

模块&包
模块&包
模块(modue)的概念:
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在Python中,一个.py文件就称之为一个模块(Module)。
使用模块有什么好处?
最大的好处是大大提高了代码的可维护性。
其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
所以,模块一共三种:
- python标准库
- 第三方模块
- 应用程序自定义模块
另外,使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。
模块导入方法
1 import 语句(每次调用要加上变量名来调用)
import module1[, module2[,... moduleN] #可以同时一起引入两个模块,用逗号隔开
import test # test.py为相对路径(因为当前运行路径)。 import先找到文件,然后把文件在当前路径下执行一遍
#import一般导入一次就会在内存中
from module import test #寻找上一层module下的test.py文件
import sys print(sys.path) #路径文件:python内置的和执行文件所在路径(只含同级,上一级和下一级不算) from my_module import cal #当前路径是bin的,为找与bin同级的my_module包下面的cal文件中的add print(cal.add(3,6)) #引入同级下一级的文件 #错误例子1:如果main.py中import cal # from my_module import main # 解释器只认bin文件的路径,如果main中import cal根本不可能找到cal # main.run() #执行main中的,直接main调用 # 改正:修改main.py中的import语句 # 引入同级下几级的文件:通过点表示 # from web.web1.web2 import cal # from web.web1.web2.cal import add # from web.web1 import web2 #这样是在执行web2_init_文件 # 错误调用方式:web2.cal.add(2,6),最多支持cal.add(2,6) print(_name_) # 结果为_main, 在执行文件中打印 # 若在调用文件中有 print(_name_) 打印当前文件的文件名 from my_module import if __name__ == '__main__': # _name_的作用:1. 如果if __name__ == '__main__'在执行文件中,成立,可以执行下方的main函数 # 同时也不让别的只想调用本文件的一个其他函数的,执行了我的main函数内容 # 2.如果if __name__ == '__main__'在调用文件中,便于测试被调用文件 # 在调用文件下面加上if __name__ == '__main__'然后在下方写测试代码,从而别人来调用时不会执行这些测试代码 # 但是测试代码可以在本调用文件中直接执行进行测试
['', '/usr/lib/python3.4', '/usr/lib/python3.4/plat-x86_64-linux-gnu', '/usr/lib/python3.4/lib-dynload', '/usr/local/lib/python3.4/dist-packages', '/usr/lib/python3/dist-packages']
2 from…import 语句
引入的是函数,从py文件名中引用。从而在以后调用的时候直接写函数名。
from modname import name1[, name2[, ... nameN]]
3 From…import* 语句(不推荐)
把cal中所有函数都引进。
此时有可能你只需要cal中的某个函数,但你不知道别的哪些函数也过来了。
当你在本执行的py文件中,自定义函数的时候,很有可能同名了。此时有可能会调用文件中的了。
from modname import *
# cal中有add函数 def add(x,y): return x+y+100 from cal import * # 不推荐,cal中的add将你自己写的add覆盖了。 print(add(3,6))
4 运行本质
#1 import test #2 from test import add
包(package)
如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)。
package可以放一些文件,内部会有一个阴影文件,例如_init_.py。而文件夹directory没有阴影文件。
举个例子,一个abc.py的文件就是一个名字叫abc的模块,一个xyz.py的文件就是一个名字叫xyz的模块。
现在,假设我们的abc和xyz这两个模块名字与其他模块冲突了,于是我们可以通过包来组织模块,避免冲突。方法是选择一个顶层包名:
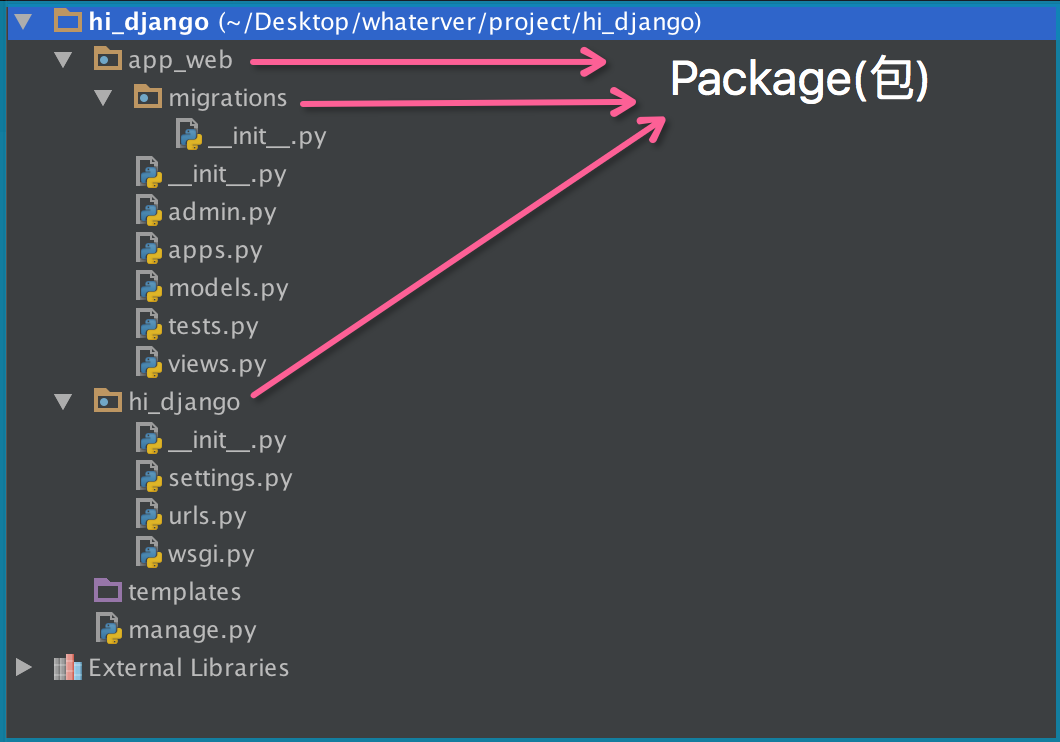
引入了包以后,只要顶层的包名不与别人冲突,那所有模块都不会与别人冲突。现在,view.py模块的名字就变成了hello_django.app01.views,类似的,manage.py的模块名则是hello_django.manage。
请注意,每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录(文件夹),而不是一个包。__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是对应包的名字。
调用包就是执行包下的__init__.py文件
注意点(important)
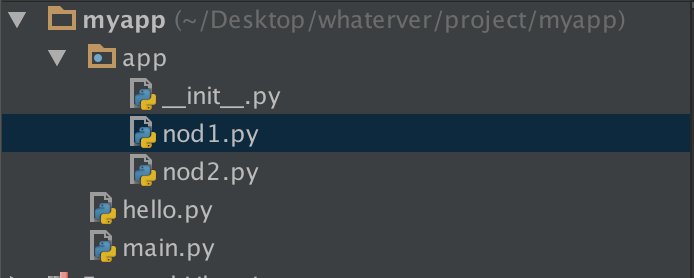
1--------------
在nod1里import hello是找不到的,有同学说可以找到呀,那是因为你的pycharm为你把myapp这一层路径加入到了sys.path里面,所以可以找到,然而程序一旦在命令行运行,则报错。有同学问那怎么办?简单啊,自己把这个路径加进去不就OK啦:
import sys,os BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BASE_DIR) import hello hello.hello1()
if __name__=='__main__': print('ok')
“Make a .py both importable and executable”
如果我们是直接执行某个.py文件的时候,该文件中那么”__name__ == '__main__'“是True,但是我们如果从另外一个.py文件通过import导入该文件的时候,这时__name__的值就是我们这个py文件的名字而不是__main__。
这个功能还有一个用处:调试代码的时候,在”if __name__ == '__main__'“中加入一些我们的调试代码,我们可以让外部模块调用的时候不执行我们的调试代码,但是如果我们想排查问题的时候,直接执行该模块文件,调试代码能够正常运行!s
3

##-------------cal.py def add(x,y): return x+y ##-------------main.py import cal #from module import cal def main(): cal.add(1,2) ##--------------bin.py from module import main main.main()
#注意
# from module import cal 改成 from . import cal同样可以,这是因为bin.py是我们的执行脚本,
# sys.path里有bin.py的当前环境。即/Users/yuanhao/Desktop/whaterver/project/web这层路径,
# 无论import what , 解释器都会按这个路径找。所以当执行到main.py时,import cal会找不到,因为
# sys.path里没有/Users/yuanhao/Desktop/whaterver/project/web/module这个路径,而
# from module/. import cal 时,解释器就可以找到了。
1. time模块(在python内置。内部封装好的,不管什么路径,都能找得到。)
三种时间表示
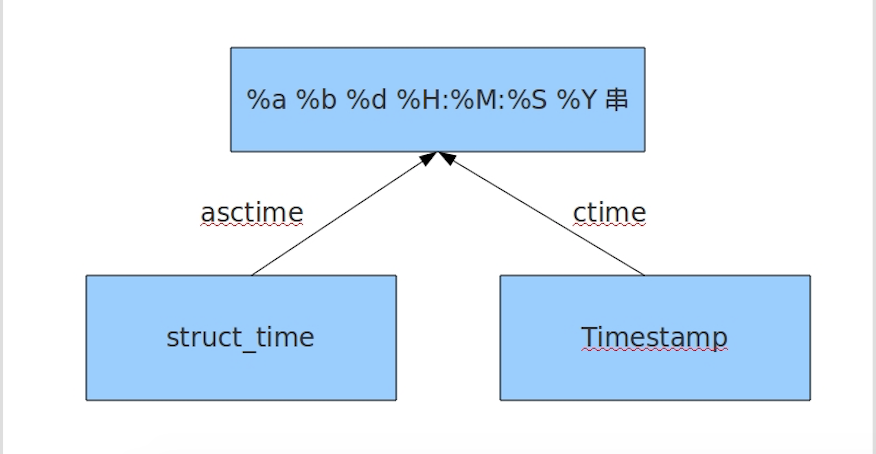
在Python中,通常有这几种方式来表示时间:
- 时间戳(timestamp) : 通常来说,时间戳表示的是从1970年1月1日(unix诞生)00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。为了计时。
- 格式化的时间字符串
- 元组(struct_time) :struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
import time #优先用python解释器提供的,自己定义的暂时不管 # 1 time() :返回当前时间的时间戳 time.time() #1473525444.037215 #---------------------------------------------------------- # 2 localtime([secs])结构化时间:含有时间戳。 # 将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。 time.localtime() #time.struct_time(tm_year=2016, tm_mon=9, tm_mday=11, tm_hour=0, # tm_min=38, tm_sec=39, tm_wday=6, tm_yday=255, tm_isdst=0)
# 结构化时间:可以操纵当中的某一个值
t = time.localtime()
print(t.tm_year)
time.localtime(1473525444.037215) #将当前时间戳转化为结构化时间,能看出来
#----------------------------------------------------------
# 3 gmtime([secs]) 和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。
print(t.tm_gmtime()) #24区,每15度为一个区,中国东八区。UTC世界标准时间
#----------------------------------------------------------
# 4 mktime(t) : 将一个struct_time转化为时间戳。 需要参数
print(time.mktime(time.localtime())) #1473525749.0
