9-1测试训练好的模型
如何利用retain来实现对图片分类模型的微调
点击右上角绿色的“clone or download”按钮中的“Downloade ZIP”进行下载
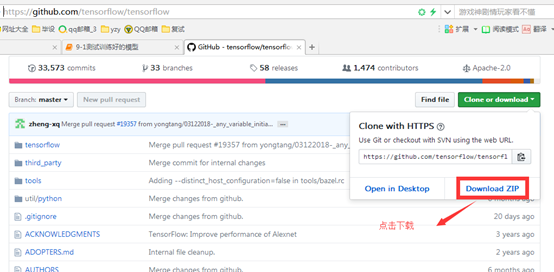
下载得到的文件为tensorflow-master.zip,解压该文件,进入:
tensorflow-master/tensorflow/image_retraining文件夹中retrain.py文件
该网站是英国牛津的科学工程系的VGG(visual Geometry Group)
下载后放到retrain/data/train 中,eg:animal,flower,guitar,house,plane
- 进行训练:在训练的时候,对于每张不同图,会出现不同的值,对于相同图片到pool_3的结果都是固定一样的。实际上可以理解为,我们在训练的时候,由于softmax之前的层都是模型训练好的,固定的,无需修改,所以相当于我们的输入就是softmax前一层pool_3输出的相应数值。提前算好,这样大大减少训练的复杂度。
- 写一个批处理文件:retrain.bat 可以用notepad++打开
google把整个模型比作是一个花瓶,最上面为瓶口,bottle_neck,这里指的就是pool_3的位置。在预处理的时候,将训练集中每张图片输入经过训练好的模型在pool_3处输出相应的数值存放到bottleneck文件目录下(在retrain文件夹中提前创建好该文件)

how_many_training_steps表示训练次数
model_dir 用于训练的inception-v3模型的存放目录。(这里打开的是下载模型的压缩文件,因此要放入的文件应该是inception-2015-12-05.tgz)
- output_graph输出训练好的模型,命名为:output_graph.pb
output_labels 输出训练好的标签output_labels.txt ^
image_dir 输出训练好的标签目录data/train/ 注意将下载好的训练集按照所属名称分别归类放入相应的文件夹中。文件名为类别名,全小写英文单词,避免报错。
- 执行这个脚本文件:retrain.bat,最终会检测到所有分类,利用GPU进行训练,很快执行。
(1) bottleneck文件夹:生成每张图片一一对应的一堆txt文件,分别存放到“retrain/bottleneck/类别名”文件夹中。每训练10steps就打印一次训练准确率,200次得到准确率98%以上。
(2) labels.txt
(3) output_labels.txt
(4) output_graph.pb模型文件,之后我们就可以调用该文件来进行训练了。
创建一个images文件夹存放15张图片:animal1-3,flower1-3,guitar1-3,house1-3,plane1-3
利用9-1程序来进行测试集测试,能够成功达到较好效果:正确分类;置信度很高;
原因:1。用于测试的都是5类完全不同的事物,之间的相似度较低
2.inception模型的预处理达到了较好的效果
微调法(retrain方法)的好处:由于只用了2000张图片对于这样一个庞大的inception模型:
- 计算量少,由于之前的都由模型计算好了,所以只需要计算最后一层就好,需要训练的参数少,因此每个周期迭代次数也比较少,所以比较快。
- 迭代周期也很少,只要200个周期就能达到接近100%的准确率
- 训练数据量很少,只有2000张就能达到理想效果。也不会过拟合等问题出现。这比用9-2的方法好。
posted on 2018-05-21 20:27 Josie_chen 阅读(921) 评论(4) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号