机器学习的安全隐私
转载自:https://www.leiphone.com/news/201706/CrSyyhCUNz2gYIIJ.html
一、怎么样的系统是安全的系统?
如果让 Ian Goodfellow和Nicolas Papernot 给出定义的话,一个可靠的、可以保证像预期那样工作的系统,就是一个安全的系统。
为了达到系统的行为符合预期的目标,设计系统的人心里就需要有一个威胁模型。“威胁模型”是一组经过严格定义的任意一个可能希望“系统异常运作”的攻击者具有的能力和目标的假设。
目前为止,多数的机器学习系统在设计的时候都只对应了一个很弱的威胁模型,可以说这样的模型里是没有什么具体成员的。这样的机器学习系统的设计目标只是为了在给与自然输入的时候能够正常工作。今天的设计者们应当开始设计的系统,需要在面对恶意用户和面对基于机器学习的恶意敌对方的时候还能正常工作。
举例说明,一个人工智能系统在训练时(学习阶段)或者在进行预测时(推理阶段)都有可能被攻击者盯上。攻击者还会有各种不同的能力,其中很有可能包括对模型内部结构和参数,或者对模型输入输出的更改权限。
二、攻击者能造成哪些危害?
攻击者的攻击可以影响系统的保密性(confidentiality)、完整性(integrity)和可用性(availability),三者可以合称为安全领域的“CIA模型”。
-
保密性:机器学习系统必须保证未得到授权的用户无法接触到信息。在实际操作中,把保密性作为隐私性来考虑会容易得多,就是说模型不可以泄露敏感数据。比如假设研究员们设计了一个可以检查病人病历、给病人做诊断的机器学习模型,这样的模型可以对医生的工作起到很大的帮助,但是必须要保证持有恶意的人没办法分析这个模型,也没办法把用来训练模型的病人数据恢复出来。
-
完整性:如果攻击者可以破坏模型的完整性,那么模型的预测结果就可能会偏离预期。比如垃圾邮件会把自己伪装成正常邮件的样子,造成垃圾邮件识别器的误识别。
-
可用性:系统的可用性也可以成为攻击目标。比如,如果攻击者把一个非常难以识别的东西放在车辆会经过的路边,就有可能迫使一辆自动驾驶汽车进入安全保护模式,然后停车在路边。
虽然目前研究者们还没有展示很多成功进行攻击的案例,但是 Ian Goodfellow和Nicolas Papernot 表示 未在来的博文中会逐渐做更多介绍。
目前已经可以明确表述的攻击方式有三种:在训练时对模型进行完整性攻击,在推理时进行完整性攻击,以及隐私攻击
三、在训练集中下毒 - 在训练时对模型进行完整性攻击
攻击者可以通过修改现有训练数据、或者给训练集增加额外数据的方法来对训练过程的完整性造成影响。比如假设莫里亚蒂教授要给福尔摩斯栽赃一个罪名,他就可以让一个没被怀疑的同伙送给福尔摩斯一双独特、华丽的靴子。当福尔摩斯穿着这双靴子在他经常协助破案的警察面前出现过以后,这些警察就会把这双靴子和他联系起来。接下来莫里亚蒂教授就可以穿一双同样的靴子去犯罪,留下的脚印会让福尔摩斯成为被怀疑的对象。
干扰机器学习模型的训练过程,体现的攻击策略是当用于生产时让机器学习模型出现更多错误预测。具体来说,这样的方法可以在支持向量机(SVM)的训练集中下毒。由于算法中预测误差是以损失函数的凸点衡量的,这就让攻击者有机会找到对推理表现影响最大的一组点进行攻击。即便在更复杂的模型中也有可能找到高效的攻击点,深度神经网络就是这样,只要它们会用到凸优化。
四、用对抗性的样本让模型出错 - 在推理时进行完整性攻击