#----------------------------------------------------------
# 5 asctime([t]) :把结构化时间转化为固定字符串表达形式。类似strftime
# 把一个表示时间的元组或者struct_time表示为这种形式:'Sun Jun 20 23:21:05 1993'。
# 如果没有参数,将会将time.localtime()作为参数传入。
print(time.asctime())#Sun Sep 11 00:43:43 2016
#----------------------------------------------------------
# 6 ctime([secs]) : 把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。
# 如果参数未给或者为None的时候,将会默认time.time()为参数。
# 它的作用相当于time.asctime(time.localtime(secs))。
print(time.ctime()) # Sun Sep 11 00:46:38 2016
print(time.ctime(time.time())) # Sun Sep 11 00:46:38 2016
#----------------------------------------------------------
# 7 strftime(format[, t]) : 用的最多,最直观。类似asctime,但自己指定字符串时间的格式
# 把一个代表时间的元组或者struct_time(如由time.localtime()和
# time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。如果元组中任何一个
# 元素越界,ValueError的错误将会被抛出。
print(time.strftime("%Y-%m-%d %X", time.localtime()))#2016-09-11 00:49:56
# 年%Y 月%m 日%d 时分秒%d
#----------------------------------------------------------
# 8 time.strptime(string[, format]) (字符串,字符串结构)作为参数,进行对应好才能准确拆解
# 把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。
print(time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X'))
#time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=37, tm_sec=6,
# tm_wday=3, tm_yday=125, tm_isdst=-1)
#在这个函数中,format默认为:"%a %b %d %H:%M:%S %Y"。 # 9 sleep(secs) # 线程推迟指定的时间运行,单位为秒。
# 10 clock()
# 这个需要注意,在不同的系统上含义不同。在UNIX系统上,它返回的是“进程时间”,它是用秒表示的浮点数(时间戳)。
# 而在WINDOWS中,第一次调用,返回的是进程运行的实际时间。而第二次之后的调用是自第一次调用以后到现在的运行
# 时间,即两次时间差。

# 显示结果比asctime看起来更直观顺眼 import datetime print(datetime.datetime.now()) #2016-12-12 17:59:46.316449
help(time)
help(time.asctime) #直接就帮你排好
2. random模块(* *)
import random print(random.random())#(0,1)----float 0,1之间的浮点数 print(random.randint(1,3)) #[1,3]整形数:1,2,3 print(random.randrange(1,3)) #[1,3) 整形左闭右开1,2 print(random.choice([1,'23',[4,5]])) #23 对可迭代对象中的元素进行随机选取 print(random.sample([1,'23',[4,5]],2)) #[[4, 5], '23']每次随机选两个 print(random.uniform(1,3)) #1.927109612082716 取任意范围的浮点数 # 了解shuffle item=[1,3,5,7,9] random.shuffle(item) #打乱item中的元素。不需要一个变量来接收,直接改变item中次序 print(item)
#验证码 import random def v_code(): code = '' #空字符串 for i in range(5): num=random.randint(0,9) alf=chr(random.randint(65,122)) #a到Z add=random.choice([num,alf]) #打乱字母和数字的顺序,在字母数字之间随机选一个(两个之间选,显然等概率) code += str(add) #将每次循环的结果拼接起来 return code print(v_code())
3. os模块(* * * *)重要
os模块是与操作系统交互的一个接口
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd # os.curdir 返回当前目录: ('.') # os.pardir 获取当前目录的父目录字符串名:('..') os.makedirs('dirname1/dirname2') 可生成多层递归目录 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat('path/filename') 获取文件/目录信息,size,atime用户上一次访问时间,mtime上一次修改时间(修改必定也算访问),ctime创建时间 os.sep 输出当前操作系统特定的路径分隔符,win下为"\\",Linux下为"/" os.linesep 输出当前平台使用的行终止符,win下为"\r\n",Linux下为"\n" os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为: 例如path环境变量中路径的划分 # os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' os.system("bash command") 运行shell命令,直接显示。类似在终端直接执行一段命令 os.environ 获取系统环境变量 os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合拼接后返回,不采用加号。默认找到你所用的操作系统对应的分隔符,然后拼接起来。
# 第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
4. sys模块(* * *)
sys.argv #命令行参数List,第一个元素是程序本身路径;在终端执行 sys.exit(n) # 退出程序,正常退出时exit(0) sys.version # 获取Python解释程序的版本信息 sys.maxint # 最大的Int值 sys.path # 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform #返回操作系统平台名称,程序能不能在此操作系统运行
#一次性输入全部命令参数,利用argv来获取,以后就不用一次次输入命令了 import sys print(sys.argv) #命令行后面可以加命令,程序中就能对你输入的进行解析,获取你输入的命令 command = sys.argv[1] path = sys.argv[2] if command == "post": pass elif command=="hbv": pass
sys.stdout.write("#") #向屏幕打印
#想要修改环境变量 import sys sys.path.append() #临时修改。永久修改依旧要去系统中修改
# 为了找到上级的目录,os.path.dirname, BASEDIR # 而且不能写死路径,为了让别人也能找。 import sys,os if _name_="_main_": print(os.path.abspath(_file_)) #在调用文件中输出为执行路径,在被调用文件中输出结果为文件名。 #但在pycharm中会帮你补全文件名之前的目录名字,即输出了绝对路径加上自己的文件名。终端中可以看出来只有文件名:_file_ print(os.path.dirname(os.path.abspath(_file_))) #得到本执行文件所在的绝对路径,不含自己的文件名 BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(_file_))) #得到上上级的绝对路径 sys.path.append(BASE_DIR) main.run()
进度条:用于查看文件上传的时候的进度百分比
import sys,time for i in range(10): sys.stdout.write('#') #先把要打印的放在缓存中,最后一起讲全部的向屏幕打印 time.sleep(1) #为了看到一个个打印,减缓打印速度 sys.stdout.flush() #必须要加上此句,否则看不到一步步打印的效果。刷新,现在缓存里有多少都打印出来,然后清空掉缓存
5. json & pickle(* * * *)重要
json可以进行任何数据类型的转换,不同语言之间也可以。
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
# 向文本中存一个字典,得变成一个字符串 dic = {"name":"alex"} f = open("hello","w") # 错解:f.write(dic) #不能直接写字典,得存字符串 # 更正为原来的方法: f_read=open("hello","r") data=f_read.read() print(type(data)) #<class 'str'> data=eval(data) #eval局限性:函数,类无法用eval进行转换 print(data["name"]) # json可以实现所有数据类型转换 dumps() dump() import json data=json.dumps(dic) #变成json字符串:必须所有字符串全双引号 #把所有的都变成字符串:无论数字、列表、元祖........ print(data) #{"name": "alex"} print(type(data)) dic={'name':'alex'}#---->变为json数据:{"name":"alex"}--->'{"name":"alex"}' i=8 #---->'8' s='hello' #---->"hello"------>'"hello"' l=[11,22] #---->"[11,22]" # 用途:传输(为了前后端,封装成字符串之后便于识别) #利用json.dumps()手动存入文件中,json.dump()为一种简写,但只对文件处理进行简写 f=open("new_hello","w") dic_str=json.dumps(dic) f.write(dic_str)
#上面后两行相当于这一句话:json.dump(dic,f)
