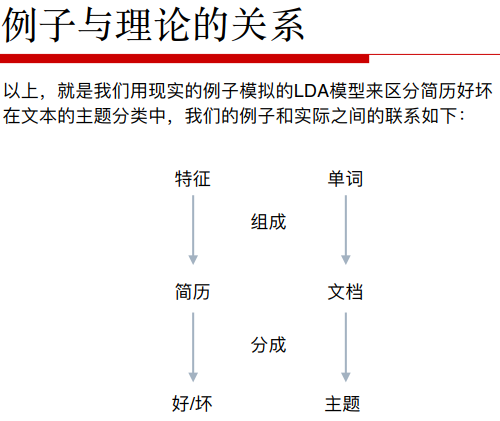
什么是主题模型:给定一篇文章X,区分出他是什么主题Y。
理理解整个过程,涉及到比较复杂数学推导。
⼀一般来说,从公式1一直推导到公式100,
⼤大部分同学会在公式10左右的时候,就关了了直播,洗洗睡了了
所以,我今天用3个不不同版本的讲解,从简单到复杂,一步步理理解主体模型。
直观版:
假设某企业想要招聘⼀一个工程师,他们收到了一把的简历,他们想直接通过简历来看谁是大牛,谁是彩笔。




实质就是通过一次次经验学习出各种不同特征后来区分类别。


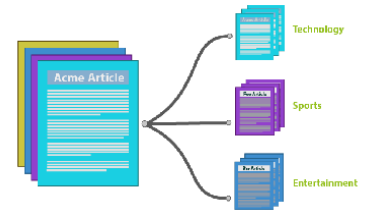
实际上,一篇文章送入到LDA后,会被视为是放入了一个词袋,词袋可以组成这个文档,从而文档可以被分成不同的主题。



先验概率是原本自己的印象,现在通过简历来判定是否为好工程师,就是后验概率。

第一项可以直接在文档中统计出单词频率
后面两项根据经验慢慢拟合得到然后比较右边两项的乘积与左边对比,通过调整右边两项的分布
使得最后得到的乘积逼近左边概率。



训练出的两个结果向量就是两个分布:文档|主题,单词|主题
不断调整θd和φt来得到最优解。


https://blog.csdn.net/v_july_v/article/details/41209515


先验概率和后验概率有相同的形式



与二项分布长相一样。




先给一个随机的分布,然后通过一次次的样本读入,将分类器进行优化,最终优化成一个符合数据集的分布的分类器。


利用topic当中间量,从而生成两个好观察的两个概率的乘积,将这些乘积数值累加到一起得到最后生成文档的概率。
生成模型就是公式中似然函数或者是样本信息X。生成模型的作用就是用来反推文章属于哪个分类的模型。
生成模型就是用来生成一片文章的。生成的结果完全取决于所给的生成模型。
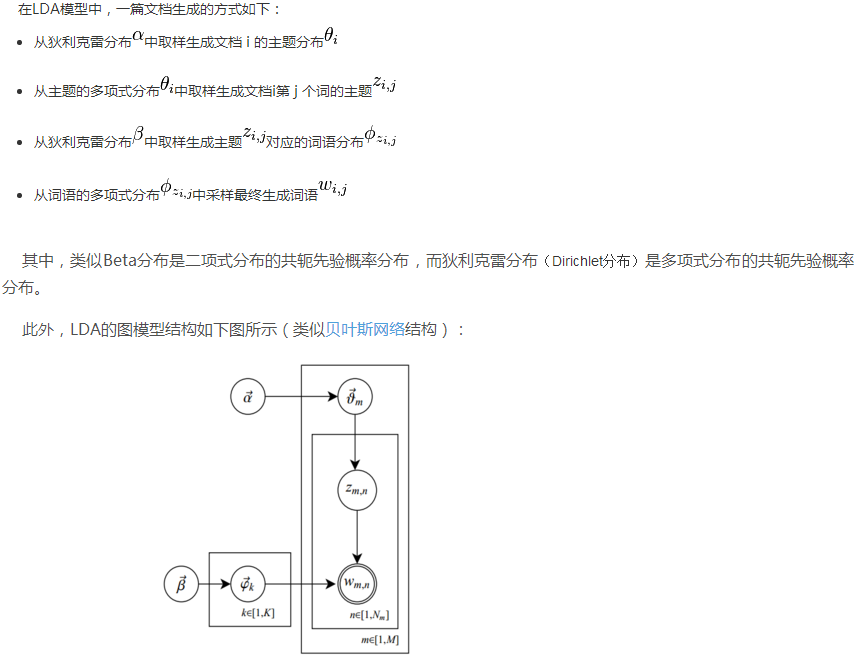
每篇文章由各种不同的词组成的,要确定每个词的位置通过掷骰子来决定:
1.文档——主题骰子:分布1
2.主题——单词骰子:分布2
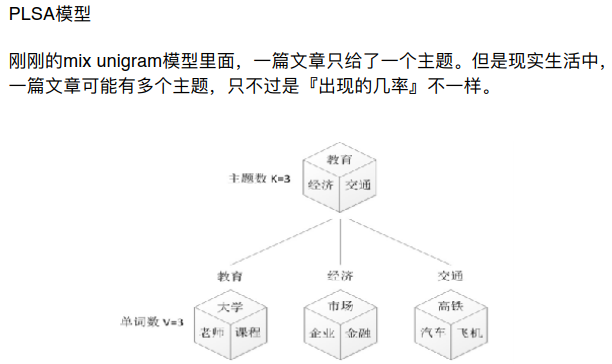


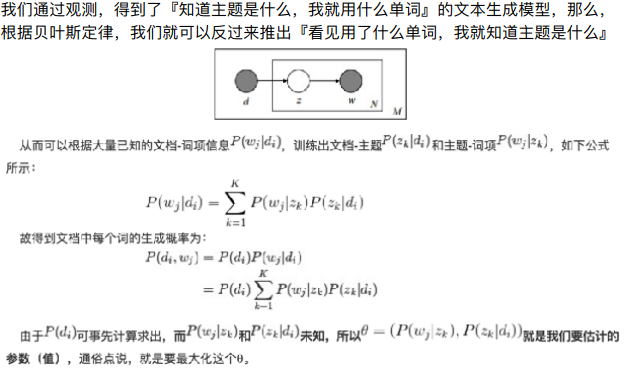


在PLSA中主题的分布(0.5,0.2,0.3)是确定的(即确定是符合什么频率分布),但在LDA中是不确定的是通过掷骰子随机得到的(这样可以让得到的结果不至于过拟合)。

posted on 2018-06-03 13:26 Josie_chen 阅读(333) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号