实际上,让模型出错是非常简单的一件事情,以至于攻击者都没必要花功夫在训练机器学习模型参数的训练集中下毒。他们只要在推理阶段(模型训练完成之后)的输入上动动手脚,就可以立即让模型得出错误的结果。
要找到能让模型做出错误预测的干扰,有一种常用方法是计算对抗性样本。它们带有的干扰通常很微小,人类很难发现,但它们却能成功地让模型产生错误的预测。比如下面这张图,用机器学习模型识别最左侧的图像,可以正确识别出来这是一只熊猫。但是对这张图像增加了中间所示的噪声之后得到的右侧图像,就会被模型识别成一只长臂猿(而且置信度还非常高)。
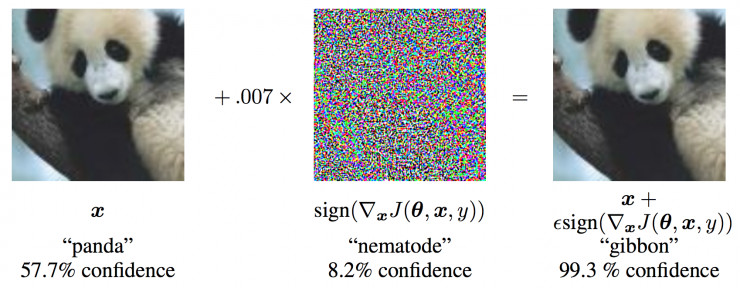
值得注意的是,虽然人类无法用肉眼分辨,但是图像中施加的干扰已经足以改变模型的预测结果。确实,这种干扰是在输入领域中通过计算最小的特定模得到的,同时它还能增大模型的预测误差。它可以有效地把本来可以正确分类的图像移过模型判定区域的边界,从而成为另一种分类。下面这张图就是对于能分出两个类别的分类器,出现这种现象时候的示意。
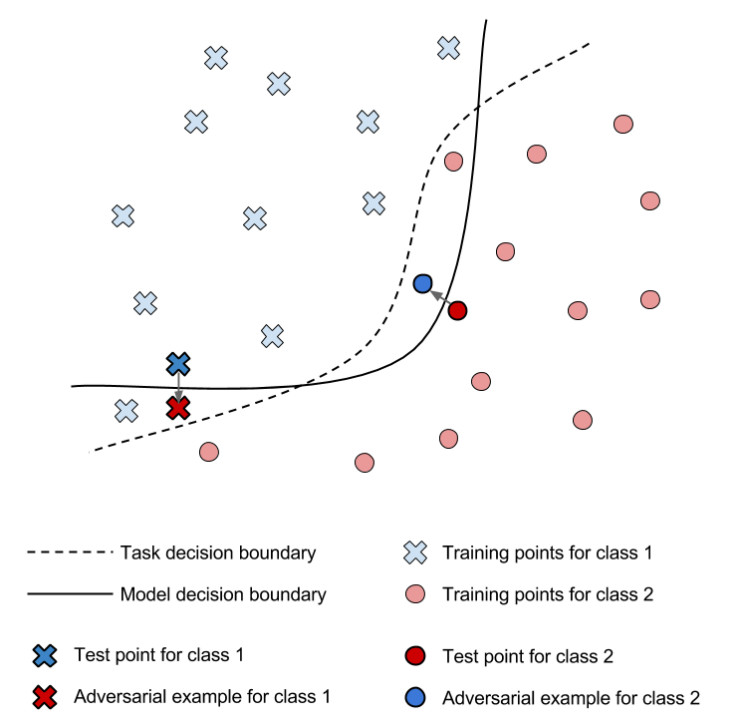
许多基于对抗性样本的攻击需要攻击者知道机器学习模型中的参数,才能把所需的干扰看作一个优化问题计算出来 。另一方面,也有一些后续研究考虑了更现实的威胁模型,这种模型里攻击者只能跟模型互动,给模型提供输入以后观察它的输出。举例来讲,这种状况可以发生在攻击者想要设计出能骗过机器学习评分系统从而得到高排名的网站页面,或者设计出能骗过垃圾邮件筛选器的垃圾邮件的时候。在这些黑盒情境中,机器学习模型的工作方式可以说像神谕一样。发起攻击的策略首先对神谕发起询问,对模型的判定区域边界做出一个估计。这样的估计就成为了一个替代模型,然后利用这个替代模型来制作会被真正的模型分类错误的对抗性样本。这样的攻击也展现出了对抗性样本的可迁移性:用来解决同样的机器学习任务的不同的模型,即便模型与模型之间的架构或者训练数据不一样,对抗性样本还是会被不同的模型同时误判。
五、机器学习中的隐私问题
机器学习中的隐私问题就不需要攻击者也能讲明白了。例如说,机器学习算法缺乏公平性和透明性的问题已经引起领域内越来越多人的担心。事实上,已经有人指出,训练数据中带有的社会偏见会导致最终训练完成后的预测模型也带有这些偏见。下面重点说一说在有攻击者情况下的隐私问题。
攻击者的目的通常是恢复一部分训练机器学习模型所用的数据,或者通过观察模型的预测来推断用户的某些敏感信息。举例来说,智能手机的虚拟键盘就可以通过学习用户的输入习惯,达到更好的预测-自动完成效果。但是,某一个用户的输入习惯下的特定字符序列不应该也出现在别的手机屏幕上,除非已经有一个比例足够大的用户群也会打同样的一串字符。在这样的情况下,隐私攻击会主要在推理阶段发挥作用,不过要缓解这个问题的话,一般都需要在学习算法中增加一些随机性。
比如,攻击者有可能会想办法进行成员推测查询:想要知道模型训练中有没有使用某个特定的训练点。近期就有一篇论文在深度神经网络场景下详细讨论了这个问题。与制作对抗性样本时对梯度的用法相反(这可以改变模型对正确答案的置信度),成员推测攻击会沿着梯度方向寻找分类置信度非常高的点。已经部署的模型中也还可以获得有关训练数据的更多总体统计信息。
六、提高机器学习模型鲁棒性的方法
Ian Goodfellow和Nicolas Papernot 两人已经一起试过几个方法,为了提高机器学习模型面对对抗性样本时鲁棒性。
-