#通过json.loads()把它取出来,便于给别的语言转化为他们自己对应的数据类型之后,利用数据 f_read=open("new_hello","r") data=json.loads(f_read.read())
# 上面两句相当于:data=json.load(f) print(data["name"]) print(data) #字符串又变回到字典了 print(type(data)) x="[null,true,false,1]" print(eval(x)) print(json.loads(x))
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,dump过程。在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。load过程
5.1 json (eval的升级版)
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:

#json序列化结果为字符串 import json dic={'name':'alvin','age':23,'sex':'male'} print(type(dic))#<class 'dict'> j=json.dumps(dic) print(type(j))#<class 'str'> f=open('序列化对象','w') f.write(j) #-------------------等价于json.dump(dic,f) f.close() #-----------------------------反序列化<br> import json f=open('序列化对象') data=json.loads(f.read())# 等价于data=json.load(f)
#注意: import json #dct="{'1':111}"#json 不认单引号 #dct=str({"1":111})#报错,因为生成的数据还是单引号:{'one': 1} dct='{"1":"111"}' print(json.loads(dct))
with open("Json_test","r") as f: # Json_test中内容为 {"name": "alex"}
data=f.read()
data=json.loads(data)
print(data["name"]) # alex
# 无论数据是怎样创建的,(并不一定要利用dump来创建)只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads
5.2 pickle模块
##pickle序列化结果为字节 import pickle dic={'name':'alvin','age':23,'sex':'male'} print(type(dic)) #<class 'dict'> j=pickle.dumps(dic) print(type(j)) #<class 'bytes'> f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,变量j的数据类型是'bytes' f.write(j) #-----这两句等价于pickle.dump(dic,f)。注意pickle处理后的数据没办法直接print成我们能看懂的 f.close() #-------------------------反序列化 import pickle f=open('序列化对象_pickle','rb') data=pickle.loads(f.read()) #这两句等价于data=pickle.load(f),将数据读出来 print(data['age']) #23
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
Pickle支持函数、类等所有类型。但使用少,多用json。
6. shelve模块(* * *)
shelve模块比pickle模块简单,也是用于数据传输。不能跨语言传送,只能python。只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型。
实质将pickle封装在shelve当中,从而让我们可以像操作字典一样,因此优势仅在简单好用。
import shelve f = shelve.open(r'shelve.txt') # 目的:将一个字典放入文本 f={} #f本来就是一个字典,可以往里面写东西: f['stu1_info']={'name':'alex','age':'18'} #f后的中括号内为字典的key,等号后面为相应key对应的value f['stu2_info']={'name':'alvin','age':'20'} f['school_info']={'website':'oldboyedu.com','city':'beijing'} #打开写完后shelve.txt文件,发现写入的看不懂。即不是直接能看到写的是啥 f.close() f = shelve.open(r'shelve.txt') print(f.get('stu_info')['age']) #虽然不能直接在txt文件中看,但可以用get取出相应的value
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,在json还没诞生的黑暗年代,大家只能选择用xml,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
#标签语言:所有语法通过标签来实现 #两种标签:自闭合标签(如下neighbor),非闭合标签(有头有尾的,如下rank,year)
# xml数据: <?xml version="1.0"?> <data> #根标签,没有属性 <country name="Liechtenstein"> # 标签名叫country,属性(一对键值对:属性名+属性值)为:name="Liechtenstein" <rank updated="yes">2</rank> <year>2008</year> <gdppc>141100</gdppc> <neighbor name="Austria" direction="E"/> # 有两个属性 <neighbor name="Switzerland" direction="W"/> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year>2011</year> <gdppc>59900</gdppc> <neighbor name="Malaysia" direction="N"/> </country> <country name="Panama"> <rank updated="yes">69</rank> <year>2011</year> <gdppc>13600</gdppc> <neighbor name="Costa Rica" direction="W"/> <neighbor name="Colombia" direction="E"/> </country> </data>
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml:
import xml.etree.ElementTree as ET # 利用as将前面的很长的文件名替代为ET #“读”:parse解析原xml文件内容,读到对象tree中。对象可以来调用方法 #上一程序块的xml数据文件名字为xmltest.xml:文档树 tree = ET.parse("xmltest.xml") root = tree.getroot() print(root.tag) #拿到的根节点的的tag,<date>没有属性
for i in root:
print(i) #结果为几个country的地址,表示指向的是三个子对象country
print(i.tag) #打印出三个子对象对应的标签。发现country标签下还有子标签,说明它也还可以遍历
print(i.attrib) #打印出属性
# print(i.text) #打印出标签中的内容,data标签中全是标签,<data>中没有
for j in i:
print(j.tag) #从而打印出所有的标签,遍历出所有标签
print(j.text) #直接只打印出所有标签中内容,换行隔开
#遍历xml文档:for循环根节点 for child in root: print(child.tag, child.attrib) for i in child: print(i.tag,i.text) #只遍历year 节点 for node in root.iter('year'): print(node.tag,node.text)
# 输出结果为:
# year 2008
# year 2011
# year 2011 #--------------------------------------- import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml") root = tree.getroot() #set修改 for node in root.iter('year'): new_year = int(node.text) + 1 #将每个year标签中的字符串内容提取转化为数值,并将内容加1 node.text = str(new_year) #将修改后的数值转化为字符串之后赋值给原标签 node.set("updated","yes") #属性名,属性值 tree.write("xmltest.xml") #修改结束后还需要重新写入一个文件中才能生效。可以新建一个文件,可以和源文件同名直接覆盖 #find通过标签找到相应内容 #remove删除node:取出标签中rank小于5的直接删掉。遍历country将其中的rank拿出来比较 for country in root.findall('country'): rank = int(country.find('rank').text) if rank > 50: root.remove(country) tree.write('output.xml')
自己创建xml文档:
# 创建 import xml.etree.ElementTree as ET #先取出模块 new_xml = ET.Element("namelist") #创建根节点<namelist> </namelist> name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"}) #对new_xml 添加一个name子标签 #对name添加age和sex两个子标签 age = ET.SubElement(name,"age",attrib={"checked":"no"}) sex = ET.SubElement(name,"sex") sex.text = '33' #对new_xml添加子标签name name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"}) #变量名得叫name2,但标签仍叫name age = ET.SubElement(name2,"age") age.text = '19' #下面两句固定模式:记住 et = ET.ElementTree(new_xml) #生成文档对象 et.write("test.xml", encoding="utf-8",xml_declaration=True) #生成test.xml文件 ET.dump(new_xml) #打印生成的格式
8. configparser模块(* *) 配置文件的解析模块
来看一个好多软件的常见文档格式如下:
#针对配置文件而开发的模块,只会针对配置文件进行操作 # 配置文件confile.txt中的内容: [DEFAULT] ` #相当于字典的键 ServerAliveInterval = 45 #属性:键值对(属性名=属性值) Compression = yes CompressionLevel = 9 ForwardX11 = yes [bitbucket.org] User = hg [topsecret.server.com] Port = 50022 ForwardX11 = no
import configparser config = configparser.ConfigParser() #创建一个对象,相当于有一个空字典,相当于已经创建好的配置文本 config["DEFAULT"] = {'ServerAliveInterval': '45', #字典中的键值对,其中每个键值对的键又对应一个小字典 'Compression': 'yes', 'CompressionLevel': '9'}
#创建字典块1: bitbucket.org config['bitbucket.org'] = {} config['bitbucket.org']['User'] = 'hg' #向空字典中加入键值对(user,hg)
#创建字典块2:topsecret.server.com中添加两组键值对
config['topsecret.server.com'] = {} topsecret = config['topsecret.server.com'] topsecret['Host Port'] = '50022' # mutates the parser topsecret['ForwardX11'] = 'no' # same here
config['DEFAULT']['ForwardX11'] = 'yes'<br> with open('example.ini', 'w') as configfile: #写到文件中 config.write(configfile) #原来的写法:句柄configfile.write(),现在的写法,利用对象config.write(句柄configfile)
import configparser # 在取“字典键名”时,不区分大小写 config = configparser.ConfigParser() #得到一个对象 #------------------------查 print(config.sections()) #[] 还没有和任何文件联系起来,肯定为空 config.read('example.ini') #先用对象把文件读进来,文件和对象联系起来 print(config.sections()) #['bitbucket.org',topsecret.server.com'] #打印出除了default以外的块名 print('bytebong.com' in config)# False 判断一下用户输入的字符串是否在配置文件中 print(config['bitbucket.org']['User']) # hg 取出块中的某个键对应的属性值 print(config['DEFAULT']['Compression']) #yes print(config['topsecret.server.com']['ForwardX11']) #no for key in config['bitbucket.org']: #遍历字典,打印出字典的键 print(key) #但这样的结果是,不仅仅遍历出来了本字典的,还将default中的也遍历出来了附在后面。即default内一般放入很重要的信息,你查什么它都能出现,减少文件内容的重复 # user #本字典的 # serveraliveinterval #default中的 # compression # compressionlevel # forwardx11 print(config.options('bitbucket.org'))#['user', 'serveraliveinterval', 'compression', 'compressionlevel', 'forwardx11']
#将遍历出的字典键名放到列表当中(类似遍历key) print(config.items('bitbucket.org')) #[('serveraliveinterval', '45'), ('compression', 'yes'), ('compressionlevel', '9'), ('forwardx11', 'yes'), ('user', 'hg')]
#items将字典中的属性名和属性值放在一起组成一个键值对元祖,然后放入列表中输出(default中的也会输出) print(config.get('bitbucket.org','compression')) #yes #default中的在下面的块中也能访问到,所以也算是在此字典块中.get拿到键后去找对应块下面的属性键,看是否能匹配。
#--------------------------删,改,增(config.write(open('i.cfg', "w"))) 均会修改文件内容,所以写完之后一定要覆盖掉原文件,或者新建一个文件来保存 config.add_section('yuan') #增加一个名为yuan的块,然后连同原文件中的所有块一起写入一个新的文件 config.remove_section('topsecret.server.com') #删除一个块 config.remove_option('bitbucket.org','user') #删除bitbucket块下的一个键值对user config.set('bitbucket.org','k1','11111') #在bitbucket.org中增加新的键值对
config.write(open('i.cfg', "w")) #不用关闭文件了。因为不是用文件句柄来调用的。
9. hashlib模块(* *)
用于加密相关的操作,摘要算法。3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法。
单向操作:把一个不定长的字符串转化为定长的hash值。
用途:1.存储用户名和密码转化后的不能反解密文。
2.用户输入名和密码之后就能进行算法计算出密文,与存储的密文进行比较,只能用匹配数据库纯对应找原文。
3.原生MD5明密文大家都能知道,因此添加混淆值,让别人无法反解
安全性与加密位数关系不大,最重要是算法。但如果算法越复杂,加密时间越长。
import hashlib m=hashlib.md5() # m=hashlib.sha256()
# m=hashlib.md5('sb',encode('utf8')) #sb只有自己才知道,混淆后别人很难与原生的匹配
m.update('hello'.encode('utf8')) #hello字符串变成字节,utf8编码 print(m.hexdigest()) #5d41402abc4b2a76b9719d911017c592 十六进制表示,固定32位 m.update('alvin'.encode('utf8')) #在上一步的基础上(即在hello后面加上alvin字符串之后)再进行整体加密输出加密后字符串
print(m.hexdigest()) #92a7e713c30abbb0319fa07da2a5c4af m2=hashlib.md5() m2.update('helloalvin'.encode('utf8')) print(m2.hexdigest()) #92a7e713c30abbb0319fa07da2a5c4af
import hashlib # ######## SHA256 ######## hash = hashlib.sha256('898oaFs09f'.encode('utf8')) hash.update('alvin'.encode('utf8')) print (hash.hexdigest())#e79e68f070cdedcfe63eaf1a2e92c83b4cfb1b5c6bc452d214c1b7e77cdfd1c7
python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密:
import hmac h = hmac.new('alvin'.encode('utf8')) h.update('hello'.encode('utf8')) print (h.hexdigest())#320df9832eab4c038b6c1d7ed73a5940
当我们需要调用系统的命令的时候,最先考虑的os模块。用os.system()和os.popen()来进行操作。但是这两个命令过于简单,不能完成一些复杂的操作,如给运行的命令提供输入或者读取命令的输出,判断该命令的运行状态,管理多个命令的并行等等。这时subprocess中的Popen命令就能有效的完成我们需要的操作。
The subprocess module allows you to spawn new processes, connect to their input/output/error pipes, and obtain their return codes.