对抗性训练(Adversarial training):对抗性训练的目标是提高模型的泛化能力,让模型在测试中遇到对抗性样本的时候有更好的表现。做法是在模型的训练阶段就主动生成对抗性样本,把它们作为训练过程的一部分。这个想法最初是由Szegedy提出的,但是可实施性很低,因为生成对抗性样本需要的计算成本太高。Goodfellow展示过一种用快速梯度标志的方法,可以低成本地生成对抗性样本,计算效率已经足以生成大批量的对抗性样本用于模型训练。这样训练出的模型对原样本和对抗性样本的分类结果就是相同的。比如可以拍一张猫的照片,然后对抗性地进行干扰,让一般的模型照片识别成一只秃鹫,然后就告诉要训练的这个模型干扰后的照片还是一只猫。
-
防御性蒸馏(Defensive distillation):攻击者可能会利用模型判定区域的对抗方向发起攻击,防御性蒸馏就可以让这些方向变得更平滑。蒸馏(distillation)是一种训练方法,它要训练一个模型,让这个模型预测更早训练的另一个模型的可能输出结果。蒸馏的方法最初是由Hinton提出的,这个方法当时的目标是用一个小模型模仿大型的、计算量大的模型得到相似的结果。防御性蒸馏的目标有所区别,它只是为了让最终模型的输出更平滑,所以即便模仿的和被模仿的两个模型大小一样也没关系。不过这种方法有点反直觉,有两个同样架构的模型,然后训练其中一个预测另一个的输出结果。但是这种方法能奏效的原因是,先训练的那个模型(被模仿的)是用“绝对”标签训练的(可以100%确定图像是狗,不是猫),然后它提供的用来训练后一个模型的标签就是“相对”的(比如95%的确定性认为图像更可能是狗)。这第二个蒸馏后的模型的鲁棒性就高得多,对快速梯度标志方法或者Jacobian的显着图方法这样的攻击的抵抗力高不少。
为什么防御对抗性样本很难?
对抗性样本防御起来很难是因为很难对对抗性样本的制作过程建立理论模型。对包括神经网络在内的许多机器学习模型而言,对抗性样本是优化问题的非线性、非凸性的解。因为没有什么好的理论工具可以描述这些复杂优化问题的解,所以也就很难提出能够对付对抗性样本的增强理论作为防御方法。
换个角度看,对抗性样本很难防御也因为它们要求机器学习模型对每一种可能的输入都要给出好的结果。多数时候机器学习模型都能很好地工作,但是对所有可能的输入而言,它们实际会遇到的输入只是很小的一部分。就是因为可能的输入是海量的,设计一个真正有适应性的防御方法就很难。
Ian Goodfellow和Nicolas Papernot两人的心里话
两人在2016年底就已经发现了许多可以对机器学习模型进行攻击的方法,但是防御的方法几乎看不到。他们希望在2017年底能够看到一些高效的防御方法。他们博客的目的就是推动机器学习安全和隐私方面的前沿发展,方法就是把最新的进展记录下来、在相关话题的研究社区中引发讨论、以及启发新一代的研究者们加入这个社区。
对对抗性样本的研究很令两人兴奋,因为很多重要问题都还没有得到定论,理论方面和应用方面都是。从理论角度,没人知道想防御对抗性样本的攻击是不是徒劳(就像想要发现一种通用的机器学习算法那样),或者能够找到一种最佳的策略让防御者占得先机(像加密学和差分隐私那样)。从应用角度,还没人设计出来过强大到能够抵抗多种不同对抗性样本攻击的防御算法。Ian Goodfellow和Nicolas Papernot两人更希望读者们阅读文章以后可以得到灵感,一起来解决其中的一些问题。
posted on 2018-11-26 16:31 Josie_chen 阅读(322) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号