This module intends to replace several other, older modules and functions, such as: os.system、os.spawn*、os.popen*、popen2.*、commands.*
这个模块一个类:Popen。
|
1
2
3
|
#Popen它的构造函数如下:subprocess.Popen(args, bufsize=0, executable=None, stdin=None, stdout=None,stderr=None, preexec_fn=None, close_fds=False, shell=False,<br> cwd=None, env=None, universal_newlines=False, startupinfo=None, creationflags=0) |
 parameter
parameter简单命令:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import subprocessa=subprocess.Popen('ls')# 创建一个新的进程,与主进程不同步print('>>>>>>>',a)#a是Popen的一个实例对象'''>>>>>>> <subprocess.Popen object at 0x10185f860>__init__.py__pycache__log.pymain.py'''# subprocess.Popen('ls -l',shell=True)# subprocess.Popen(['ls','-l']) |
subprocess.PIPE
在创建Popen对象时,subprocess.PIPE可以初始化stdin, stdout或stderr参数。表示与子进程通信的标准流。
|
1
2
3
4
5
6
|
import subprocess# subprocess.Popen('ls')p=subprocess.Popen('ls',stdout=subprocess.PIPE)#结果跑哪去啦?print(p.stdout.read())#这这呢:b'__pycache__\nhello.py\nok.py\nweb\n' |
这是因为subprocess创建了子进程,结果本在子进程中,if 想要执行结果转到主进程中,就得需要一个管道,即 : stdout=subprocess.PIPE
subprocess.STDOUT
创建Popen对象时,用于初始化stderr参数,表示将错误通过标准输出流输出。
Popen的方法


Popen.poll() 用于检查子进程是否已经结束。设置并返回returncode属性。 Popen.wait() 等待子进程结束。设置并返回returncode属性。 Popen.communicate(input=None) 与子进程进行交互。向stdin发送数据,或从stdout和stderr中读取数据。可选参数input指定发送到子进程的参数。 Communicate()返回一个元组:(stdoutdata, stderrdata)。注意:如果希望通过进程的stdin向其发送数据,在创建Popen对象的时候,参数stdin必须被设置为PIPE。同样,如 果希望从stdout和stderr获取数据,必须将stdout和stderr设置为PIPE。 Popen.send_signal(signal) 向子进程发送信号。 Popen.terminate() 停止(stop)子进程。在windows平台下,该方法将调用Windows API TerminateProcess()来结束子进程。 Popen.kill() 杀死子进程。 Popen.stdin 如果在创建Popen对象是,参数stdin被设置为PIPE,Popen.stdin将返回一个文件对象用于策子进程发送指令。否则返回None。 Popen.stdout 如果在创建Popen对象是,参数stdout被设置为PIPE,Popen.stdout将返回一个文件对象用于策子进程发送指令。否则返回 None。 Popen.stderr 如果在创建Popen对象是,参数stdout被设置为PIPE,Popen.stdout将返回一个文件对象用于策子进程发送指令。否则返回 None。 Popen.pid 获取子进程的进程ID。 Popen.returncode 获取进程的返回值。如果进程还没有结束,返回None。
supprocess模块的工具函数
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
supprocess模块提供了一些函数,方便我们用于创建进程来实现一些简单的功能。subprocess.call(*popenargs, **kwargs)运行命令。该函数将一直等待到子进程运行结束,并返回进程的returncode。如果子进程不需要进行交 互,就可以使用该函数来创建。subprocess.check_call(*popenargs, **kwargs)与subprocess.call(*popenargs, **kwargs)功能一样,只是如果子进程返回的returncode不为0的话,将触发CalledProcessError异常。在异常对象中,包 括进程的returncode信息。check_output(*popenargs, **kwargs)与call()方法类似,以byte string的方式返回子进程的输出,如果子进程的返回值不是0,它抛出CalledProcessError异常,这个异常中的returncode包含返回码,output属性包含已有的输出。getstatusoutput(cmd)/getoutput(cmd)这两个函数仅仅在Unix下可用,它们在shell中执行指定的命令cmd,前者返回(status, output),后者返回output。其中,这里的output包括子进程的stdout和stderr。 |
import subprocess
#1
# subprocess.call('ls',shell=True)
'''
hello.py
ok.py
web
'''
# data=subprocess.call('ls',shell=True)
# print(data)
'''
hello.py
ok.py
web
0
'''
#2
# subprocess.check_call('ls',shell=True)
'''
hello.py
ok.py
web
'''
# data=subprocess.check_call('ls',shell=True)
# print(data)
'''
hello.py
ok.py
web
0
'''
# 两个函数区别:只是如果子进程返回的returncode不为0的话,将触发CalledProcessError异常
#3
# subprocess.check_output('ls')#无结果
# data=subprocess.check_output('ls')
# print(data) #b'hello.py\nok.py\nweb\n'
交互命令:
终端输入的命令分为两种:
- 输入即可得到输出,如:ifconfig
- 输入进行某环境,依赖再输入,如:python
需要交互的命令示例
待续
11. logging模块(* * * * *)重要:做日志
一 (简单应用)用logger对象就可以直接调用
import logging # 日志级别:默认级别warning,只会显示warning及以上级别 logging.debug('debug message') logging.info('info message') logging.warning('warning message') logging.error('error message') logging.critical('critical message')
输出:
“级别名:用户:你规定打印的信息”
WARNING:root:warning message
ERROR:root:error message
CRITICAL:root:critical message
可见,默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET),默认的日志格式为日志级别:Logger名称:用户输出消息。
这么设置的目的是为了:在debug的时候还需要查看debug和info信息,但在实际使用的时候只需要关注warning、error和critical的信息即可。
二 灵活配置日志级别,日志格式,输出位置
1. basicConfig
import logging # 将级别调整为DEBUG logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
#日志打印格式:asctime时间,filename文件名,lineno打印日志的代码行号,message用户自己想要打印的内容, datefmt='%a, %d %b %Y %H:%M:%S', # filename='/tmp/test.log', #写完日志后,并不是想要直接打印到屏幕上,更多的是将日志存下来到文件中,加上filename后就会将执行结果放到文件中。 filemode='w') #添加日志内容默认模式是追加模式。如果自己指定为w模式,则直接写入 logging.debug('debug message') logging.info('info message') logging.warning('warning message') logging.error('error message') logging.critical('critical message')
cat /tmp/test.log
Mon, 05 May 2014 16:29:53 test_logging.py[line:9] DEBUG debug message
Mon, 05 May 2014 16:29:53 test_logging.py[line:10] INFO info message
Mon, 05 May 2014 16:29:53 test_logging.py[line:11] WARNING warning message
Mon, 05 May 2014 16:29:53 test_logging.py[line:12] ERROR error message
Mon, 05 May 2014 16:29:53 test_logging.py[line:13] CRITICAL critical message
可见在logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。若没有直接打印到屏幕上。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open('test.log','w')),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略,即不能 同时打印屏幕并写到函数中, 打印到屏幕上用stream。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
2. logger对象
上述几个例子中我们了解到了logging.debug()、logging.info()、logging.warning()、logging.error()、logging.critical()(分别用以记录不同级别的日志信息),logging.basicConfig()(用默认日志格式(Formatter)为日志系统建立一个默认的流处理器(StreamHandler),设置基础配置(如日志级别等)并加到root logger(根Logger)中)这几个logging模块级别的函数,另外还有一个模块级别的函数是logging.getLogger([name])(返回一个logger对象,如果没有指定名字将返回root logger)
先看一个最简单的过程:
import logging logger = logging.getLogger() # 创建一个handler,用于写入日志文件 fh = logging.FileHandler('test.log') #fh可以向文件发送日志内容,参数为文件名 # 再创建一个handler,用于输出到控制台 ch = logging.StreamHandler() #可以向屏幕发送日志内容 formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') #存储格式信息的对象formatter fh.setFormatter(formatter) #fh和ch分别“吸收”修改格式的对象formatter ch.setFormatter(formatter) logger.addHandler(fh) # 向文件打印 #logger对象可以添加多个fh和ch对象,logger”吸收”fh和ch logger.addHandler(ch) # 向屏幕打印 logger.setLevel("DEBUG") # 设定默认级别 logger.debug('logger debug message') logger.info('logger info message') logger.warning('logger warning message') logger.error('logger error message') logger.critical('logger critical message')
先简单介绍一下,logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。
(1)
Logger是一个树形层级结构,输出信息之前都要获得一个Logger(如果没有显示的获取则自动创建并使用root Logger,如第一个例子所示)。
logger = logging.getLogger()返回一个默认的Logger也即root Logger,并应用默认的日志级别、Handler和Formatter设置。
当然也可以通过Logger.setLevel(lel)指定最低的日志级别,可用的日志级别有logging.DEBUG、logging.INFO、logging.WARNING、logging.ERROR、logging.CRITICAL。
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical()输出不同级别的日志,只有日志等级大于或等于设置的日志级别的日志才会被输出。
logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
只输出了
2014-05-06 12:54:43,222 - root - WARNING - logger warning message
2014-05-06 12:54:43,223 - root - ERROR - logger error message
2014-05-06 12:54:43,224 - root - CRITICAL - logger critical message
从这个输出可以看出logger = logging.getLogger()返回的Logger名为root。这里没有用logger.setLevel(logging.Debug)显示的为logger设置日志级别,所以使用默认的日志级别WARNIING,故结果只输出了大于等于WARNIING级别的信息。
(2) 如果我们再创建两个logger对象:
################################################## logger1 = logging.getLogger('mylogger') logger1.setLevel(logging.DEBUG) #应该打印5条 logger2 = logging.getLogger('mylogger') logger2.setLevel(logging.INFO) #应该打印4条,与logger1中同为一个对象mylogger logger1.addHandler(fh) logger1.addHandler(ch) logger2.addHandler(fh) logger2.addHandler(ch) logger1.debug('logger1 debug message') logger1.info('logger1 info message') logger1.warning('logger1 warning message') logger1.error('logger1 error message') logger1.critical('logger1 critical message') logger2.debug('logger2 debug message') logger2.info('logger2 info message') logger2.warning('logger2 warning message') logger2.error('logger2 error message') logger2.critical('logger2 critical message')

这里有两个个问题:
<1>我们明明通过logger1.setLevel(logging.DEBUG)将logger1的日志级别设置为了DEBUG,为何显示的时候没有显示出DEBUG级别的日志信息,而是从INFO级别的日志开始显示呢?
原来logger1和logger2对应的是同一个Logger实例,只要logging.getLogger(name)中名称参数name相同则返回的Logger实例就是同一个,且仅有一个,也即name与Logger实例一一对应。在logger2实例中通过logger2.setLevel(logging.INFO)设置mylogger的日志级别为logging.INFO,所以最后logger1的输出遵从了后来设置的日志级别。root下会是同一个对象,即只会遵循一个级别。
重新创建logger2=logging.getLogger('mylogger.sontree'),为mylogger的子对象
<2>为什么logger1、logger2对应的每个输出分别显示两次?(了解)
这是因为我们通过logger = logging.getLogger()显示的创建了root Logger,而logger1 = logging.getLogger('mylogger')创建了root Logger的孩子(root.)mylogger,logger2同样。而孩子,孙子,重孙……既会将消息分发给他的handler进行处理也会传递给所有的祖先Logger处理。寻找当前有几重父辈,一重就多打印一次。(了解)
ok,那么现在我们把
# logger.addHandler(fh)
# logger.addHandler(ch) 注释掉,我们再来看效果:
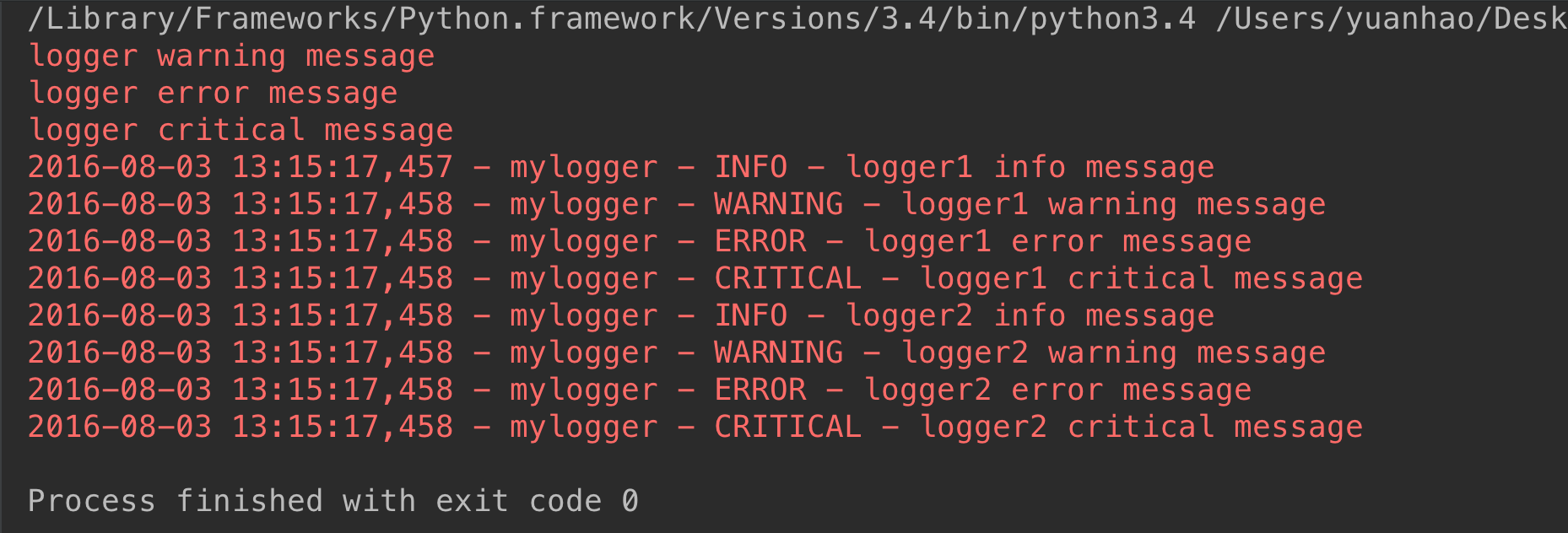
因为我们注释了logger对象显示的位置,所以才用了默认方式,即标准输出方式。因为它的父级没有设置文件显示方式,所以在这里只打印了一次。
孩子,孙子,重孙……可逐层继承来自祖先的日志级别、Handler、Filter设置,也可以通过Logger.setLevel(lel)、Logger.addHandler(hdlr)、Logger.removeHandler(hdlr)、Logger.addFilter(filt)、Logger.removeFilter(filt)。设置自己特别的日志级别、Handler、Filter。若不设置则使用继承来的值。
<3>Filter
限制只有满足过滤规则的日志才会输出。
比如我们定义了filter = logging.Filter('a.b.c'),并将这个Filter添加到了一个Handler上,则使用该Handler的Logger中只有名字带 a.b.c前缀的Logger才能输出其日志。
filter = logging.Filter('mylogger')
logger.addFilter(filter)
这是只对logger这个对象进行筛选
如果想对所有的对象进行筛选,则:
filter = logging.Filter('mylogger')
fh.addFilter(filter)
ch.addFilter(filter)
这样,所有添加fh或者ch的logger对象都会进行筛选。
12. re模块(* * * * *) 正则
就其本质而言,正则表达式(或 RE)是一种小型的、高度专业化(直接针对字符串处理,而字符串是我们经常会遇到的类型)的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行,速度快。所有里面都有正则,不是python独有的
问题描述:1.要提取出一段字符串中的所有数字:hli23vd4ho56isfs789nkj455b,如果直接用字符串的话,只能一个个for循环,而且还不一定是一位的数字,可能还是两位三位的,这将非常复杂
2.快速进行匹配要判断是否满足某种格式:例如ip地址格式(点分十进制位数、数字取值范围等等)、邮件格式
字符匹配(普通字符,元字符):完全匹配,没办法模糊匹配
1 普通字符:大多数字符和字母都会和自身匹配
>>> re.findall('alvin','yuanaleSxalexwupeiqi')
['alvin']
2 元字符:. ^ $ * + ? { } [ ] | ( ) \
元字符之. ^ $ * + ? { } 提供模糊匹配的可能
import re
#findall将所有满足条件的字符串都取出来 ret=re.findall('a..in','helloalvin') #(匹配规则,待匹配的字符串)普通字符完全按照一对一的去匹配 print(ret)#['alvin'] # . 通配符:什么都可以代替,出来换行符\n。一个点只代表一个符号,不能代表若干个 ret=re.findall('^a...n','alvinhelloawwwn') # ^ 以什么开头:从字符串开头开始匹配,如果开头没有,结果必然为空 print(ret)#['alvin'] ret=re.findall('a...n$','alvinhelloawwwn') # $以什么结尾,注意:不是一个普通字符,如果远字符串含有$,并不会与此$进行匹配 print(ret)#['awwwn'] # 如果需要用重复的 * + ? ret=re.findall('abc*','abcccc')#贪婪匹配[0,+oo] # 按照*紧挨着的字符进行重复匹配,重复次数不限,如果没有c也可以(即匹配次数0到无穷次) print(ret)#['abcccc'] ret=re.findall('abc+','abccc')#[1,+oo] #和*一样,但是匹配次数1到无穷次,即必须要有一次 print(ret)#['abccc'] ret=re.findall('abc?','abccc')#[0,1] 一个或者0个c print(ret)#['abc'] ret=re.findall('abc{1,4}','abccc') #指定匹配个数 print(ret)#['abccc'] 贪婪匹配
ret=re.findall('abc*?','abcccccc') #匹配0次 print(ret) #['ab']
ret=re.findall('abc+?','abcccccc') #匹配1次
print(ret) #['abc']
#-----------字符集[] ret=re.findall('a[oldboy baidu]d','abaidud') print(ret) #['abd'] #并没有把baidu全部整出来
ret=re.findall("a[yz]","xyuuuzjcx")
print(ret) #['ay','az']
ret=re.findall("q[a* z]","ksadfkq") #[]中括号中至少得有一个
ret=re.findall("q[a*z]","ksadfkqaa") #['qa']匹配一个a
ret=re.findall("q[a*z]","ksadfkq*") #['q*'] # 符号*作为普通符号进行匹配,因此[a*z]不在代表a到z,表示的是三个普通字符a * z
ret=re.findall('[.*+]','a.cd+') #全都变普通符号了,不具有特殊含义了 print(ret) #['.', '+'] #在字符集里有功能的符号: - ^ \ ret=re.findall('[1-9]','45dha3') #代表1到9的范围 print(ret)#['4', '5', '3'] ret=re.findall('[^ab]','45bdha3') #字符集中的^表示非,即除了a和b以外的全部匹配出来 print(ret) #['4', '5', 'd', 'h', '3']
ret=re.findall('[a-z]','acd')
print(ret) #['a', 'c', 'd']
# 求一个表达式的数值:先求最里层括号的表达式数值,一层层到最外层
#元字符中要是想要括号变成一个普通的括号加上\转义符,即\(
#字符集中的括号就是一个普通括号
re.findall("\([^()]*\)","12+(34*6+2-5*(2-1))")
#以括号开头,以括号结尾且此括号内没有内层的括号了,即此括号内为最内层了,加*表示将2-1的运算直接取出来
反斜杠后边跟元字符去除特殊功能,比如\. “让有含义的符号失去意义”
反斜杠后边跟普通字符实现特殊功能,比如\d “让没有意义的变得有特殊含义”
\d 匹配任何十进制数;它相当于类 [0-9]。
\D 匹配任何非数字字符;它相当于类 [^0-9]。
\s 匹配任何空白字符;它相当于类 [ \t\n\r\f\v]。
\S 匹配任何非空白字符;它相当于类 [^ \t\n\r\f\v]。
\w 匹配任何字母数字字符;它相当于类 [a-z A-Z 0-9 _ ]。
\W 匹配任何非字母数字字符;它相当于类 [^a-z A-Z 0-9 _ ]
\b 匹配一个特殊字符边界,需要结合r使用,比如空格 ,&,#,@,$等
ret=re.findall('[\d]','45bdha3') #不会把连续数字视为一个整体,会拆分成一个个的字符 print(ret) #['4', '5', '3']
ret=re.findall('\d+','45bd123ha3') #不会把连续数字视为一个整体,会拆分成一个个的字符
print(ret) #['45', '123', '3']
#等价于:
ret=re.findall('[0-9]+','45bd123ha3')
#成功:原来的方法实现
ret=re.findall('^I','I am LIST') #匹配大写的I print(ret) #['I']
#失败:
ret=re.findall('I\b','hi I am LIST') #匹配大写的I,发现I前后都是空格 print(ret) #[] 直接这样拿不出来I
#成功
ret=re.findall(r'I\b','I am LIST') #加上r表示raw原生字符串,告诉python解释器不要做任何翻译直接交给re模块,re只有拿到的是没有任何加工过的\b才能正确理解为匹配空白
print(ret) #['I']
#成功:I\\b也表示I和空格
ret=re.findall('I\\b','I am LIST') #匹配大写的I,两个\表示去掉特殊意义,即两个\表示一个普通的\,之后这一个普通的\和b一起传递给python print(ret) #['I']
#失败:
ret=re.findall('c\\f','c\fLIST') #匹配c\f时,在\前再加上一个\,但此时原字符串中本来就有\,此时也行不通 print(ret) #['c\x0c']
#改正成功:
ret= re.findall('c\\\\f','c\fLIST') #如果写两个\python会解析后最终传一个\给re。只有写四个\时,re才会得到python处理后的两个\
print(ret) #['c\\f'] 匹配成功了,解释器显示的时候还是会多加一个\表示转义,实际上就是 c\f 在做匹配
#只想要匹配真实的普通字符 . * re.findall("www.baidu", "wwwgbaidu") #这样也会成功匹配。因为此时条件规则中的点的含义是任意匹配(除\n) re.findall("www\.baidu", "www.baidu") #这样只能匹配www.baidu re.findall("www*baidu", "www*baidu") #这样不能成功匹配。因为此时条件规则中的*的含义是匹配任意个w re.findall("www\*baidu", "www*baidu") #这样才能成功匹配
#-----------------------------eg1: import re ret=re.findall('c\l','abc\le') print(ret)#[] ret=re.findall('c\\l','abc\le') print(ret)#[] ret=re.findall('c\\\\l','abc\le') print(ret)#['c\\l'] ret=re.findall(r'c\\l','abc\le') print(ret)#['c\\l'] #-----------------------------eg2: #之所以选择\b是因为\b在ASCII表中是有意义的 m = re.findall('\bblow', 'blow') print(m) m = re.findall(r'\bblow', 'blow') print(m)

元字符之分组()
m = re.findall(r'(ad)+', 'add') print(m)
#利用search将得到结果分组: ret=re.search('(?P<id>\d{2})/(?P<name>\w{3})','23/com') print(ret.group())#23/com print(ret.group('id'))#23
#管道符表示或 ret=re.findall(r"ka|b","sdjkasf") print(ret) #['ka'] 只找到ka ret=re.findall(r"ka|b","sdjkbsf") print(ret) #['b'] 只找到b ret=re.findall(r"ka|b","sdjka|bsf") print(ret) #['ka','b'] 找到ka 或者 b,都取出来 #待匹配字符串中的管道符不会被匹配,因为规则里的管道符不是普通符号,有特殊含义 ret=re.findall(r"ka|bc","sdjka|bsf") print(ret) #['ka'] 找到ka 或者 bc,都取出来,两个整体进行寻找 ret=re.findall(r"ka|b","sdjka|bcsf") print(ret) #['ka','bc'] 找到ka 或者 bc,都取出来 #小括号进行分组:不加小括号会变成一个个字符 ret=re.findall("(abc)+","abcabcabc") print(ret) #['abc'] 找到ka 或者 b,都取出来 #固定格式 #findall是将所有能匹配到的结果拿出来放入一个列表中,直接就拿到结果了 #search只要匹配到一个满足条件的就不再匹配了,search返回一个对象
# search用途:进行多项式含括号的计算
findall("\([^()]+\)",s) #得到的结果为列表,还需要进一步一个个取出来
search("\([^()]+\)",s) #得到的就是一个结果对象(2-1)
# 之后再用减号做分割得到int处理后的数字2和1,将减法计算后的结果替换掉2-1的表达式
ret=re.findall("(?P<name>\w+)","abcccc") #匹配任意个数的字母,并分组起一个名字 ret=re.search("(?P<name>\[a-z]+)","alex36wusir34xiaolv33") print(ret) #<_sre.SRE_Match object: span=(0,4),match='alex'> print(ret.group()) #'alex' ret=re.search("(?P<name>\[a-z]+)\d+)","alex36wusir34xiaolv33") print(ret.group()) #'alex36' print(ret.group("name")) #'alex' 通过group可以提取分组中某一个属性对应的值 #把年纪也分组: ret=re.search("(?P<name>\[a-z]+)(?P<age>\d+)","alex36wusir34xiaolv33") print(ret.group("age")) #'36' ret=re.search("\d+","sdjk34a|b15sf") print(ret) #<_sre.SRE_Match object: span=(5,7), match='34'> ret=re.search("\d(5)","sdjk34a|b15sf") print(ret) #匹配不成功,什么都不返回 #利用group将匹配成功的数值取出来 ret=re.search("\d+","sdjk34a|b15sf") print(ret.group()) #'34' #只会得到第一个满足条件的34 ret=re.search('(ab)|\d','rabhdg8sd') print(ret.group()) #ab
import re #1 re.findall('a','alvin yuan') #返回所有满足匹配条件的结果,放在列表里 #2 re.search('a','alvin yuan').group() #函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以 # 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 #3 re.match('a','abc').group() #同search,不过尽在字符串开始处进行匹配,也只匹配一次,相当于在search中加上^。也可以和group连用将对应数值取出来 #4以指定字符进行分割,自己不会保留,左边一部分右边一部分。哪边要是没有得到一个空字符,不能省略 ret=re.split('[ab]','abcd') #先按'a'分割得到 ''和'bcd', 在对' '和'bcd'分别按'b'分割得到''和'cd' print(ret)#['', '', 'cd'] #分割后剩下的为空也要打出来 #5 分割 # 参数表(匹配规则,替换字符串,待处理的字符串,匹配次数) # 匹配次数一般不怎么用,一般全部匹配 ret=re.sub('\d','abc','alvin5yuan6',1) print(ret)#alvinabcyuan6 # subn把最终结果组合成一个元祖,元祖中第一个为匹配修改后的结果,第二个为匹配修改字符的个数 ret=re.subn('\d','abc','alvin5yuan6') print(ret) #('alvinabcyuanabc', 2) #6 # 编译:好处:可以用多次,从而提高效率 obj=re.compile('\d{3}') #参数只有规则,返回给对象obj,之后调用方法直接通过obj去调用,且遵循obj已经写好的规则,就不用再写规则了 ret=obj.search('abc123eeee') print(ret.group())#123 #7封装到一个迭代器当中,如果处理结果数据相当多的时候,不会一次性全放在内存里,用一条取一条。处理大数据的时候 ret=re.finditer("\d","abckf5678alvin5909yuan6") print(next(ret).group()) #5 print(next(ret).group()) #6 print(next(ret).group()) #7 print(next(ret).group()) #8 print(next(ret).group()) #5
|
1
2
3
4
5
6
|
import reret=re.finditer('\d','ds3sy4784a')print(ret) #<callable_iterator object at 0x10195f940>print(next(ret).group())print(next(ret).group()) |
注意:
#优先级的问题:只返回分组中内容
import re
print(re.findall("www\.(baidu|163)\.com"',"www.baidu.com")) # ['baidu'] #如果匹配规则中含有分组,findall会优先将分组拿出来,只会显示组里面的内容,不会把完整的内容一起给你
ret=re.findall('www.(baidu|oldboy).com','www.oldboy.com') print(ret)#['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
# 其实数据量很大的时候,我们更关心我们关注的数据会不会被取出来,不需要写完整。所以re才会默认只返回给你分组中内容,但匹配依旧是全部一起匹配。只是返还的时候不全部显示
ret=re.findall('www.(?:baidu|oldboy).com','www.oldboy.com') #取消权限加上?: print(ret)#['www.oldboy.com']
# 优先级:只返回括号中的内容
re.findall("(abc)+","abcabcabc") #['abc']
re.findall("(?:abc)+","abcabcabc") #['abcabcabc'] 这个的结果不会是三个,而是一个整体。只会把连续的abc匹配后连续输出
re.findall("abc+","abcabccabc") #['abc','abcc','abc'] 可以匹配出abc,abcccccc即此法得出的结果中c可以重复
#匹配出所有的整数
import re
#ret=re.findall(r"\d+{0}]","1-2*(60+(-40.35/5)-(-4*3))")
ret=re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))")
ret.remove("")
print(ret)
posted on 2018-04-10 13:01 Josie_chen 阅读(165) 评论(0) 编辑 收藏 举报

